一眼看懂
封面预览
Vision-Language-Action (VLA) 模型已成为构建具身智能体的 promising 范式,但现有方法依赖直接动作预测,缺…
- Vision-Language-Action (VLA) 模型已成为构建具身智能体的 promising 范式,但现有方法依赖直接动作预测,缺…
- 提出 World-Value-Action (WAV) 模型,通过学习未来轨迹的结构化潜在表示,在视觉观察和语言指令条件下实现 VLA 系统的…
- 理论分析表明:直接在动作空间规划会导致可行轨迹概率随 horizon 指数衰减,而潜在空间推理可重塑搜索分布到可行区域
Card 01
研究单位
研究单位
- Westlake University(西湖大学)- 杭州,中国
- Nanjing University Suzhou Campus(南京大学苏州校区)- 苏州,中国
Card 02
论文概述
论文概述
- Vision-Language-Action (VLA) 模型已成为构建具身智能体的 promising 范式,但现有方法依赖直接动作预测,缺乏对长-horizon 轨迹的推理能力
- 提出 World-Value-Action (WAV) 模型,通过学习未来轨迹的结构化潜在表示,在视觉观察和语言指令条件下实现 VLA 系统的隐式规划- 学习的世界模型预测未来状态,轨迹价值函数评估其长期效用,动作生成被表述为潜在空间中的推理过程
- 理论分析表明:直接在动作空间规划会导致可行轨迹概率随 horizon 指数衰减,而潜在空间推理可重塑搜索分布到可行区域
Card 03
核心贡献
核心贡献
- 提出 WAV 模型,一个通过联合建模动态特性和轨迹价值实现 VLA 系统隐式规划的统一框架
- 提供理论分析,证明潜在规划可减轻动作空间规划中固有的可行轨迹概率指数衰减问题
- 在模拟基准测试和真实场景中实现最先进性能,在长-horizon 推理和泛化方面取得显著提升
Card 04
方法描述
方法描述
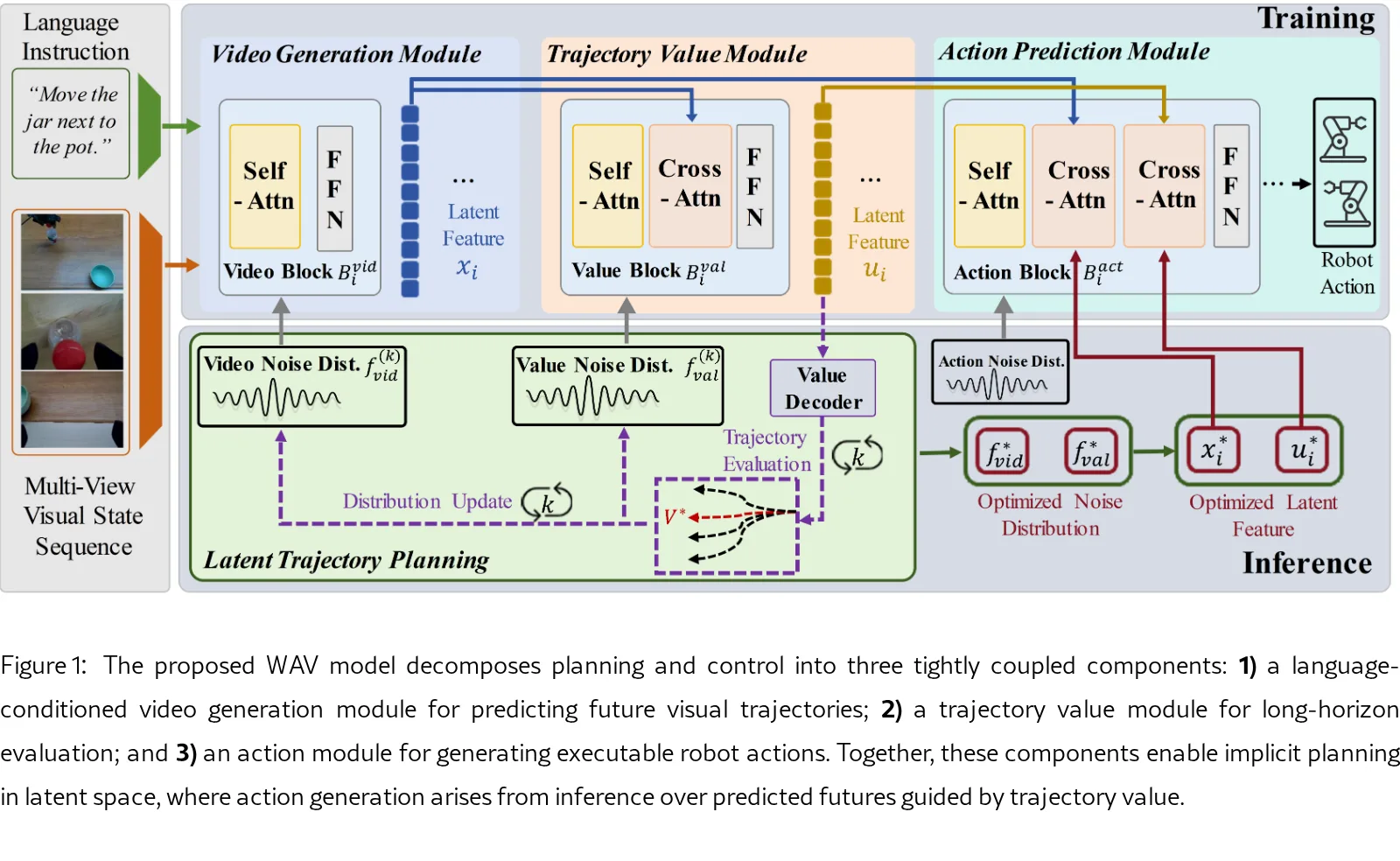
- 语言条件视频生成模块:基于 Diffusion Transformer (DiT) 架构,根据历史多视角视觉、随机潜在变量和语言语义预测未来视觉轨迹
- 轨迹价值模块:基于 DiT 的自回归架构,通过交叉注意力评估预测轨迹的长期累积回报
- 动作解码模块:整合视频和价值特征,生成可执行的机器人动作
- 三阶段 Flow Matching 训练:分别训练视频生成、价值预测和动作解码模块
- 潜在规划和迭代推理:推理时保持两个独立的高斯噪声分布(视频流噪声和价值流噪声),通过迭代采样、评估和更新分布,逐步集中概率质量到高价值可行轨迹
Card 05
数据集与资源
数据集与资源
- 模拟基准:LIBERO benchmark,包含四个任务套件(Spatial、Object、Goal、Long)
- 真实机器人实验:长-horizon 组合操作任务
- 未在 HTML 中明确找到模型参数量和训练资源信息
Card 06
评估与结果
评估与结果
- 模拟环境:WAV 在 LIBERO 基准上与多个 baseline(Diffusion Policy、Octo、OpenVLA、SpatialVLA、π₀-FAST、GR00T-N1、π₀ 等)对比,在 Long 任务上提升显著
- 消融实验:分析了迭代次数 K、采样大小 M,N、平滑参数 α,β、精英选择 K₁,K₂ 对性能的影响,以及性能-效率权衡