一眼看懂
封面预览
论文提出 OmniVLA-RL,一个具备空间理解能力和在线强化学习功能的视觉-语言-动作模型,旨在解决现有VLA模型在空间感知精度、多模态融合…
- 论文提出 OmniVLA-RL,一个具备空间理解能力和在线强化学习功能的视觉-语言-动作模型,旨在解决现有VLA模型在空间感知精度、多模态融合…
- 核心创新在于采用 Mixture-of-Transformers (MoT) 架构,协同整合推理、空间和动作专家,并引入 Flow-GSPO…
- 论文通过在 LIBERO 和 LIBERO-Plus 基准上的广泛评估,证明了模型显著优于现有方法,克服了当前VLA模型的基本局限性。
Card 01
研究单位
研究单位
- AI Lab, Country Garden Services
- Omni AI
- VBot
- East China Normal University
Card 02
论文概述
论文概述
- 论文提出 OmniVLA-RL,一个具备空间理解能力和在线强化学习功能的视觉-语言-动作模型,旨在解决现有VLA模型在空间感知精度、多模态融合效果和强化学习稳定性方面的不足。
- 核心创新在于采用 Mixture-of-Transformers (MoT) 架构,协同整合推理、空间和动作专家,并引入 Flow-GSPO 方法以增强动作生成精度和训练鲁棒性。
- 论文通过在 LIBERO 和 LIBERO-Plus 基准上的广泛评估,证明了模型显著优于现有方法,克服了当前VLA模型的基本局限性。
Card 03
核心贡献
核心贡献
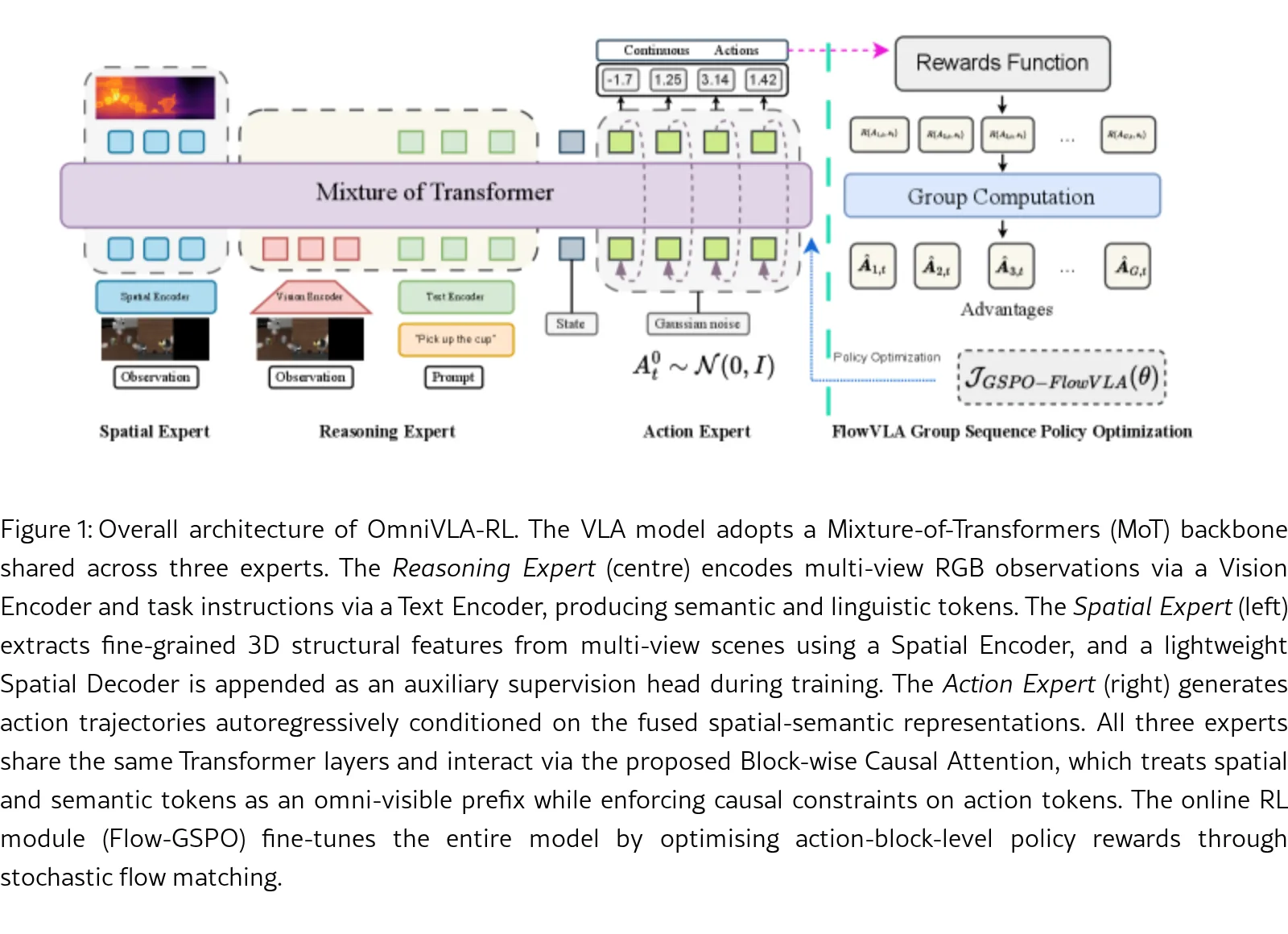
- 提出 OmniVLA-RL 统一框架,基于 Mixture-of-Transformers (MoT) 架构,通过共享Transformer层联合整合 Spatial Expert、Reasoning Expert 和 Action Expert,实现语言指令、视觉语义和3D空间特征的深度双向交互。
- 引入 Block-wise Causal Attention 机制,明确解耦空间语义前缀token和动作后缀token,确保感知保真度与执行连贯性。
- 提出 Flow-GSPO 方法,将确定性去噪过程重新表述为随机微分方程 (SDE),并在动作块层级使用 GSPO 进行优化,实现稳定的随机探索并避免现有GRPO方法的训练不稳定性。
- 在 LIBERO 基准上达到 97.6% 的平均成功率,在 LIBERO-Plus 基准上以更快的收敛速度和更高的最终性能显著超越 PPO 和 GRPO 基线。
Card 04
方法描述
方法描述
- 采用 Mixture-of-Transformers (MoT) 骨干架构,包含三个专家模块:Reasoning Expert (处理视觉语义和语言指令)、Spatial Expert (提取多视图3D空间特征) 和 Action Expert (生成机器人动作轨迹)。
- 提出并应用 Block-wise Causal Attention 掩码机制,将空间和推理token作为全可见前缀进行双向注意力计算,而对动作token实施因果约束,防止去噪噪声污染场景理解。
- 在强化学习阶段提出 Flow-GSPO 方法,将基于流匹配的动作生成 (原本为ODE过程) 通过Fokker-Planck方程转换为SDE过程以引入随机性,并以整个动作块为优化单元与 GSPO 算法集成,实现稳定在线强化学习。
Card 05
数据集与资源
数据集与资源
- 预训练阶段使用大规模 3D数据集 (用于空间感知训练) 和 DROID 数据集 (用于动作生成预训练)。
- 评估基准为 LIBERO (包含LIBERO-Spatial, LIBERO-Object, LIBERO-Goal, LIBERO-Long四个任务套件) 和更具挑战性的 LIBERO-Plus 基准。
- 模型基础VLM部分使用 PaLiGemma 的预训练权重进行初始化,训练中使用 AdamW 优化器,学习率为 1e-5。
Card 06
评估与结果
评估与结果
- 评估环境为 LIBERO 和 LIBERO-Plus 机器人操作仿真基准,主要评估指标为任务 成功率。
- 在 LIBERO 基准上,OmniVLA-RL 在所有四个任务套件中均排名第一,平均成功率高达 97.6%;在 LIBERO-Long 长视界任务上达到 93.5%,超越最强基线1.1%。
- 在更具挑战性的 LIBERO-Plus 基准上,OmniVLA-RL 在收敛速度和最终性能方面均显著优于 PPO 和 GRPO 基线,证明了 Flow-GSPO 方法的优越性。
- 消融实验证实了 Flow-GSPO 范式相对于模仿学习和标准RL方法的优越性,以及 Spatial Expert 对模型性能的关键作用。