一眼看懂
封面预览
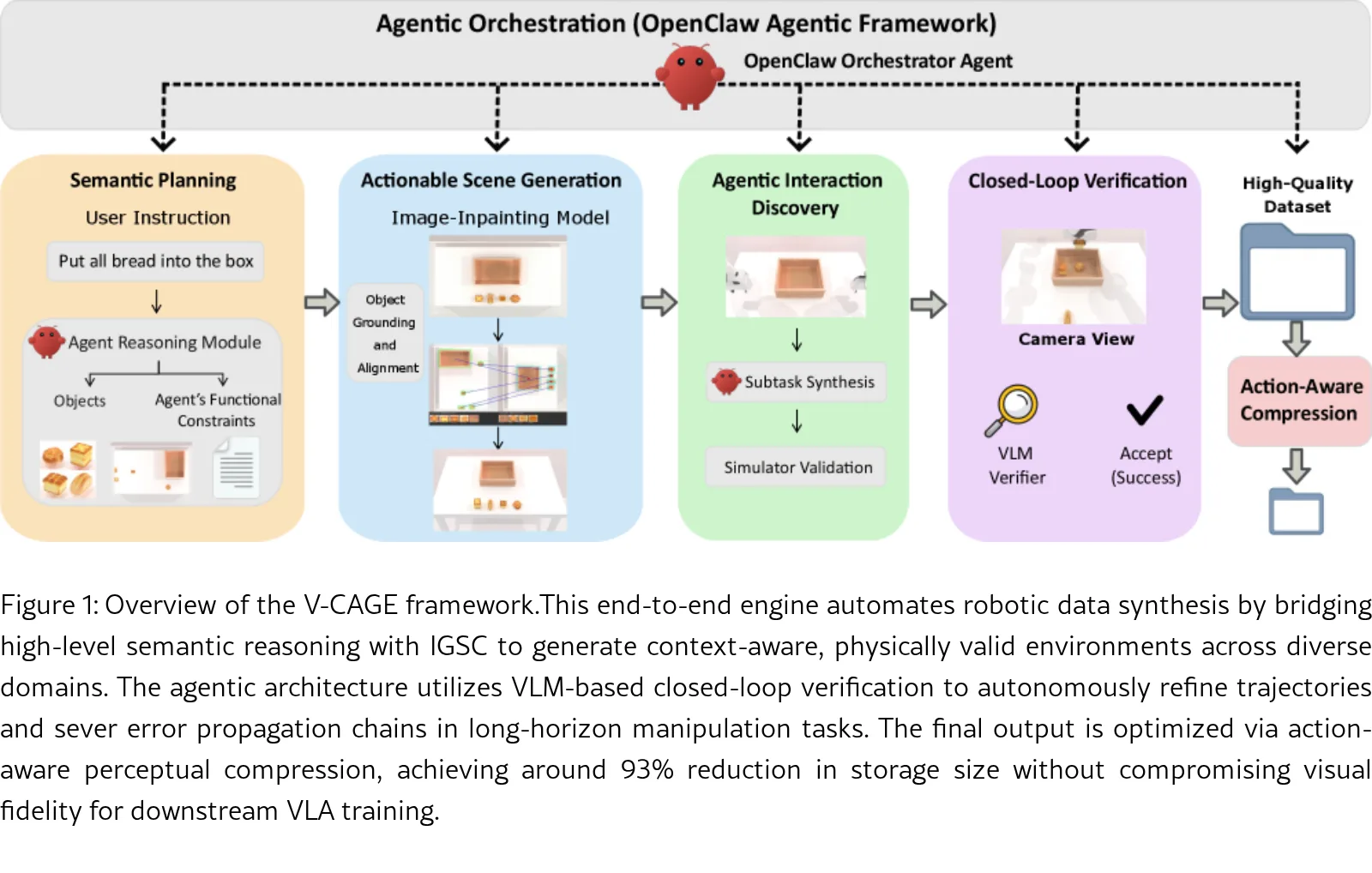
论文提出了 V-CAGE (Vision-Closed-loop Agentic Generation Engine),用于自主合成机器人大规…
- 论文提出了 V-CAGE (Vision-Closed-loop Agentic Generation Engine),用于自主合成机器人大规…
- 旨在解决现有场景生成方法缺乏上下文感知、几何冲突频发以及开环执行导致的“静默失败”问题。
- 该框架利用基础模型连接高层语义推理与底层物理交互,确保长视野轨迹的正确性和高效存储。
Card 01
研究单位
研究单位
- University of Cambridge
- Wuhan University
- Shanghai Jiao Tong University
Card 02
论文概述
论文概述
- 论文提出了 V-CAGE (Vision-Closed-loop Agentic Generation Engine),用于自主合成机器人大规模数据集。
- 旨在解决现有场景生成方法缺乏上下文感知、几何冲突频发以及开环执行导致的“静默失败”问题。
- 该框架利用基础模型连接高层语义推理与底层物理交互,确保长视野轨迹的正确性和高效存储。
Card 03
核心贡献
核心贡献
- 提出了 Inpainting-Guided Scene Construction (IGSC) 算法,自动进行任务驱动的物体选择与放置,显著减少几何冲突。
- 通过集成功能元数据与模板搜索机制,使智能体能够自主执行可行的子任务,连接高层指令与底层动作。
- 实现了基于 VLM 的闭环验证机制,充当“视觉评论家”来过滤静默失败,切断错误传播链。
- 引入了动作感知的感知压缩算法,在保持下游训练效果的同时实现了超过 90% 的文件大小缩减。
Card 04
方法描述
方法描述
- 基于 OpenClaw 智能体框架构建,使用 SAPIEN 作为物理仿真后端。
- IGSC 流程利用 LLM 选择资产,使用 Nano Banana 模型进行布局修复,并通过 Grounding DINO 和 DINOv2 进行视觉对应匹配。
- 采用 Gemini 3 视觉语言模型作为拒绝采样过程的验证器,确保生成轨迹的语义正确性。
- 压缩算法基于机器人交互强度提取关键帧,利用 HEVC 编码和 ColorVideoVDP 指标优化压缩率。
Card 05
数据集与资源
数据集与资源
- 使用遵循 RoboTwin 范式的预构建资产库,包含抓取点和功能点标注。
- 生成了四种长视野任务数据:AutoCheckout、PackBreads、PackStationery、SortToCabinet。
- 真实世界评估基于 ALOHA-AgileX 硬件平台进行。
Card 06
评估与结果
评估与结果
- 在生成的合成数据上训练 $\pi_{0.5}$ VLA 模型,在复杂任务上取得了显著的成功率(如 PackStationery 达到 100%)。
- Sim-to-Real 实验表明,混合训练策略的成功率提升至 55%,相比仅使用真实数据的 20% 有显著提高。
- 压缩后的数据集文件大小减少超过 93%,且策略训练成功率与原始数据相比几乎无差异。
- 消融实验显示 IGSC 模块大幅提升了有效任务比例,VLM 闭环验证使生成数据的精确度达到 100%。