一眼看懂
封面预览
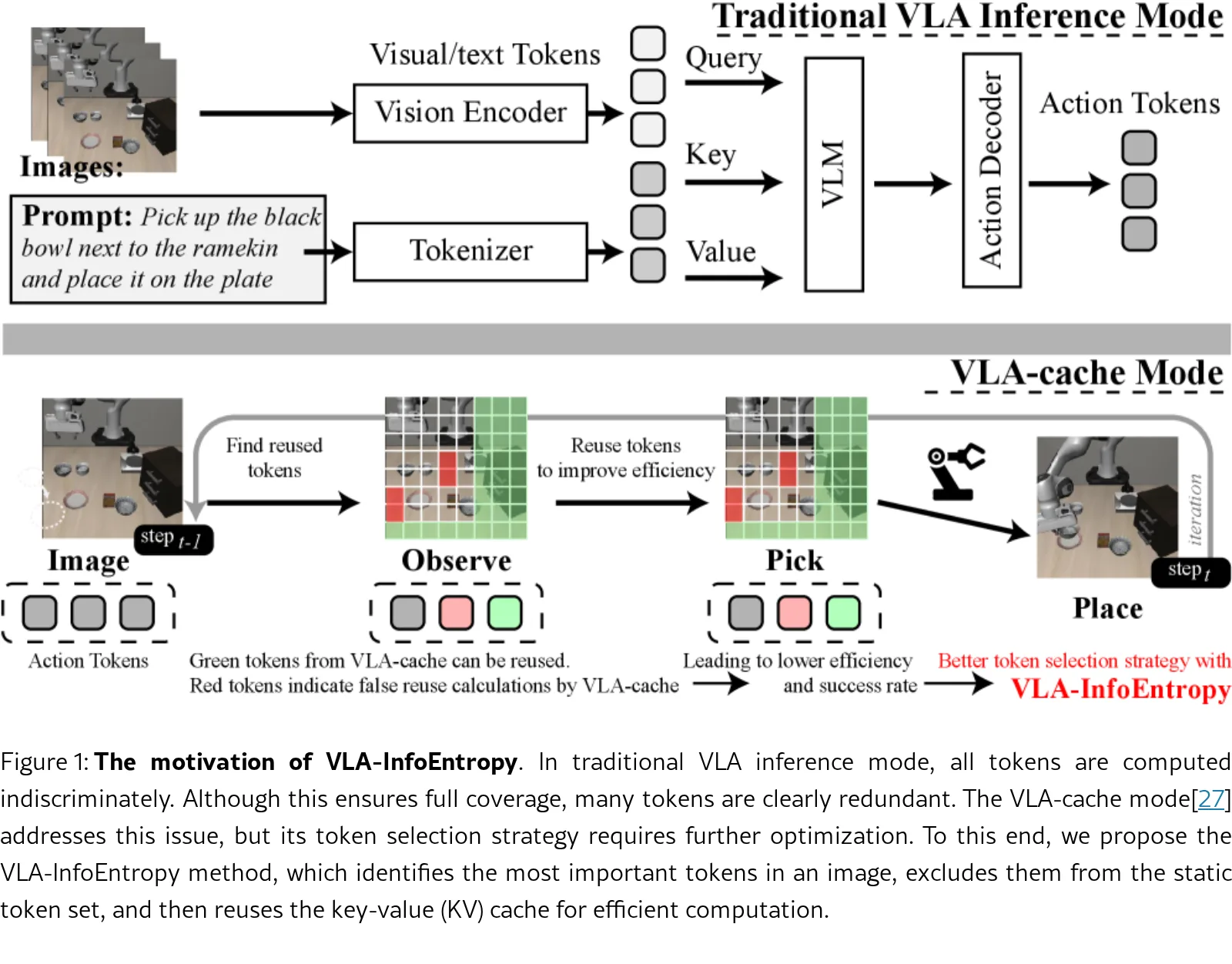
针对 Vision-Language-Action (VLA) 模型推理效率低、计算开销大且难以实时部署的问题提出解决方案
- 针对 Vision-Language-Action (VLA) 模型推理效率低、计算开销大且难以实时部署的问题提出解决方案
- 提出一种免训练的推理加速框架 VLA-InfoEntropy,利用信息熵度量动态筛选重要 token
- 通过整合空间视觉特征、语义相关性和时间步信息,动态调整模型关注点以减少冗余计算
Card 01
研究单位
研究单位
- 论文作者包括 Chuhang Liu, Yayun He, Zuheng Kang, Xiaoyang Qu 和 Jianzong Wang
- 通讯作者为 Jianzong Wang,所属项目受 Shenzhen-Hong Kong Joint Funding Project 支持(具体机构名称在原文片段中未显式列出)
Card 02
论文概述
论文概述
- 针对 Vision-Language-Action (VLA) 模型推理效率低、计算开销大且难以实时部署的问题提出解决方案
- 提出一种免训练的推理加速框架 VLA-InfoEntropy,利用信息熵度量动态筛选重要 token
- 通过整合空间视觉特征、语义相关性和时间步信息,动态调整模型关注点以减少冗余计算
Card 03
核心贡献
核心贡献
- 引入 视觉熵 和 注意力熵 两种免训练的互补指标,量化视觉 token 的内部信息量与语义相关性
- 提出 VLA-InfoEntropy 动态选择策略,结合时间步感知建模,实现从全局视觉感知到局部语义聚焦的平滑过渡
- 设计基于熵引导的 token 排除与 KV 缓存复用机制,有效保留关键内容并降低推理冗余
Card 04
方法描述
方法描述
- 利用 图像熵 计算视觉 token 的灰度分布随机性,识别纹理丰富或边缘清晰的区域作为视觉显著候选
- 利用 注意力熵 分析跨模态注意力分数分布,低熵表示注意力集中于任务相关文本,以此识别任务相关 token
- 设计随时间步 $t$ 变化的动态分配策略,早期侧重高视觉熵的 全局特征,后期侧重低注意力熵的 局部细节
- 将筛选出的重要 token 从静态集合中排除,剩余低信息量 token 通过 KV Cache 复用实现高效计算
Card 05
数据集与资源
数据集与资源
- 使用 LIBERO 基准进行评估,涵盖 LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和 LIBERO-Long 四个任务套件
- 实验在单块 NVIDIA RTX 4090 GPU 上进行
- 关键参数设置为动态步数 $T=100$,视觉与注意力 token 数量比例参数 $k_1=40$ 和 $k_2=60$
Card 06
评估与结果
评估与结果
- 对比基准包括 OpenVLA、SparseVLM、FastV、VLA-Cache、SP-VLA 和 Spec-VLA
- 主要评估指标包括任务成功率、推理延迟、浮点运算量 和加速比
- 实验表明该方法平均成功率达到 76.4%,FLOPs 减少 34.9%,CUDA 延迟降低 39.8%,推理速度提升 1.53倍
- 消融实验验证了视觉熵、注意力熵及时间步动态机制对维持高性能和加速效果的关键作用