一眼看懂
封面预览
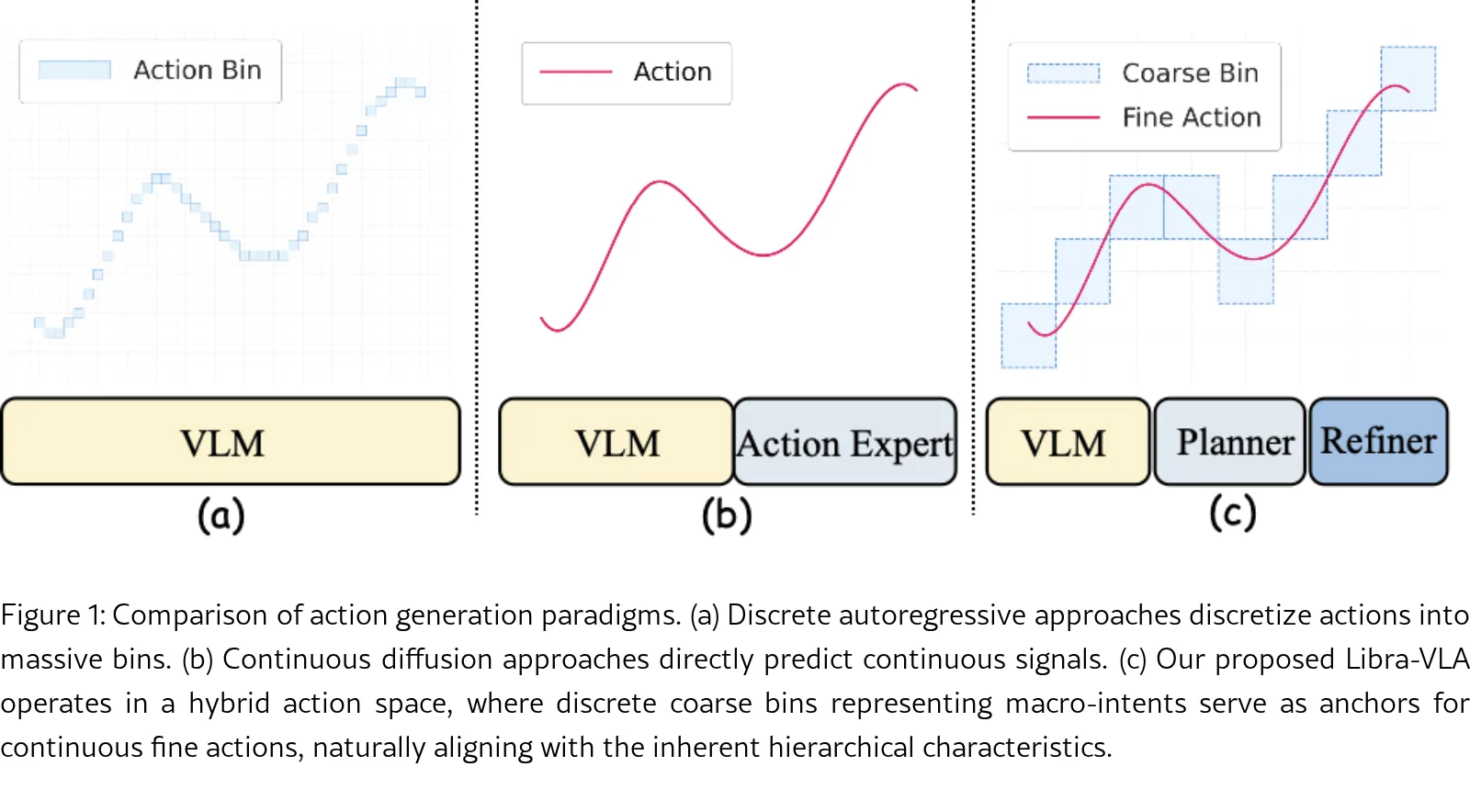
论文提出了Libra-VLA,一种基于异步从粗到细双系统的视觉-语言-动作(VLA)模型架构,旨在解决机器人操作任务中的学习均衡问题。
- 论文提出了Libra-VLA,一种基于异步从粗到细双系统的视觉-语言-动作(VLA)模型架构,旨在解决机器人操作任务中的学习均衡问题。
- 核心目标是弥合现有单体VLA模型中,高级语义指令直接映射至低级高频运动命令所产生的语义-执行差距。
- 通过将动作生成解耦为离散的宏观方向规划与连续的微观姿态精修,降低了单一模型的表示负担,并实现了高效、鲁棒的异步执行。
Card 01
研究单位
研究单位
- 北京航空航天大学(Beihang University)
- 智元机器人(AgiBot)
Card 02
论文概述
论文概述
- 论文提出了Libra-VLA,一种基于异步从粗到细双系统的视觉-语言-动作(VLA)模型架构,旨在解决机器人操作任务中的学习均衡问题。
- 核心目标是弥合现有单体VLA模型中,高级语义指令直接映射至低级高频运动命令所产生的语义-执行差距。
- 通过将动作生成解耦为离散的宏观方向规划与连续的微观姿态精修,降低了单一模型的表示负担,并实现了高效、鲁棒的异步执行。
Card 03
核心贡献
核心贡献
- 提出了基于混合动作空间的从粗到细VLA新范式,并发现了学习复杂度均分原则,证明了模型性能随动作分解粒度呈倒U型曲线,峰值出现在两个子系统学习难度平衡时。
- 设计并实现了一个解耦的异步双系统架构,其中Semantic Planner低频运行以提供稳定的离散规划,Action Refiner高频运行以实现实时的连续控制。
- 开发了Libra-VLA模型,在仿真基准和真实世界实验中,相较于现有方法取得了更高的任务成功率与更低的推理延迟。
Card 04
方法描述
方法描述
- 将动作生成建模于混合动作空间,分解为离散的语义宏观意图和连续的几何微观对齐。
- System 2 (Semantic Planner):基于VLM主干网络,配合并行粗动作头,预测离散的宏观方向意图,作为几何锚点。
- System 1 (Action Refiner):采用扩散Transformer,配备独立的视觉编码器,以粗意图为条件生成高精度连续动作。
- 引入异步执行策略,通过意图缓冲区连接两个系统,允许规划器一次推理生成多步粗意图,供执行器迭代使用,实现频率解耦。
Card 05
数据集与资源
数据集与资源
- 主要仿真基准:LIBERO(标准能力评估)和LIBERO-Plus(深入鲁棒性分析)。
- 进行了真实世界机器人操作实验。
- 模型初始化基于InternVL2.5-2B,所有实验均未使用大规模机器人数据预训练。
- 训练资源等信息在附录中详述。
Card 06
评估与结果
评估与结果
- 评估环境包括LIBERO基准的四个任务套件和LIBERO-Plus的七种扰动维度。
- 主要评估指标为任务成功率。
- 关键结果:
- 在LIBERO基准上,Libra-VLA达到97.2%的平均成功率,创下新记录,并在精度关键和长时序任务上表现优异。
- 在LIBERO-Plus零样本迁移设置下达到79.5%平均成功率,在监督微调设置下达到82.3%,均达到最佳性能。
- 消融实验验证了各组件有效性、最佳粗动作粒度(N=10)以及动态课程训练策略的优越性。