一眼看懂
封面预览
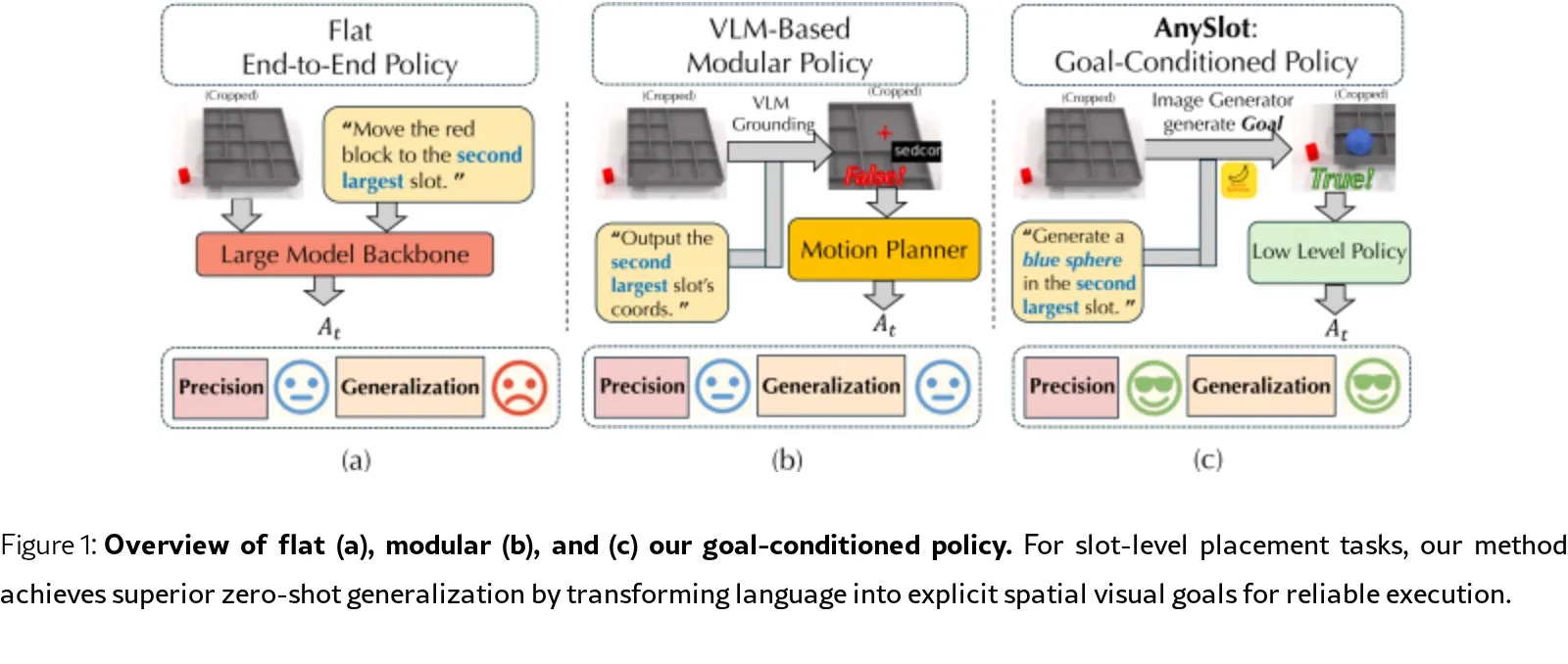
论文针对现代视觉-语言-动作(VLA)策略在组合语言指令下的精确物体放置任务中表现不佳的问题
- 论文针对现代视觉-语言-动作(VLA)策略在组合语言指令下的精确物体放置任务中表现不佳的问题
- 研究目标是解决“槽位级放置”任务,该任务要求既要有可靠的槽位语义定位,又要有亚厘米级的执行精度
- 提出了 AnySlot 框架,通过引入显式的空间视觉目标作为中间表示,将高层语言定位与底层控制解耦
Card 01
研究单位
研究单位
- Stony Brook University (Stony Brook, USA)
- Carnegie Mellon University (Pittsburgh, USA)
- Mohamed Bin Zayed University of Artificial Intelligence (Abu Dhabi, UAE)
- Peking University (Beijing, China)
Card 02
论文概述
论文概述
- 论文针对现代视觉-语言-动作(VLA)策略在组合语言指令下的精确物体放置任务中表现不佳的问题
- 研究目标是解决“槽位级放置”任务,该任务要求既要有可靠的槽位语义定位,又要有亚厘米级的执行精度
- 提出了 AnySlot 框架,通过引入显式的空间视觉目标作为中间表示,将高层语言定位与底层控制解耦
Card 03
核心贡献
核心贡献
- 识别并形式化了一个具有重要实际意义但未被充分研究的问题:槽位级操作定位
- 提出了 AnySlot,一种两阶段系统,利用图像生成模型合成空间视觉标记,配合 VLA 策略实现精确放置
- 构建了 SlotBench,一个专门用于评估零样本环境下结构化空间推理和语言定位的综合基准
Card 04
方法描述
方法描述
- 采用分层设计,将策略分解为高层目标构建模块和底层目标条件策略
- 高层模块利用 Nano-Banana 图像生成模型在图像中渲染蓝色球体标记,结合深度图和相机校准将其提升为多视图一致的视觉目标
- 底层模块使用基于 PaliGemma-3B 骨干网络的连续生成式 VLA 策略($\pi_{0.5}$),根据生成的视觉目标执行抓取和放置动作
Card 05
数据集与资源
数据集与资源
- 使用 SlotBench 进行评估,该基准包含 9 个具有挑战性的任务类别(如序数推理、大小比较、距离推理等)
- 训练数据为在 SAPIEN 模拟器中收集的合成数据集,包含多视图观察和 Oracle 视觉目标
- 训练资源使用单张 NVIDIA H200 GPU,批大小为 64,训练步数为 20,000 步
Card 06
评估与结果
评估与结果
- 在 SlotBench 上与多种基线进行对比,包括 Flat 策略(Diffusion Policy, OpenVLA)和 Modular 策略
- 主要评估指标为成功率(SR)和指令准确率(IA)
- 实验结果显示,AnySlot 平均成功率接近 90%,显著优于 Flat 策略(大多接近 0%)和 Modular 策略(如 AnyPlace 仅在部分任务上有较低成功率)