一眼看懂
封面预览
论文研究如何将大规模视觉-语言-动作(VLA)驾驶模型中的大语言模型(LLM)推理能力,蒸馏到一个高效的纯视觉学生模型中。
- 论文研究如何将大规模视觉-语言-动作(VLA)驾驶模型中的大语言模型(LLM)推理能力,蒸馏到一个高效的纯视觉学生模型中。
- 核心目标是在保持甚至超越教师模型性能的前提下,大幅降低模型的计算开销,使其适用于实际部署。
- 解决了VLA模型因参数量巨大而导致的推理延迟高、内存占用大等问题,特别是在复杂交互场景的闭环评估中。
Card 01
研究单位
研究单位
- 埃因霍温理工大学
Card 02
论文概述
论文概述
- 论文研究如何将大规模视觉-语言-动作(VLA)驾驶模型中的大语言模型(LLM)推理能力,蒸馏到一个高效的纯视觉学生模型中。
- 核心目标是在保持甚至超越教师模型性能的前提下,大幅降低模型的计算开销,使其适用于实际部署。
- 解决了VLA模型因参数量巨大而导致的推理延迟高、内存占用大等问题,特别是在复杂交互场景的闭环评估中。
Card 03
核心贡献
核心贡献
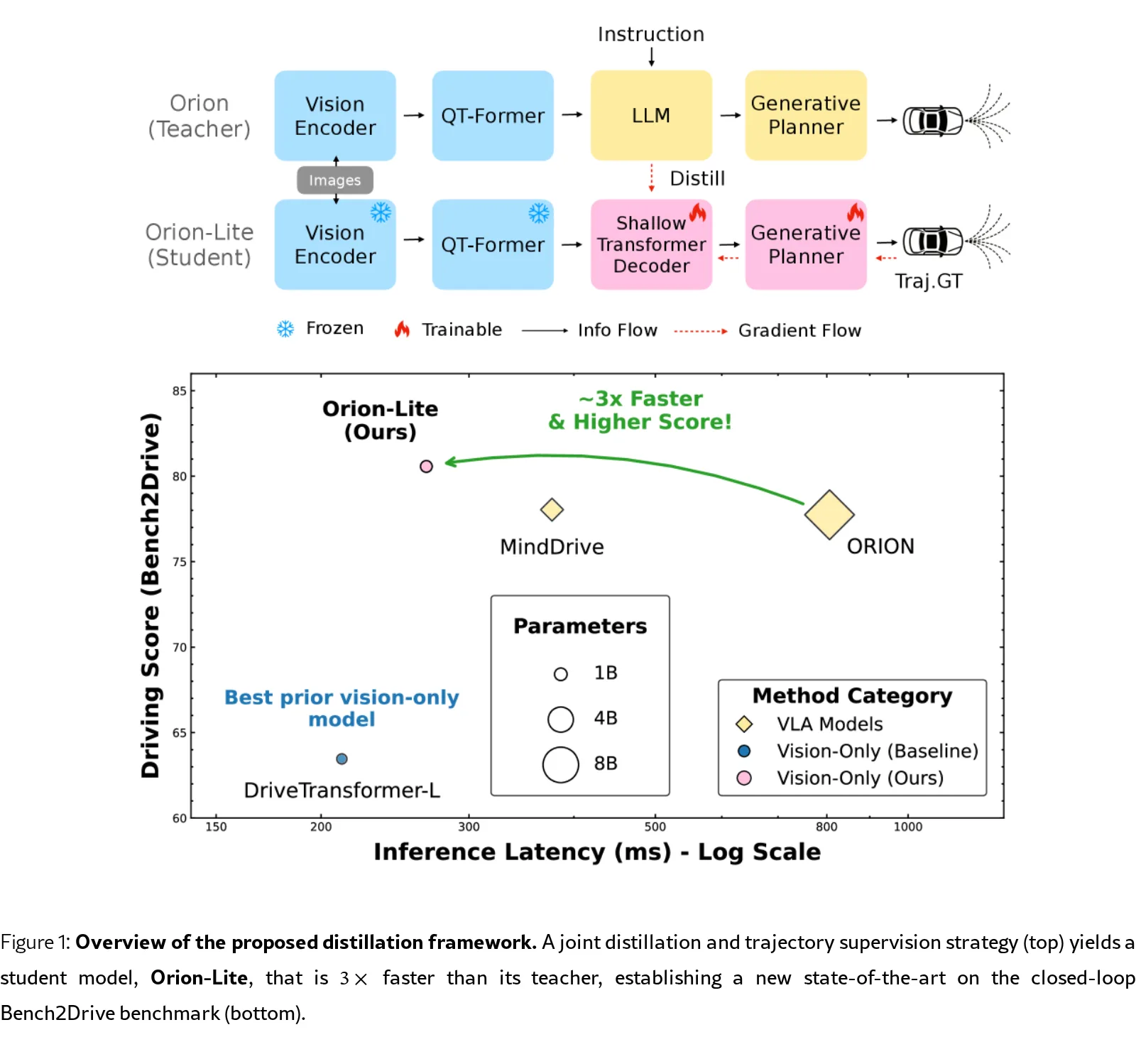
- 架构简化:证明了一个紧凑的轻量级 Transformer 解码器可以替代VLA模型中7B参数的LLM,而不损失在挑战性闭环基准上的性能。
- 建立新的纯视觉模型基准:提出的模型在严格的Bench2Drive闭环基准上取得了新的最佳性能,超越了其VLA教师模型以及其他基于强化学习和世界模型的竞争方法。
- 高效推理能力:学生模型的推理速度比教师模型快150倍,整体系统速度提升3倍,GPU显存占用从31GB降至8GB。
Card 04
方法描述
方法描述
- 采用一个知识蒸馏框架,将教师模型(ORION)LLM生成的潜在规划特征作为蒸馏目标。
- 学生模型包含一个轻量级的 Transformer 解码器,通过交叉注意力机制从冻结的视觉编码器和时空模块提取的特征中学习。
- 创新性地采用特征模仿损失(L1回归)与真实轨迹监督相结合的联合训练策略,有效压缩了推理能力并提升了学生模型的泛化性。
Card 05
数据集与资源
数据集与资源
- 使用 Bench2Drive 数据集进行训练和闭环评估。
- 学生模型参数量从教师模型的 7B LLM参数 缩减为 0.1B参数。
- 训练资源为单张 RTX A6000 GPU,训练时长约20小时。
Card 06
评估与结果
评估与结果
- 评估环境为 CARLA 模拟器上的 Bench2Drive 闭环基准,包含44个复杂交互场景。
- 主要评估指标包括 驾驶分数 (DS)、成功率 (SR) 以及多项驾驶能力指标。
- 关键实验结果:学生模型 Orion-Lite 达到了 80.6 DS 和 55.5% SR,在驾驶分数和多能力均值上均超越了 ORION 教师模型(77.7 DS, 54.6% SR),并显著优于其他基准方法。