一眼看懂
封面预览
提出了一种新的视觉-语言-动作(VLA)模型架构 ResVLA,旨在解决现有生成式 VLA 模型在训练效率、条件对齐及语义漂移方面的根本性缺陷。
- 提出了一种新的视觉-语言-动作(VLA)模型架构 ResVLA,旨在解决现有生成式 VLA 模型在训练效率、条件对齐及语义漂移方面的根本性缺陷。
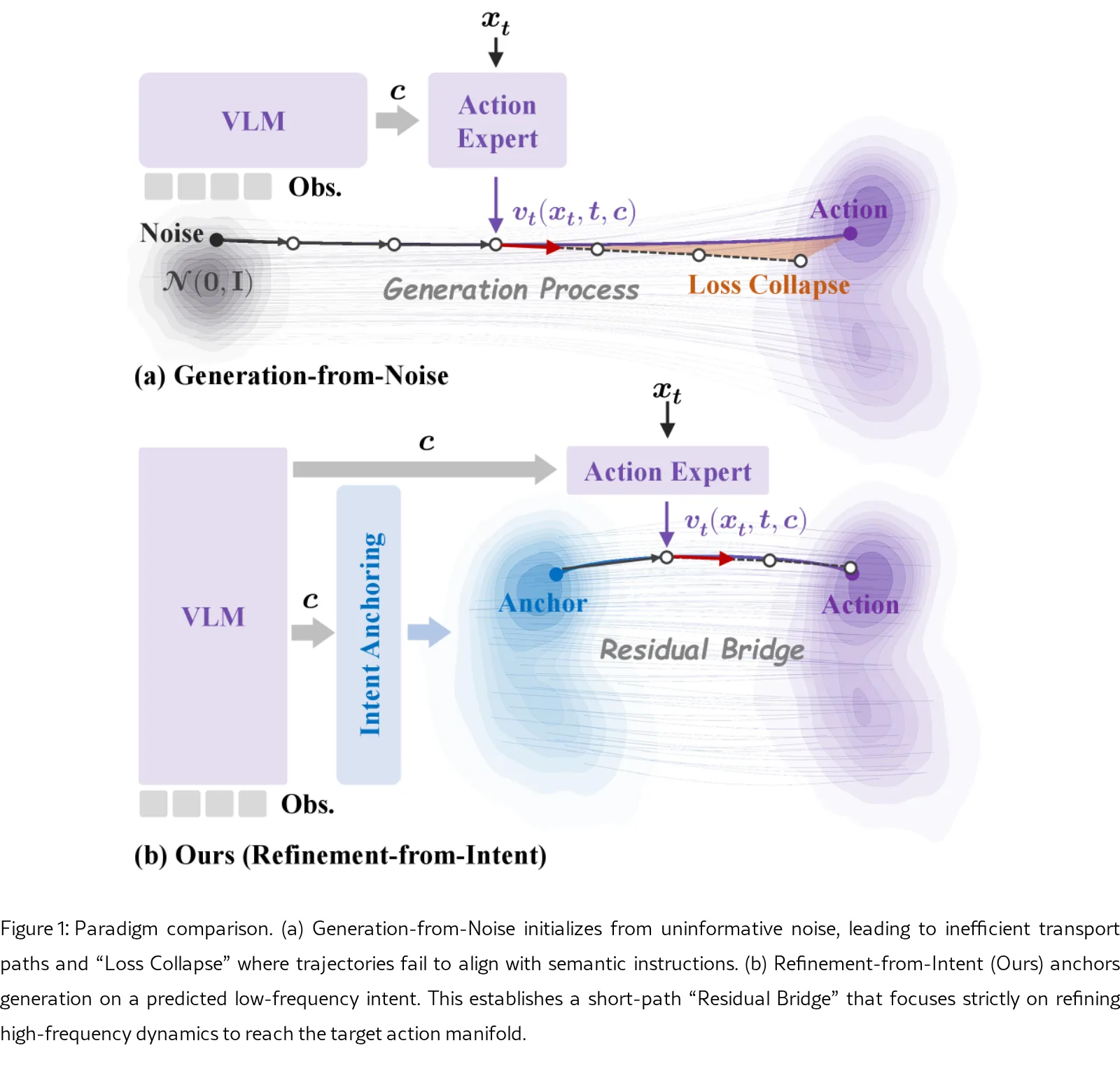
- 核心思想是将机器人控制范式从传统的“从噪声生成”转变为“从意图细化”,通过频谱分析将动作解耦为确定性的低频全局意图和随机性的高频局部动态。
- 论文旨在通过引入基于意图锚定的残差扩散桥,解决高级语义理解与低级物理控制之间的时空尺度不匹配问题,实现更高效、鲁棒的机器人策略学习。
Card 01
研究单位
研究单位
- 论文原文中未明确列出作者所属的具体研究机构信息。
Card 02
论文概述
论文概述
- 提出了一种新的视觉-语言-动作(VLA)模型架构 ResVLA,旨在解决现有生成式 VLA 模型在训练效率、条件对齐及语义漂移方面的根本性缺陷。
- 核心思想是将机器人控制范式从传统的“从噪声生成”转变为“从意图细化”,通过频谱分析将动作解耦为确定性的低频全局意图和随机性的高频局部动态。
- 论文旨在通过引入基于意图锚定的残差扩散桥,解决高级语义理解与低级物理控制之间的时空尺度不匹配问题,实现更高效、鲁棒的机器人策略学习。
Card 03
核心贡献
核心贡献
- 识别并分析了现有生成式 VLA 模型中“源条件独立”导致训练效率低下和“损失坍塌”现象的理论根源,提出最大化源分布与任务条件之间互信息的解决思路。
- 提出了 ResVLA 架构,通过频谱正交性融合确定性回归与生成式流匹配,利用条件依赖的低频意图锚定生成过程,实现了全局语义对齐与局部动态保真度的统一。
- 通过广泛的模拟与真实世界实验验证,ResVLA 在长视界任务鲁棒性、接触密集型操作性能上表现优异,且训练收敛速度与推理效率均显著优于标准扩散策略基线。
Card 04
方法描述
方法描述
- 采用 频谱分析 方法,利用离散余弦变换(DCT)将动作空间分解为语义子空间(低频全局轨迹)和执行子空间(高频细节抖动)。
- 设计了 意图锚定模块,使用 VLM 特征直接回归低频语义意图,构建一个与任务条件强相关的源分布,作为扩散过程的起点。
- 基于此锚定源,使用 残差扩散桥 和 流匹配 技术学习仅针对高频残差的传输路径,将生成任务转化为高效的局部动力学修正问题,大幅缩短了生成路径。
Card 05
数据集与资源
数据集与资源
- 评估数据集包括:LIBERO、LIBERO-Plus、SimplerEnv 以及真实世界的 ALOHA 双臂操作平台。
- 论文明确指出,其评估模型是在这些数据集上 从头训练 的,未使用任何预训练模型。
- 原文未提及具体的模型参数规模或训练所用的 GPU/TPU 等硬件资源详情。
Card 06
评估与结果
评估与结果
- 评估基准:涵盖长视界规划、空间推理、接触密集型操作及跨具身泛化等多个挑战性场景。
- 主要评估指标:任务 成功率、学习效率(相同训练步数下的性能)、推理效率(性能与函数评估次数 NFE 的权衡)。
- 关键实验结果:在 LIBERO-Plus 鲁棒性测试中,ResVLA 对语言指令变化、机器人具身扰动及场景布局变化表现出极强的抵抗力,成功率显著领先基线(如 π₀);在 LIBERO 主基准上达到竞争性性能;同时,ResVLA 训练收敛更快,且在极低 NFE(如 1 步)下即可获得高成功率,验证了其推理效率优势。