一眼看懂
封面预览
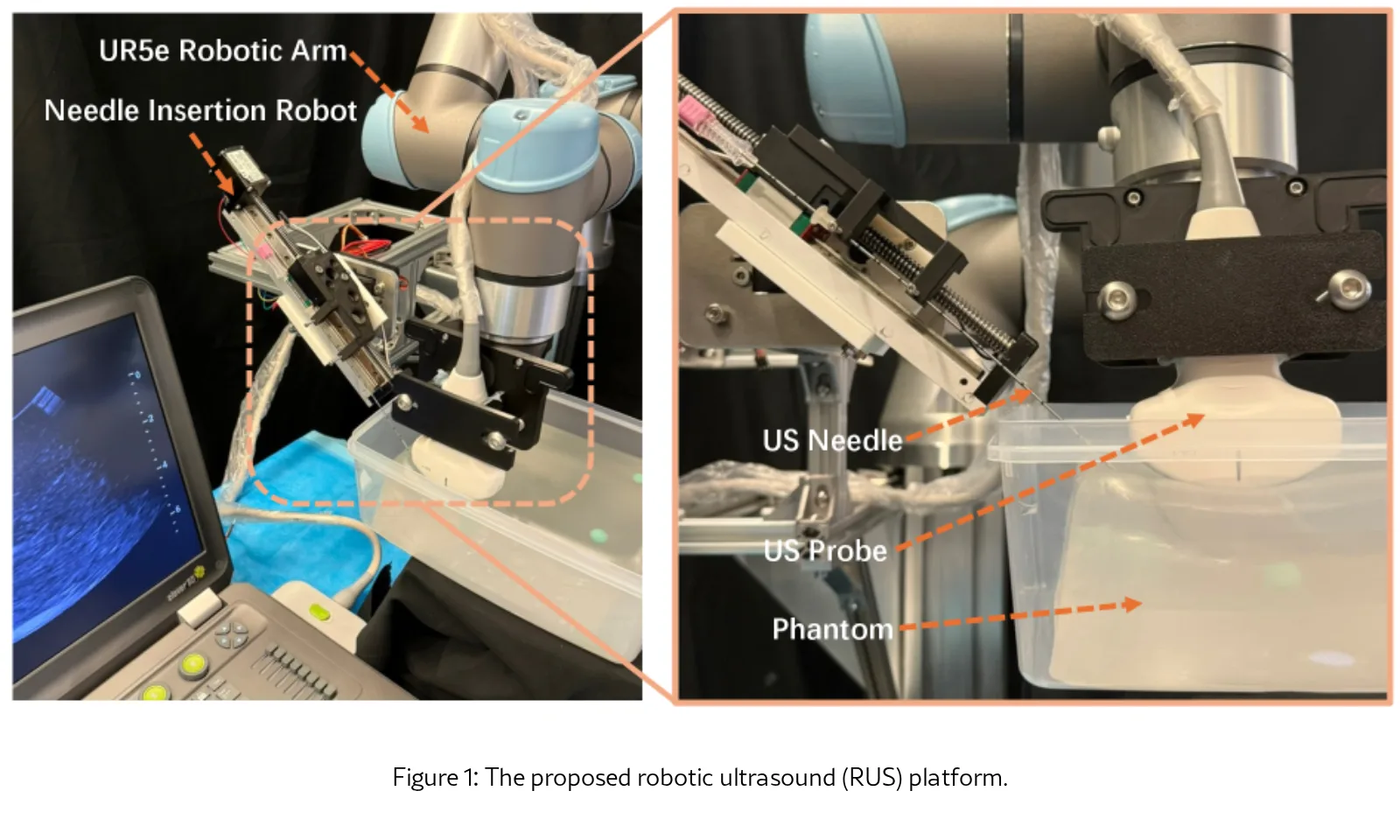
提出一个视觉-语言-动作(VLA)模型,用于在机器人超声(RUS)系统上实现自适应、自动化的超声引导针头插入与追踪
- 提出一个视觉-语言-动作(VLA)模型,用于在机器人超声(RUS)系统上实现自适应、自动化的超声引导针头插入与追踪
- 核心目标是解决超声引导针头插入中因动态成像条件和针头可视化困难导致的挑战
- 提供一个统一的针头追踪与针头插入控制框架,实现基于实时针头位置和环境感知的动态自适应调整
Card 01
研究单位
研究单位
- 香港中文大学 机械与自动化工程系、T Stone机器人研究所、顺兴先进工程研究所、多尺度医疗机器人中心、医学智能与XR研究所
- 香港科技大学 计算机科学与工程系
- 清华大学 深圳国际研究生院
Card 02
论文概述
论文概述
- 提出一个视觉-语言-动作(VLA)模型,用于在机器人超声(RUS)系统上实现自适应、自动化的超声引导针头插入与追踪
- 核心目标是解决超声引导针头插入中因动态成像条件和针头可视化困难导致的挑战
- 提供一个统一的针头追踪与针头插入控制框架,实现基于实时针头位置和环境感知的动态自适应调整
Card 03
核心贡献
核心贡献
- 提出跨深度融合(CDF)追踪头,集成来自大规模视觉骨干网络的浅层位置特征和深层语义特征,实现实时、端到端的针头追踪
- 引入追踪条件(TraCon)寄存器,作为一种轻量级可学习令牌,实现参数高效的视觉骨干网络适应,促进追踪导向的条件化
- 实现不确定性感知控制策略,在成像伪影和过程不确定性下确保程序安全与成功
- 提出异步VLA管道,解耦视觉分析与动作生成,同时确保实时针头追踪(约25 FPS)和精确插入控制(约10 FPS)
Card 04
方法描述
方法描述
- 基于Qwen2.5-VL-3B模型构建VLA框架,包含预训练的视觉编码器、预训练的LLM和专用的CDF追踪头
- CDF追踪头通过跨深度语义融合和位置关联模块,利用ViT编码器的多层级特征进行目标定位
- TraCon寄存器通过条件特征门控机制,动态调制视觉特征,实现任务特定细化
- 采用两阶段训练:第一阶段训练CDF头和TraCon寄存器(冻结其他模块);第二阶段使用LoRA微调LLM和MLP对齐器
Card 05
数据集与资源
数据集与资源
- 针头追踪数据集(D1):包含41,075帧,来自239个视频,由105次平面内静态(IPS)和134次平面内移动(IPM)试验采集,分辨率1920x1080,使用光学追踪器提供真值
- 针头插入数据集(D2):包含3,852帧,来自18个视频,由9次IPS和9次IPM专家演示试验采集,记录语言指令和动作真值
- 模型基于Qwen2.5-VL-3B,骨干网络参数约3B,TraCon寄存器仅0.5M参数
- 训练与评估使用双NVIDIA A800 GPU
Card 06
评估与结果
评估与结果
- 针头追踪评估:在D1测试集上,方法在AUC、精度、误差和标准差上均优于SOTA追踪器(如MixFormer、LoRAT等),平均误差改善10.7%,标准差改善16.0%
- 针头插入评估:与手动操作相比,提出的VLA框架成功率提升33.3%(平均达80.0%),时间消耗更少;IPM试验成功率提升达63.6%,平均时间减少7.1秒
- 消融研究:验证了TraCon寄存器、CDF融合、异步管道和不确定性控制策略的有效性,移除任一组件均导致性能显著下降