一眼看懂
封面预览
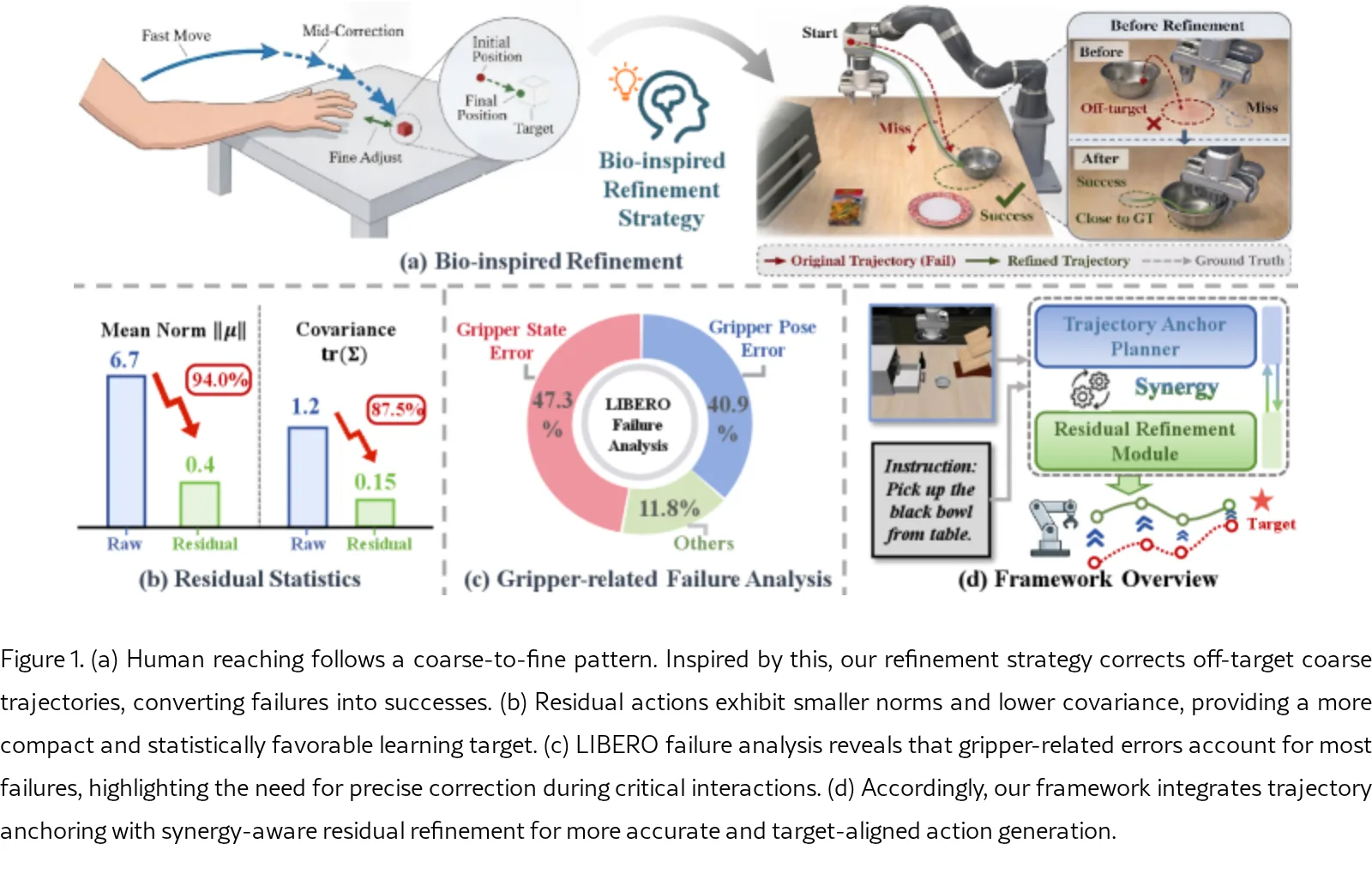
论文提出 AnchorRefine 框架,解决 视觉-语言-动作(VLA)模型 在精度关键性操作中的动作规模不匹配问题。
- 论文提出 AnchorRefine 框架,解决 视觉-语言-动作(VLA)模型 在精度关键性操作中的动作规模不匹配问题。
- 现有VLA政策将宏观轨迹组织和微观执行校正统一优化,导致大动作主导学习,抑制了关键校正信号。
- 通过将动作建模分解为 轨迹锚点 和 残差细化,实现全局运动结构与局部执行校正的协调建模。
Card 01
研究单位
研究单位
- 北京工业大学
- 北京航空航天大学
- 南京理工大学
Card 02
论文概述
论文概述
- 论文提出 AnchorRefine 框架,解决 视觉-语言-动作(VLA)模型 在精度关键性操作中的动作规模不匹配问题。
- 现有VLA政策将宏观轨迹组织和微观执行校正统一优化,导致大动作主导学习,抑制了关键校正信号。
- 通过将动作建模分解为 轨迹锚点 和 残差细化,实现全局运动结构与局部执行校正的协调建模。
Card 03
核心贡献
核心贡献
- 识别 动作规模不匹配 为现有VLA政策的关键限制,全局轨迹组织与局部精度校正相互干扰。
- 提出 AnchorRefine 分层框架,将动作建模分解为轨迹锚点规划和残差细化模块。
- 引入 决策感知的夹持器细化机制,更好地捕捉连续臂运动与离散夹持器决策的异质性。
Card 04
方法描述
方法描述
- 采用 分层锚点-细化轨迹协同 方法,包含 轨迹锚点规划器 和 残差细化模块。
- 锚点诱导的残差化 技术:细化目标定义相对于当前锚点预测,通过目标级耦合避免锚点偏差传播。
- 决策感知的夹持器细化:根据锚点阶段夹持器预测的可靠性,自适应调整校正强度,处理决策边界错误。
Card 05
数据集与资源
数据集与资源
- 使用 LIBERO、CALVIN ABC→D 仿真基准和真实机器人任务进行评估。
- 模型基于 GR-1(0.22B参数)和 X-VLA(1.1B参数)骨干网络实例化。
- 训练采用两阶段策略:第一阶段训练锚点规划器,第二阶段冻结锚点并训练细化模块。
Card 06
评估与结果
评估与结果
- 评估环境包括仿真基准和真实机器人平台。
- 主要评估指标为 任务成功率(SR) 和 平均序列长度。
- 关键结果:在 LIBERO-Long 上成功率提升 7.8%;在真实世界任务中成功率提升 18%;在 CALVIN ABC→D 上持续提升基于回归和扩散的VLA骨干网络性能。