一眼看懂
封面预览
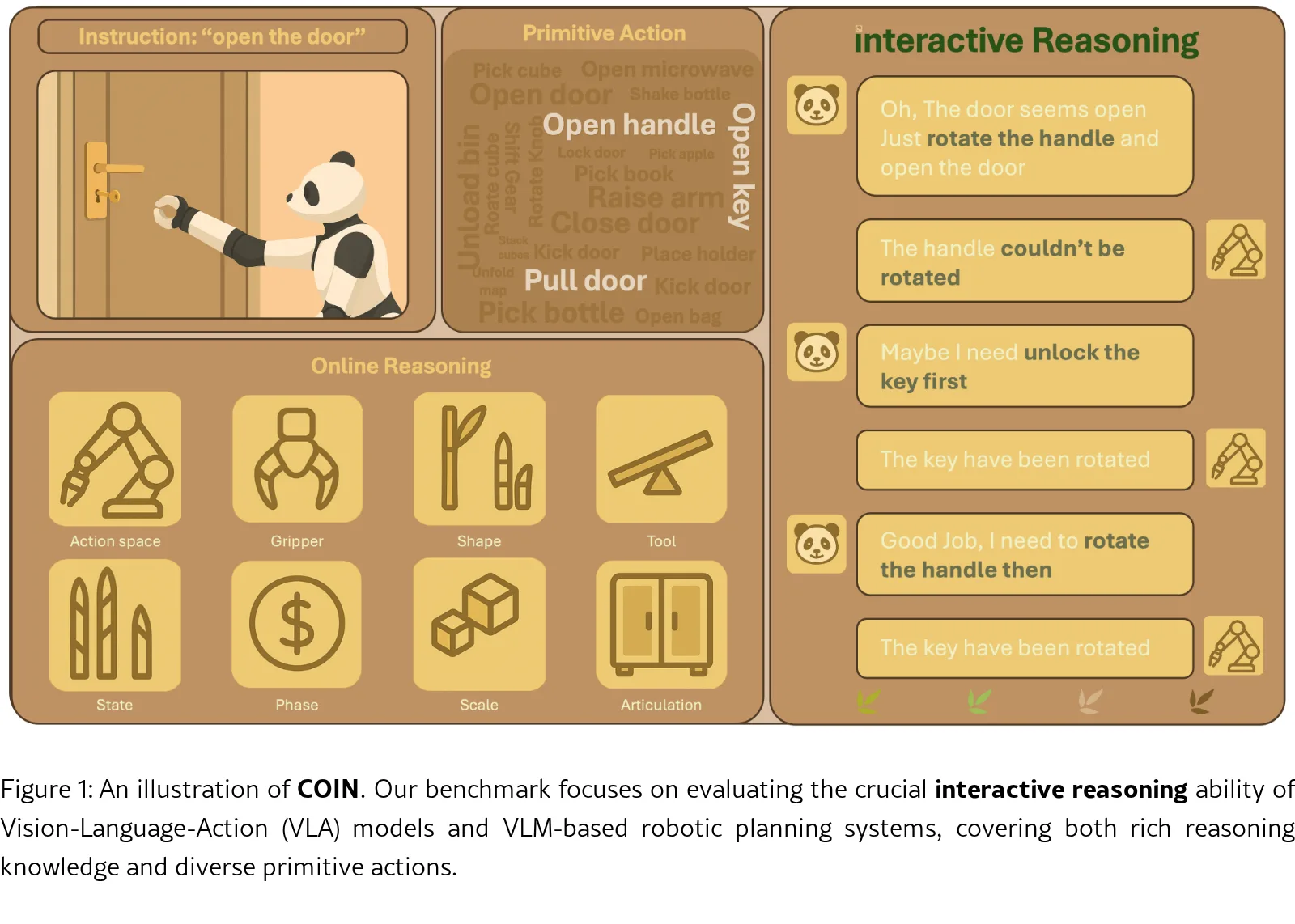
COIN 是一个评估具身人工智能中交互推理能力的基准测试,填补了现有基准测试无法系统评估交互推理的空白
- COIN 是一个评估具身人工智能中交互推理能力的基准测试,填补了现有基准测试无法系统评估交互推理的空白
- 构建了三个层次的基准:COIN-50(50个交互推理任务)、COIN-Primitive(20个基础操作技能)、COIN-Compositio…
- 开发了低成本移动端AR遥操作系统(硬件成本低于20美元),收集了包含1,000条演示轨迹的COIN-Primitive数据集
Card 01
研究单位
研究单位
- 中国科学技术大学 (University of Science and Technology of China)
- 北京通用人工智能研究院 (Beijing Institute for General Artificial Intelligence, BIGAI)
- 西安电子科技大学 (Xidian University)
- 上海交通大学 (Shanghai Jiao Tong University)
- 加州大学洛杉矶分校 (University of California, Los Angeles)
Card 02
论文概述
论文概述
- COIN 是一个评估具身人工智能中交互推理能力的基准测试,填补了现有基准测试无法系统评估交互推理的空白
- 构建了三个层次的基准:COIN-50(50个交互推理任务)、COIN-Primitive(20个基础操作技能)、COIN-Composition(中等复杂度任务)
- 开发了低成本移动端AR遥操作系统(硬件成本低于20美元),收集了包含1,000条演示轨迹的COIN-Primitive数据集
- 对CodeAsPolicy、VLA和H-VLA方法进行了系统性评估,揭示了当前方法的关键局限性
Card 03
核心贡献
核心贡献
- 构建了COIN基准,包含90个任务(50个交互任务+20个原语任务+20个组合任务),平均任务长度约990步,需2.83个子任务
- 开发了低成本智能手机AR遥操作系统,收集了1,000条专家演示轨迹,支持5个视角拍摄
- 提出了六大评估指标:任务成功率(SR)、类别成功率(CSR)、视觉问答得分(VS)、轨迹稳定性(TS)、夹爪控制稳定性(GS)、泛化能力得分(GCS)
- 提出了分层VLA架构(H-VLA),结合VLM高层规划器和VLA低层执行器
- 揭示了当前方法的根本性局限:视觉理解与运动执行之间存在显著差距
Card 04
方法描述
方法描述
- 任务公式化:将交互推理任务形式化为POMDP,部分可观察马尔可夫决策过程
- 任务分类:按推理能力分类为三大领域——物体中心推理、机器人中心推理、组合推理
- H-VLA架构:
- System 2(高层规划器):VLM处理多视角图像和任务指令,生成子任务序列,定期评估执行进度并调整指令队列
- System 1(低层执行器):VLA模型将技能指令转换为机器人动作,实时生成动作
- 评估方法:在ManiSkill3平台上使用Franka Emika Panda机器人进行模拟实验
Card 05
数据集与资源
数据集与资源
- 数据集:COIN-Primitive数据集,20个任务,每个任务50条演示轨迹,共1,000条
- 平台:ManiSkill3模拟环境
- 机器人:Franka Emika Panda
- 评估模型:
- VLA模型:Gr00t N1、Π0 (Pi0)、CogACT
- CodeAsPolicy:Voxposer、Rekep
- H-VLA组合:GPT-4o/Gemini 2.0 Flash + Gr00t N1/Pi0/CogACT
Card 06
评估与结果
评估与结果
- COIN-50结果:所有模型在复杂交互推理任务上几乎完全失败,成功率极少超过3%
- 主要问题:
- CodeAsPolicy方法:非交互式规划架构、规划-执行差距大、无法处理铰接物体
- H-VLA方法:VLM规划性能差、VLA执行能力不足、VLM-VLA协调薄弱
- COIN-Primitive结果:VLA模型在基础任务上达到16-19%成功率
- 泛化能力(GCS):CogACT为0.079,Pi0为0.404,Gr00t N1为0.000,显示严重的泛化失败
- 轨迹稳定性:CogACT表现最佳(0.150±0.055),但所有VLA模型都表现出显著的抖动和不连续运动