一眼看懂
封面预览
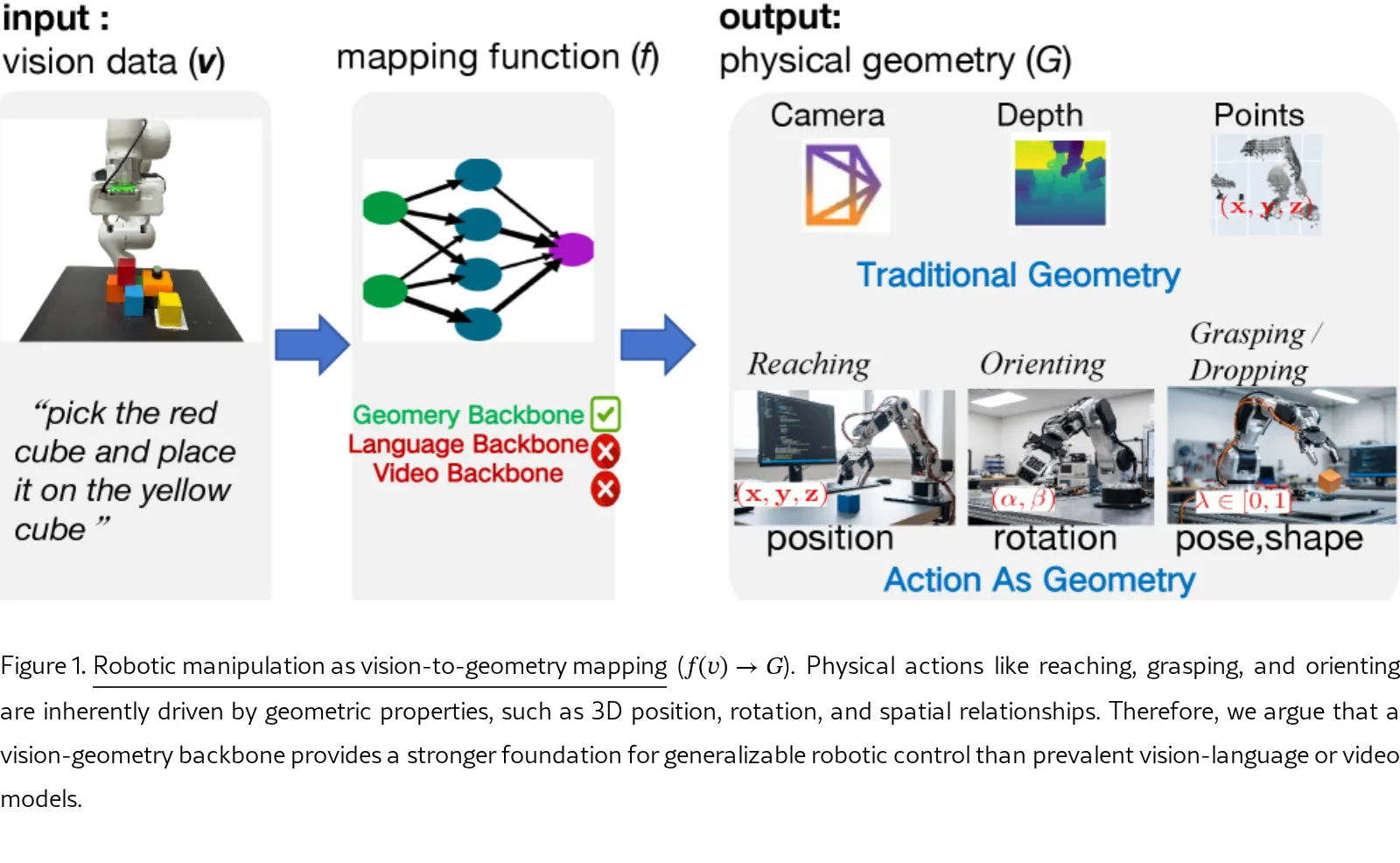
论文将机器人操作定义为视觉到几何的映射 ($f(v) \rightarrow G$),指出物理操作本质上依赖于 3D 几何属性和空间关系。
- 论文将机器人操作定义为视觉到几何的映射 ($f(v) \rightarrow G$),指出物理操作本质上依赖于 3D 几何属性和空间关系。
- 批评了现有的 VLA 模型和视频预测模型,认为它们基于 2D 图像-文本或像素数据训练,缺乏物理操作所需的精确 3D 几何感知能力。
- 提出了 VGA (Vision-Geometry-Action) 模型,旨在通过使用预训练的 3D 世界模型作为骨干网络,建立视觉输入与物理动…
Card 01
研究单位
研究单位
- Sun Yat-sen University
- Guangdong Key Laboratory of Big Data Analysis and Processing
- X-Era AI Lab
- AMAP, Alibaba
- Guangdong University of Technology
Card 02
论文概述
论文概述
- 论文将机器人操作定义为视觉到几何的映射 ($f(v) \rightarrow G$),指出物理操作本质上依赖于 3D 几何属性和空间关系。
- 批评了现有的 VLA 模型和视频预测模型,认为它们基于 2D 图像-文本或像素数据训练,缺乏物理操作所需的精确 3D 几何感知能力。
- 提出了 VGA (Vision-Geometry-Action) 模型,旨在通过使用预训练的 3D 世界模型作为骨干网络,建立视觉输入与物理动作之间的无缝映射。
Card 03
核心贡献
核心贡献
- 将机器人操作形式化为视觉到几何映射,并提出 VGA 模型,超越了基于 2D 模式匹配的方法,转向物理感知。
- 开发了统一的 3D 中心架构,使用视觉-几何骨干网络替代传统语言或视频模型,引入 Progressive Volumetric Modulation (PVM) 模块和联合训练策略来绕过 2D 处理的瓶颈。
- 在仿真基准和真实世界部署中证明了该方法在空间精确操作和跨视角泛化方面的优越性。
Card 04
方法描述
方法描述
- 使用预训练的 3D 世界模型 VGGT 作为骨干网络,处理多视角 RGB 观测、语言指令和机器人本体感知数据。
- 在骨干网络中采用 Alternating-Attention(交替注意力)机制,结合帧内局部注意力和跨帧全局注意力以构建统一的 3D 表示。
- 引入 Progressive Volumetric Modulation (PVM) 模块,通过分层跨模态交互将 3D 表示逐步注入到动作解码头中。
- 采用联合训练策略,同时预测机器人动作块和辅助 3D 属性(相机参数和深度图),推理时解耦辅助头以提高效率。
- 使用 LoRA 微调技术(秩为 64)以保持骨干网络的预训练空间先验能力。
Card 05
数据集与资源
数据集与资源
- 使用 LIBERO 基准进行仿真实验,包含四个任务套件。
- 真实世界实验在 Franka Panda 机械臂上进行,每任务收集 80-100 条遥操作演示数据。
- 模型骨干网络和动作头各包含 12 层,可训练参数总量约 500M。
- 训练资源使用单个 NVIDIA A100-SXM4-80GB GPU,最长训练耗时约 60 GPU 小时。
Card 06
评估与结果
评估与结果
- 评估环境包括 LIBERO 仿真基准和真实世界机械臂操作平台。
- 主要评估指标为任务成功率。
- 在 LIBERO 基准上,VGA 平均成功率达到 98.1%,超越 $\pi_{0.5}$ (96.9%)、OpenVLA-OFT (97.1%) 等顶级基线。
- 在真实世界未见视角的泛化测试中,VGA 平均成功率为 58%,优于 $\pi_{0.5}$ 的 52%,显示出显著的零样本跨视角泛化能力。
- 消融实验证明 PVM 模块、联合训练策略、预训练权重和 LoRA 微调对最终性能均有重要贡献。