一眼看懂
封面预览
论文针对杂乱环境下的多机器人控制问题,提出了一个名为 WayPlan 的混合控制框架,旨在联合优化高层任务规划和底层运动规划。
- 论文针对杂乱环境下的多机器人控制问题,提出了一个名为 WayPlan 的混合控制框架,旨在联合优化高层任务规划和底层运动规划。
- 研究核心在于解决任务与运动规划之间的耦合难题,特别是运动轨迹参数化困难和信用分配模糊的问题。
- 通过引入 Waypoints(航点)作为中间表示,并设计课程学习策略,实现了在密集障碍物环境中的高效多机器人协同。
Card 01
研究单位
研究单位
- UC Santa Barbara
- Massachusetts Institute of Technology
- Harvard University
- MIT-IBM Watson AI Lab
- Cisco Research
Card 02
论文概述
论文概述
- 论文针对杂乱环境下的多机器人控制问题,提出了一个名为 WayPlan 的混合控制框架,旨在联合优化高层任务规划和底层运动规划。
- 研究核心在于解决任务与运动规划之间的耦合难题,特别是运动轨迹参数化困难和信用分配模糊的问题。
- 通过引入 Waypoints(航点)作为中间表示,并设计课程学习策略,实现了在密集障碍物环境中的高效多机器人协同。
Card 03
核心贡献
核心贡献
- 提出了新的多机器人基准数据集 BoxNet3D-OBS,包含密集障碍物和多达 9 个机器人,模拟了真实的仓库杂乱场景。
- 设计了 WayPlan 双层规划框架,显式地将高层任务决策与底层运动可行性相结合。
- 开发了三阶段课程训练策略及改进的 RLVR 算法,解决了任务规划器和运动规划器联合优化时的信用分配挑战。
- 验证了基于航点的运动规划方法在相似数据预算下优于 VLA(Vision-Language-Action)式运动规划方法。
Card 04
方法描述
方法描述
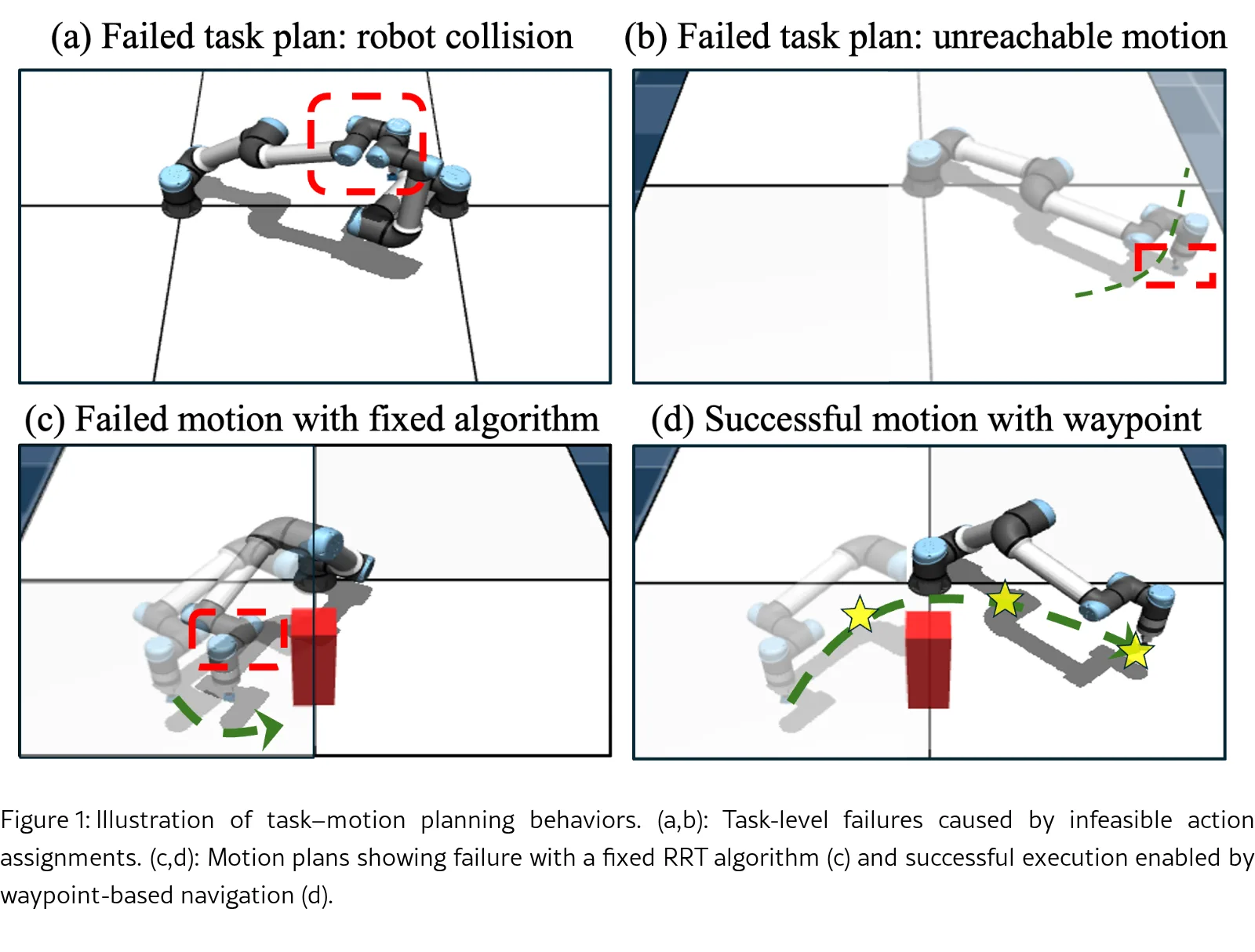
- 框架包含两个基于 LLM 的规划器:任务规划器 负责生成长周期的动作序列,运动规划器 负责生成障碍物感知的 Waypoints 航点序列。
- 运动规划器生成的航点通过经典算法(如 RRT)转换为可执行的机器人姿态轨迹,从而降低了学习维度和难度。
- 采用三阶段训练流程:Stage 1 进行监督微调(SFT)预热,使用反思增强的推理轨迹数据;Stage 2 分别独立训练两个规划器;Stage 3 进行联合 RLVR 训练,引入运动可行性惩罚反馈以优化任务规划器。
Card 05
数据集与资源
数据集与资源
- 自建数据集 BoxNet3D-OBS,包含 3400 个训练环境和 480 个测试环境。
- 模型基于 Qwen3-4B 进行初始化和微调,并在实验中超越了 GPT-5 和 Gemini3-Pro 等更大规模的模型。
- 训练使用了 8 NVIDIA H100 GPUs,基于 VeRL 框架实现。
Card 06
评估与结果
评估与结果
- 评估基准为 BoxNet3D-OBS,对比了无运动感知的 LLM 任务规划器及 VLA 运动规划器。
- 主要评估指标为任务成功率(Success)和计划步数差异(StepDiff.)。
- 实验结果显示,经过联合训练的 NC-Replan-S3 模型(4B 参数)配合航点规划器达到了 0.62 的成功率,显著优于 GPT-5(0.14)。
- 航点运动规划器在单机器人测试中达到 0.92 成功率,优于 VLA 规划器的 0.78,且有效减少了无效轨迹错误。