一眼看懂
封面预览
论文提出了 PokéVLA,一个轻量级但强大的具身操控基础模型,旨在解决现有视觉-语言-动作(VLA)模型效率低、缺乏高级知识和空间感知能力的…
- 论文提出了 PokéVLA,一个轻量级但强大的具身操控基础模型,旨在解决现有视觉-语言-动作(VLA)模型效率低、缺乏高级知识和空间感知能力的…
- 核心框架采用两阶段训练范式:第一阶段在精心策划的多模态数据集上预训练紧凑的视觉语言模型(PokeVLM);第二阶段通过多视图目标感知语义学习、…
- 论文目标是通过引入具身先验知识和操控相关表示学习,构建一个既轻量高效、又具备丰富空间和目标感知能力的机器人操控模型。
Card 01
研究单位
研究单位
- CASIA (中国科学院自动化研究所)
- TARS Robotics
- 清华大学
- 复旦大学
- 新加坡国立大学
- 同济大学
Card 02
论文概述
论文概述
- 论文提出了 PokéVLA,一个轻量级但强大的具身操控基础模型,旨在解决现有视觉-语言-动作(VLA)模型效率低、缺乏高级知识和空间感知能力的问题。
- 核心框架采用两阶段训练范式:第一阶段在精心策划的多模态数据集上预训练紧凑的视觉语言模型(PokeVLM);第二阶段通过多视图目标感知语义学习、几何对齐和新颖的动作专家,将操控相关表示注入动作空间。
- 论文目标是通过引入具身先验知识和操控相关表示学习,构建一个既轻量高效、又具备丰富空间和目标感知能力的机器人操控模型。
Card 03
核心贡献
核心贡献
- 收集并策划了包含约 2.4M 样本的大规模具身多模态数据集,用于预训练微型具身视觉语言模型,使其获得丰富的操控先验知识同时保留通用视觉语言能力。
- 提出了一种学习操控相关表示的新方法,包括多视图一致的操控目标学习和几何对齐,并设计了一个新颖的动作头以高效地将这些表示注入动作学习过程。
- 在仿真基准(LIBERO-Plus)和真实世界部署中进行了广泛实验,验证了方法在成功率和扰动鲁棒性方面的优越性能,超越了同规模基线模型。
- 开源了代码、模型权重及预训练数据集构建脚本,以促进可复现性和社区进展。
Card 04
方法描述
方法描述
- 采用两阶段训练框架。第一阶段基于 Prismatic-VLM 框架预训练 PokeVLM,使用 Qwen2.5-0.5B 语言模型和 DINO-SigLIP 双视觉编码器,在多模态具身数据上进行训练。
- 第二阶段(VL-Action 后训练)引入三个关键创新:(1) 目标感知操控:通过学习特殊 token
生成多视图一致的语义分割掩码,引导模型关注操控目标;(2) 几何对齐:利用基础模型 VGGT 仅在训练阶段进行隐式空间表示对齐,将几何知识蒸馏进模型;(3) 动作头设计:使用交叉注意力机制,让动作查询聚合视觉特征、语言指令、机器人状态和语义分割嵌入,从而预测动作序列。 - 整体训练目标包含动作预测损失、分割损失和几何对齐损失,通过加权组合优化模型。
Card 05
数据集与资源
数据集与资源
- 预训练数据集:包含四类任务(通用理解、空间定位、功能预测、具身推理),总计约 2.4M 样本。具体数据集包括 LLaVA-Instruct-665K、Refspatial、RoboPoint、Robospatial、HOVA-500K 等。
- 模型规模:基于 Qwen2.5-0.5B 语言模型,总参数量为 1.22B,属于“口袋尺寸”的轻量级模型。
- 训练资源:VLM 预训练在 8 GPU 上进行,有效批大小为 128;后训练阶段同样在 8 GPU 上进行,有效批大小为 64,采用 LoRA 方案进行优化。
Card 06
评估与结果
评估与结果
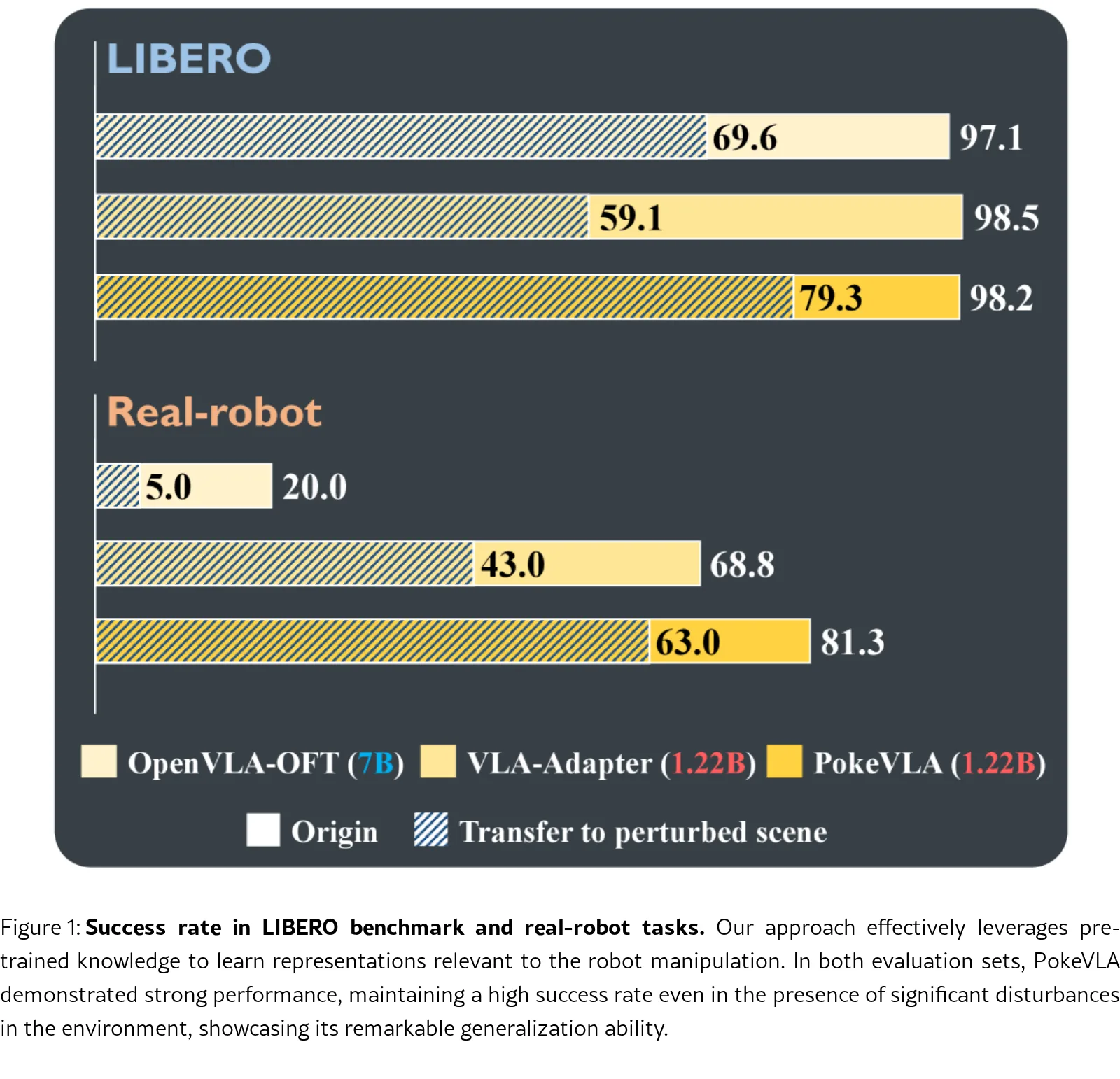
- 评估环境:仿真基准 LIBERO 和更具挑战性的 LIBERO-Plus,以及真实机器人实验环境。LIBERO-Plus 包含七种扰动类型以测试鲁棒性。
- 主要指标:任务成功率(%)。
- 关键结果:
- 在 LIBERO 基准上,PokeVLA 以 1.22B 参数量达到 98.2% 的总成功率,匹配最强并发方法表现,显著优于早期更大规模模型。
- 在 LIBERO-Plus 基准上,直接训练模型达到 83.5% 总成功率(SOTA);直接迁移实验(仅用 LIBERO 数据训练)中达到 79.3%,显著超越最强基线 OpenVLA-OFT(69.6%)。
- 真实世界实验中,在涉及空间和颜色指代任务上,成功率比基线方法提高 12.5%;在引入扰动后,性能差距扩大至 20.0%,显示出更强的鲁棒性。
- 消融实验验证了预训练数据、目标感知分割和几何对齐模块的有效性和必要性。