一眼看懂
封面预览
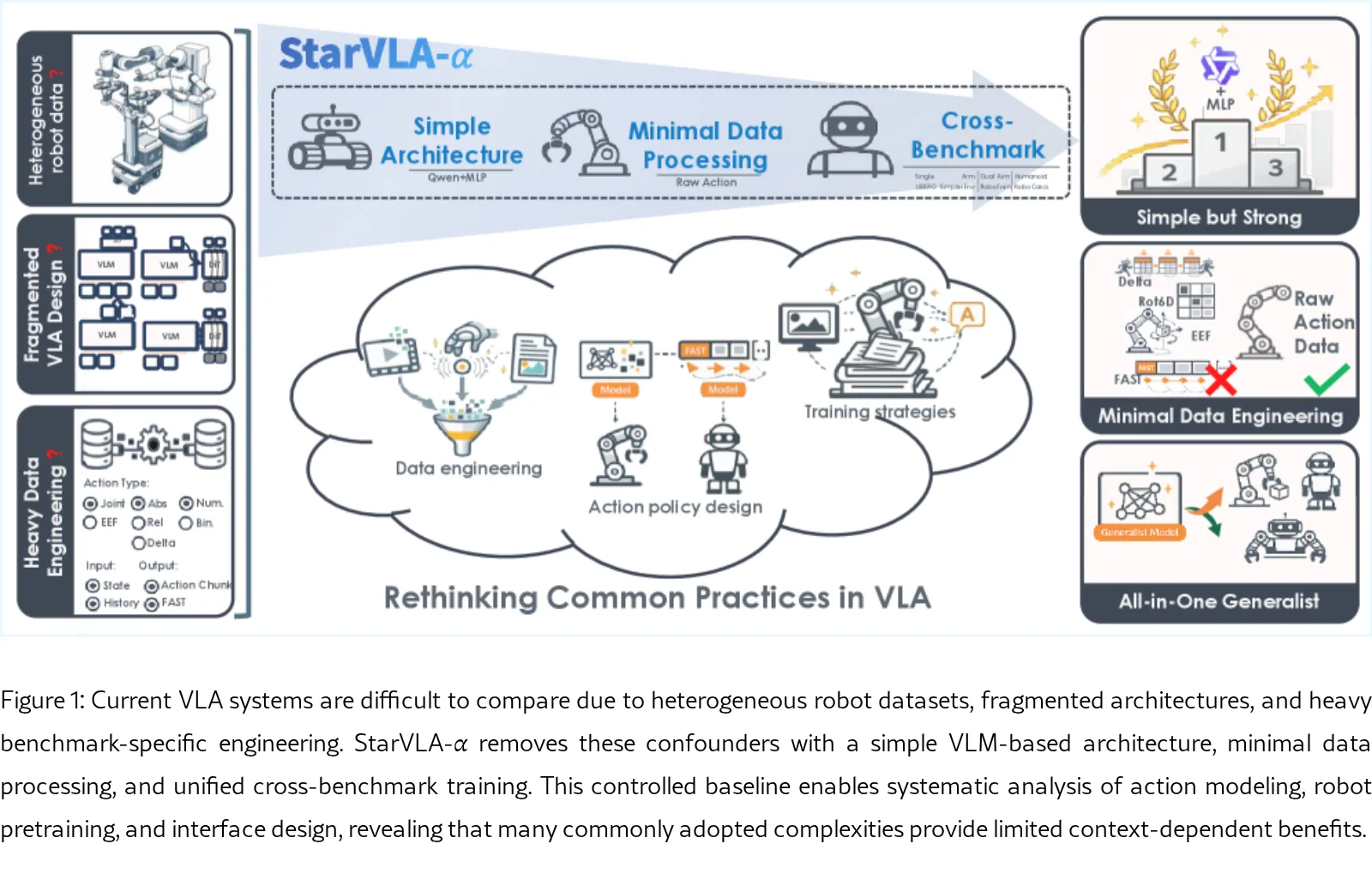
针对当前视觉-语言-动作(VLA)领域架构碎片化、数据处理复杂及过度依赖基准特定工程的问题,提出了一个简洁而强大的基线模型 StarVLA-α。
- 针对当前视觉-语言-动作(VLA)领域架构碎片化、数据处理复杂及过度依赖基准特定工程的问题,提出了一个简洁而强大的基线模型 StarVLA-α。
- 该模型通过最小化架构和流程复杂性,旨在消除实验中的混杂因素,从而在受控条件下系统性地分析 VLA 的关键设计选择。
- 研究表明,强大的 VLM 预训练骨干配合最小化的设计即可实现极具竞争力的性能,无需复杂的架构或繁琐的工程技巧。
Card 01
研究单位
研究单位
- 香港科技大学 (HKUST)
- 西安交通大学 (XJTU)
- 香港中文大学 (CUHK)
- 清华大学 (THU)
- 阿里巴巴通义实验室
- 思谋科技
Card 02
论文概述
论文概述
- 针对当前视觉-语言-动作(VLA)领域架构碎片化、数据处理复杂及过度依赖基准特定工程的问题,提出了一个简洁而强大的基线模型 StarVLA-α。
- 该模型通过最小化架构和流程复杂性,旨在消除实验中的混杂因素,从而在受控条件下系统性地分析 VLA 的关键设计选择。
- 研究表明,强大的 VLM 预训练骨干配合最小化的设计即可实现极具竞争力的性能,无需复杂的架构或繁琐的工程技巧。
Card 03
核心贡献
核心贡献
- 提出了一个简单且强大的 VLA 基线,证明了精简的设计即可在涵盖五种具身的四个主流基准上达到领先性能。
- 在统一的主干、数据和训练设置下,系统性地重新评估了常见 VLA 设计选择,揭示了复杂的架构和工程往往收益有限且依赖特定场景。
- 成功训练了单个通用模型,在无任务特定适配的情况下实现了跨任务和跨具身的强泛化能力。
Card 04
方法描述
方法描述
- 采用预训练的 Qwen3-VL 作为统一的 VLM 骨干网络,并在其上附加轻量级的 MLP 动作头 以回归连续动作。
- 实施最小化数据处理策略:仅输入原始 RGB 图像和语言指令,仅对动作进行简单的归一化处理,避免基准特定的定制化。
- 在多基准联合训练中,采用简单的 动作填充策略,将不同机器人的动作空间统一扩展至 32 维,以处理具身异构性。
Card 05
数据集与资源
数据集与资源
- 主要基准数据集:LIBERO, SimplerEnv, RoboTwin 2.0, RoboCasa-GR1。
- 消融研究数据:Open X-Embodiment (OXE), InternData-A1, RoboTwin-Rand。
- 模型规模: 主要基于 Qwen3-VL-4B,同时也评估了 2B 和 8B 版本。
- 训练配置: 批量大小 256,学习率 1e-4。
Card 06
评估与结果
评估与结果
- 评估环境: 模拟环境基准测试及真实世界机器人实验。
- 对比基线:OpenVLA-OFT, π0, π0.5, GR00T-N1.6。
- 关键实验结果: StarVLA-α 在 LIBERO 上达到 98.8% 的平均成功率;在真实世界 RoboChallenge 基准上,单个通用模型优于 π0.5 20%。
- 设计分析结论: 连续动作预测优于离散 Token 预测;轻量 MLP 动作头已足够强大;域外大规模预训练数据可能损害泛化能力;数据工程技巧仅在数据稀缺时有微弱增益。