一眼看懂
封面预览
论文提出了 LAMP 方法,旨在解决开放世界机器人操作中的泛化难题,特别是现有方法在处理新任务和未见环境时的局限。
- 论文提出了 LAMP 方法,旨在解决开放世界机器人操作中的泛化难题,特别是现有方法在处理新任务和未见环境时的局限。
- 核心思想是利用 图像编辑 模型中隐含的丰富 2D 空间线索,将其提升为 物体间 3D 变换,作为连续且几何感知的表征,为精细操作提供精确指导。
- 该方法利用图像编辑固有的主体一致性和几何先验,通过跨状态点云配准提取精确的操作意图,实现了零样本泛化。
Card 01
研究单位
研究单位
- State Key Lab of CAD&CG, Zhejiang University
- InSpatio Research
Card 02
论文概述
论文概述
- 论文提出了 LAMP 方法,旨在解决开放世界机器人操作中的泛化难题,特别是现有方法在处理新任务和未见环境时的局限。
- 核心思想是利用 图像编辑 模型中隐含的丰富 2D 空间线索,将其提升为 物体间 3D 变换,作为连续且几何感知的表征,为精细操作提供精确指导。
- 该方法利用图像编辑固有的主体一致性和几何先验,通过跨状态点云配准提取精确的操作意图,实现了零样本泛化。
Card 03
核心贡献
核心贡献
- 提出了 LAMP 框架,首次将图像编辑技术提升为通用的 3D 先验,从单目 RGB-D 观察中提取物体间 SE(3) 变换,无需任务特定训练。
- 深入分析了现有基于 VLM/LLM 方法在表达精细几何关系(如相对旋转、接触几何)上的不足,证明了基于图像编辑的 3D 先验具有更强的泛化性和鲁棒性。
- 在多样化的真实世界操作任务中进行了广泛实验,展示了方法在零样本设置下的强大性能,涵盖精细操作、关节物体操作和长视距任务。
Card 04
方法描述
方法描述
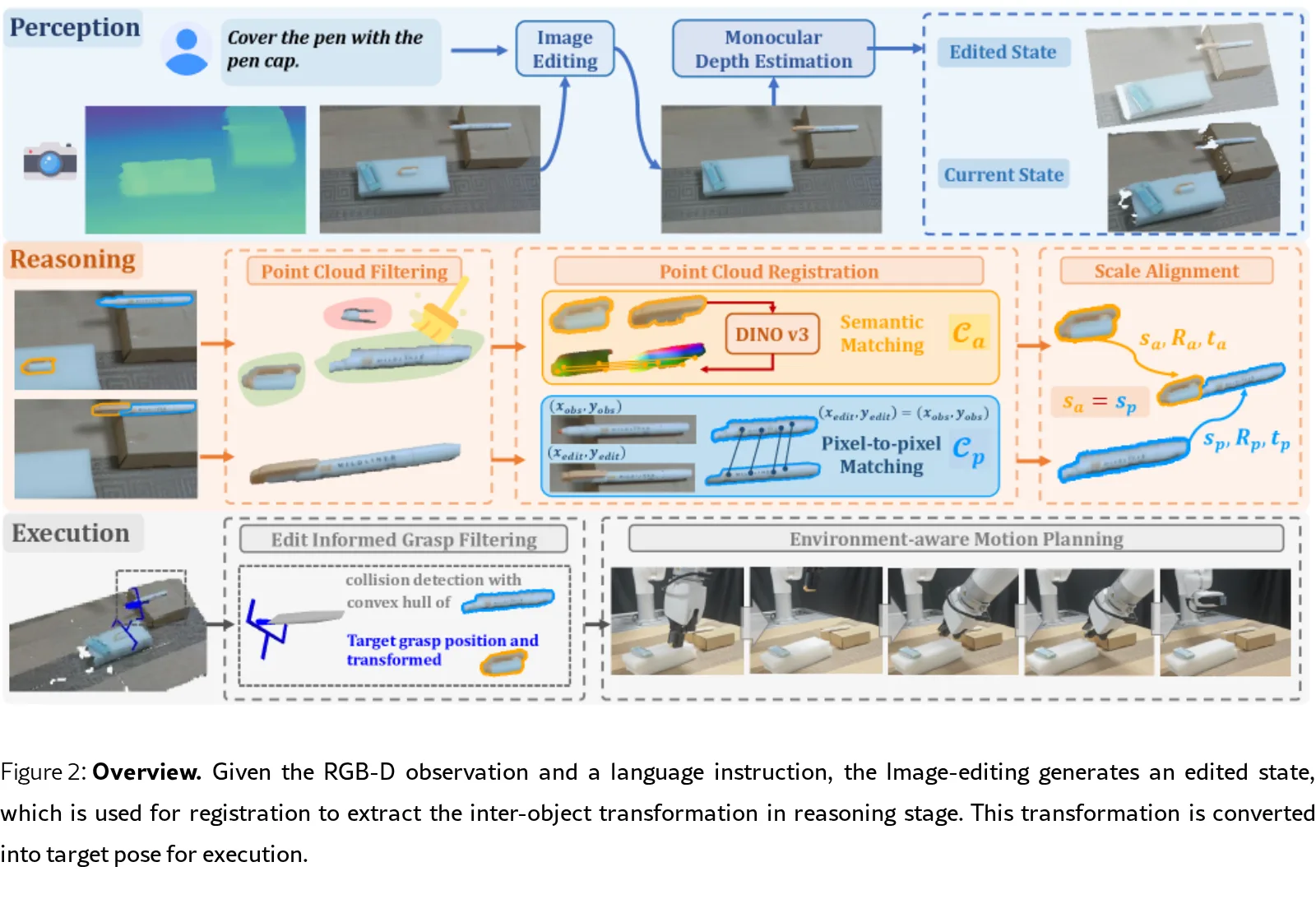
- 感知阶段:利用 Qwen-Image-Edit 和 Gemini 2.5 Flash 等图像编辑模型根据语言指令生成目标状态图像,并通过 VGGT 进行单目深度估计,结合 SAM 和 LLMDet 提取物体掩码。
- 推理阶段:提出了 跨状态点云配准 流程,包括 分层点云滤波(结合 DINOv3 特征与聚类去除飞点噪声)和 尺度对齐 机制,以估计物体间精确的 6-DoF 变换。
- 执行阶段:利用 AnyGrasp 生成抓取候选,根据编辑后的目标状态进行碰撞检测以筛选任务可行的抓取姿态,最后使用 CuRobo 进行无碰撞轨迹规划。
Card 05
数据集与资源
数据集与资源
- 实验环境为真实世界场景,使用 UFACTORY xArm7 机械臂和 Intel RealSense D435i RGB-D 相机。
- 评估涉及自建的多样化真实世界操作场景,涵盖 13 种代表性任务(如硬币插入、盖子覆盖、茶水倾倒、积木装配等)。
- 依赖预训练的视觉基础模型,包括图像编辑模型、深度估计模型、特征提取模型(DINOv3)和分割模型(SAM)。
Card 06
评估与结果
评估与结果
- 点云配准评估:在 Lid covering 等任务上,LAMP 的平移 RMSE 达到 0.003,显著优于 2BY2 和 AnyPlace 等基线方法。
- 开放世界操作评估:在 13 项真实任务中,LAMP 的平均成功率达到 66.0%,远超 Voxposer (4.0%)、CoPa (13.0%) 和 Rekep (24.0%)。
- 长视距操作评估:成功完成了将鸭子放入抽屉、打包鸡蛋等长视距任务,展示了方法在多步骤交互中的连贯性。
- 消融实验:验证了分层滤波和尺度对齐模块对处理深度噪声和视点变化的重要性,证明了方法在复杂场景下的鲁棒性。