一眼看懂
封面预览
提出一种名为 HiVLA 的视觉为中心的层级化机器人操作系统,旨在解决端到端 Vision-Language-Action (VLA) 模型在…
- 提出一种名为 HiVLA 的视觉为中心的层级化机器人操作系统,旨在解决端到端 Vision-Language-Action (VLA) 模型在…
- 通过将高层语义规划与底层运动控制解耦,系统利用 VLM 作为高层规划器进行任务分解与视觉接地,并引入 DiT Action Expert 来生…
- 目标是在保持 VLM 零样本推理能力的同时,实现复杂长程任务的高效执行和精细操作。
Card 01
研究单位
研究单位
- The University of Hong Kong
- Shanghai AI Laboratory
- Shanghai Jiao Tong University
- The Chinese University of Hong Kong
Card 02
论文概述
论文概述
- 提出一种名为 HiVLA 的视觉为中心的层级化机器人操作系统,旨在解决端到端 Vision-Language-Action (VLA) 模型在微调过程中因“灾难性遗忘”而导致推理能力下降的核心问题。
- 通过将高层语义规划与底层运动控制解耦,系统利用 VLM 作为高层规划器进行任务分解与视觉接地,并引入 DiT Action Expert 来生成精确的底层动作。
- 目标是在保持 VLM 零样本推理能力的同时,实现复杂长程任务的高效执行和精细操作。
Card 03
核心贡献
核心贡献
- 提出了一种以视觉接地为中心的层级化 VLA 框架 HiVLA,通过结构化计划(子任务指令和边界框)连接高层规划与底层控制,避免了 VLM 的灾难性遗忘。
- 在 DiT Action Expert 中设计了新颖的级联交叉注意力机制,能够依次融合全局视觉上下文、高分辨率局部裁剪特征和子任务语言指导,最大化利用 VLM 的规划输出。
- 在模拟环境和真实世界中进行了大量实验,证明 HiVLA 显著优于现有的端到端基准模型,特别是在长程技能组合和杂乱场景中的精细操作任务上。
Card 04
方法描述
方法描述
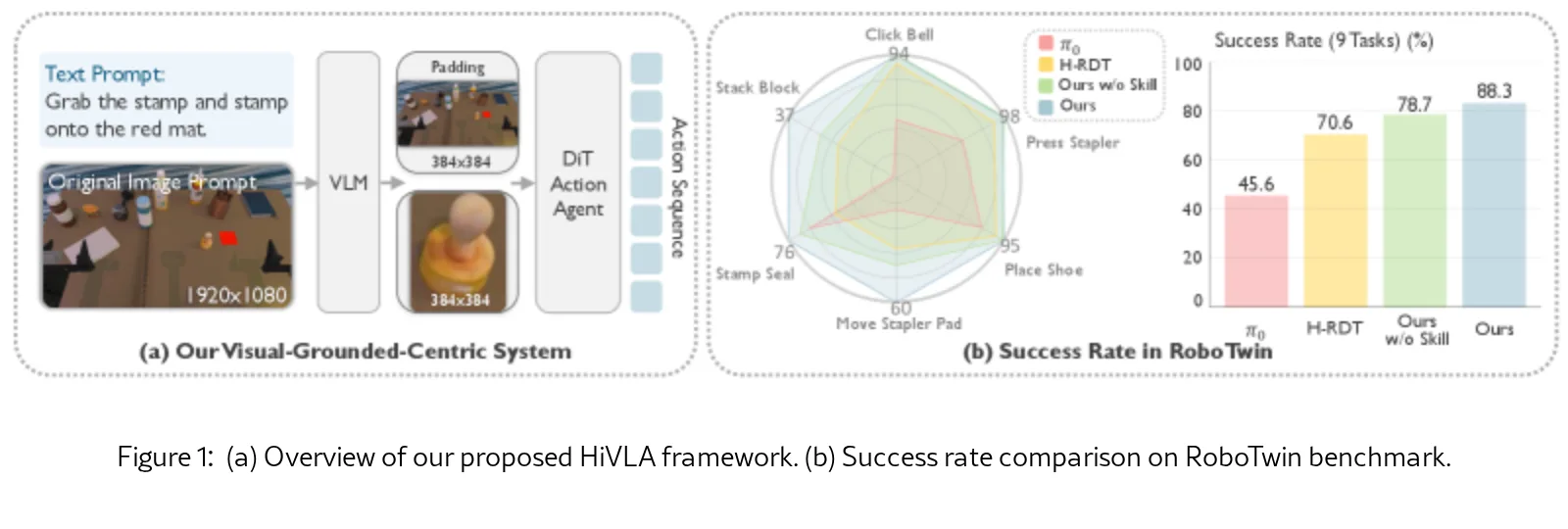
- 系统包含两个核心模块:VLM Planner Agent 和 DiT Action Expert。
- VLM Planner Agent 使用预训练的 VLM (基于 Qwen3-VL),根据当前视觉观察和语言指令,输出包含子任务描述和目标边界框的结构化计划(JSON格式)。
- DiT Action Expert 是一个基于 Conditional Flow Matching 的扩散 Transformer,其核心创新是层级化的条件注入机制:在每个 DiT Block 中通过三个连续的交叉注意力层,依次注入 (1) 全局视觉上下文、(2) 携带绝对位置编码的高分辨率局部图像特征、(3) 子任务语言嵌入,从而实现从“哪里看”到“做什么”的精细引导。
Card 05
数据集与资源
数据集与资源
- 使用了自建的高分辨率数据集 HiVLA-HD,包含 15 个操作任务,每个任务约有 1,000 个片段。
- 使用了 Aloha-Agilex-1.0 双臂机器人平台(14自由度)进行模拟和真实世界实验。
- 训练使用了 2 张 NVIDIA H200 GPU,批大小为 64,训练步数为 150K 步。
Card 06
评估与结果
评估与结果
- 在 RoboTwin 2.0 模拟平台上对 9 个任务进行评估,涵盖简单与困难任务。
- 主要评估指标为任务 成功率。
- HiVLA 在总平均成功率上达到 83.3%,比最强基准 H-RDT 提高 17.7%,比 SOTA 模型 $\pi_0$ 提高 42.7%。
- 真实世界实验表明,在杂乱的多物体场景中,HiVLA 显著优于基于全局特征的基准模型,能够准确执行语义接地后的精细操作。消融研究验证了“从粗到细”的级联注入策略的有效性。