一眼看懂
封面预览
提出 OneDrive,首个基于预训练视觉-语言模型(VLM)的统一多范式自动驾驶框架,在单一Transformer解码器内同时支持自回归文本…
- 提出 OneDrive,首个基于预训练视觉-语言模型(VLM)的统一多范式自动驾驶框架,在单一Transformer解码器内同时支持自回归文本…
- 解决现有VLA(Vision-Language-Action)模型在自动驾驶中面临的架构碎片化问题:传统方法使用分离或级联解码器导致预训练权重…
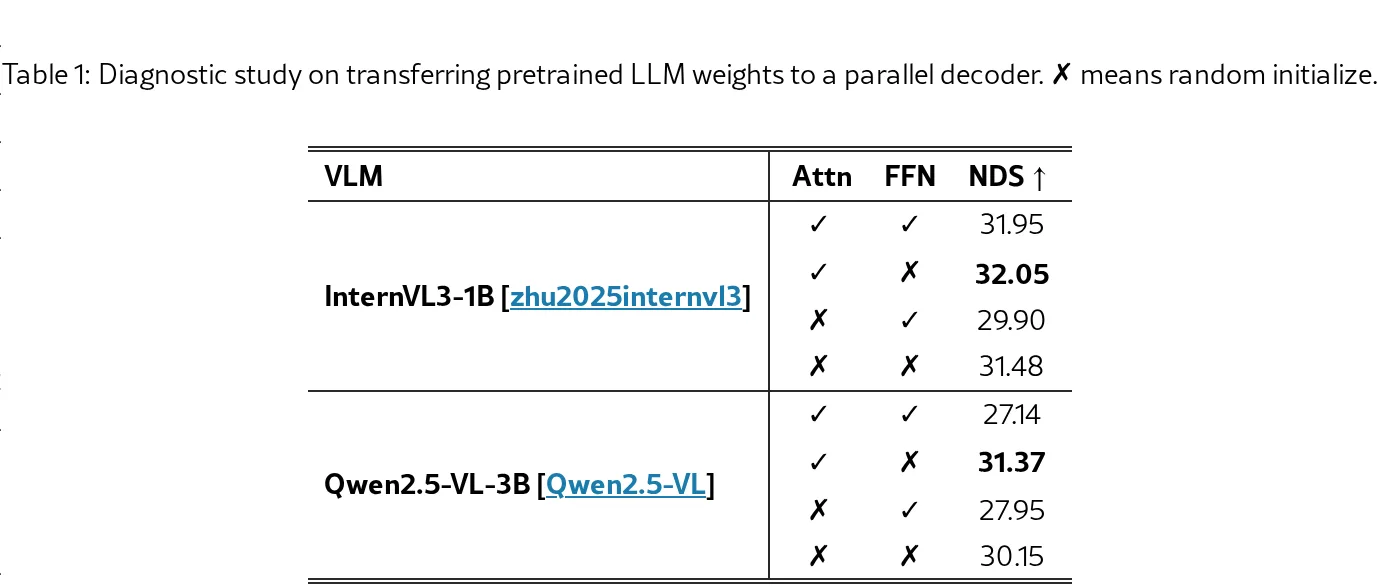
- 揭示预训练VLM的因果注意力机制具有强迁移能力,可适配查询-视觉关系建模,而前馈网络(FFN)难以迁移,为统一架构设计提供关键洞察
Card 01
研究单位
研究单位
- State Key Laboratory of Multimodal Artificial Intelligence Systems, CASIA(中国科学院自动化研究所多模态人工智能系统全国重点实验室)
- School of Artificial Intelligence, University of Chinese Academy of Sciences(中国科学院大学人工智能学院)
- AutoLab, School of Artificial Intelligence, Shanghai Jiao Tong University(上海交通大学人工智能学院AutoLab)
- Voyager Research, Didi Chuxing(滴滴出行Voyager Research)
- School of Information Science and Technology, ShanghaiTech University(上海科技大学信息科学与技术学院)
Card 02
论文概述
论文概述
- 提出 OneDrive,首个基于预训练视觉-语言模型(VLM)的统一多范式自动驾驶框架,在单一Transformer解码器内同时支持自回归文本生成、并行感知检测和轨迹规划等异构解码行为
- 解决现有VLA(Vision-Language-Action)模型在自动驾驶中面临的架构碎片化问题:传统方法使用分离或级联解码器导致预训练权重无法共享、任务间信息流动受限
Card 03
核心贡献
核心贡献
- 揭示预训练VLM的因果注意力机制具有强迁移能力,可适配查询-视觉关系建模,而前馈网络(FFN)难以迁移,为统一架构设计提供关键洞察
- 提出混合解码器层(Mixed Decoder Layers):在浅层保留预训练因果注意力,仅添加任务特定的查询自注意力和FFN,实现文本生成与结构化预测的共享骨干
- 设计统一token表示:将图像token、结构化查询(检测/车道/规划)和文本token拼接为统一序列,通过因果注意力实现跨模态条件建模
- 实现高效推理模式:截断推理仅前向浅层,延迟降低约40%(264ms→156ms),同时保持多模态生成能力
- 在nuScenes开环评估和NAVSIM闭环评估上取得SOTA性能
Card 04
方法描述
方法描述
- 统一token序列:Z = [X_img, Q_det, Q_lane, Q_plan, X_text],所有token共享预训练因果注意力
- 3D位置编码:对图像token和结构化查询在RoPE后添加3D位置嵌入,增强空间建模
- 查询自注意力:在感知查询间添加额外的SelfAttn_q,支持并行检测和车道估计
- 任务特定FFN:为检测、车道、规划任务分别配置FFN_t,替换预训练FFN
- 三阶段训练策略:(1)感知-语言预训练 →(2)规划适配 →(3)联合微调,逐步激活各模块
Card 05
数据集与资源
数据集与资源
- nuScenes:1000个城市场景,700训练/150验证/150测试,使用6路环视相机,评估3D检测(NDS/mAP)、开环规划(L2误差、碰撞率)
- NAVSIM:基于nuPlan的闭环规划基准,1,192训练场景/136测试场景,评估PDMS综合得分
- OmniDrive扩展:nuScenes的QA风格标注,增强语言和推理信号
- 模型规模:InternVL3-1B(nuScenes)、InternVL3-2B(NAVSIM,从ReCogDrive初始化)
- 训练资源:64× NVIDIA H20 GPU,批次大小64(nuScenes)或128(NAVSIM),学习率1×10⁻⁴
Card 06
评估与结果
评估与结果
- nuScenes开环评估:平均L2误差0.28m(最优),平均碰撞率0.18%(最优),优于SOLVE-E2E(0.31m/0.30%)和ColaVLA(0.30m/0.23%)
- NAVSIM闭环评估:PDMS得分86.8,超越ReCogDrive(85.0)、AutoVLA(80.5)等VLA方法,接近DiffusionDrive(88.1)等专用规划器
- 文本能力保持:与OmniDrive-7B相比,文本条件规划平均L2误差0.32m vs 0.33m,语言生成能力不降级
- 文本监督消融:联合训练文本损失可轻微提升感知(NDS 32.31→33.94)和规划安全性(碰撞率0.40%→0.36%)
- 推理延迟:完整模型264ms,截断推理156ms(仅前6层),降低40%同时保持规划性能