一眼看懂
封面预览
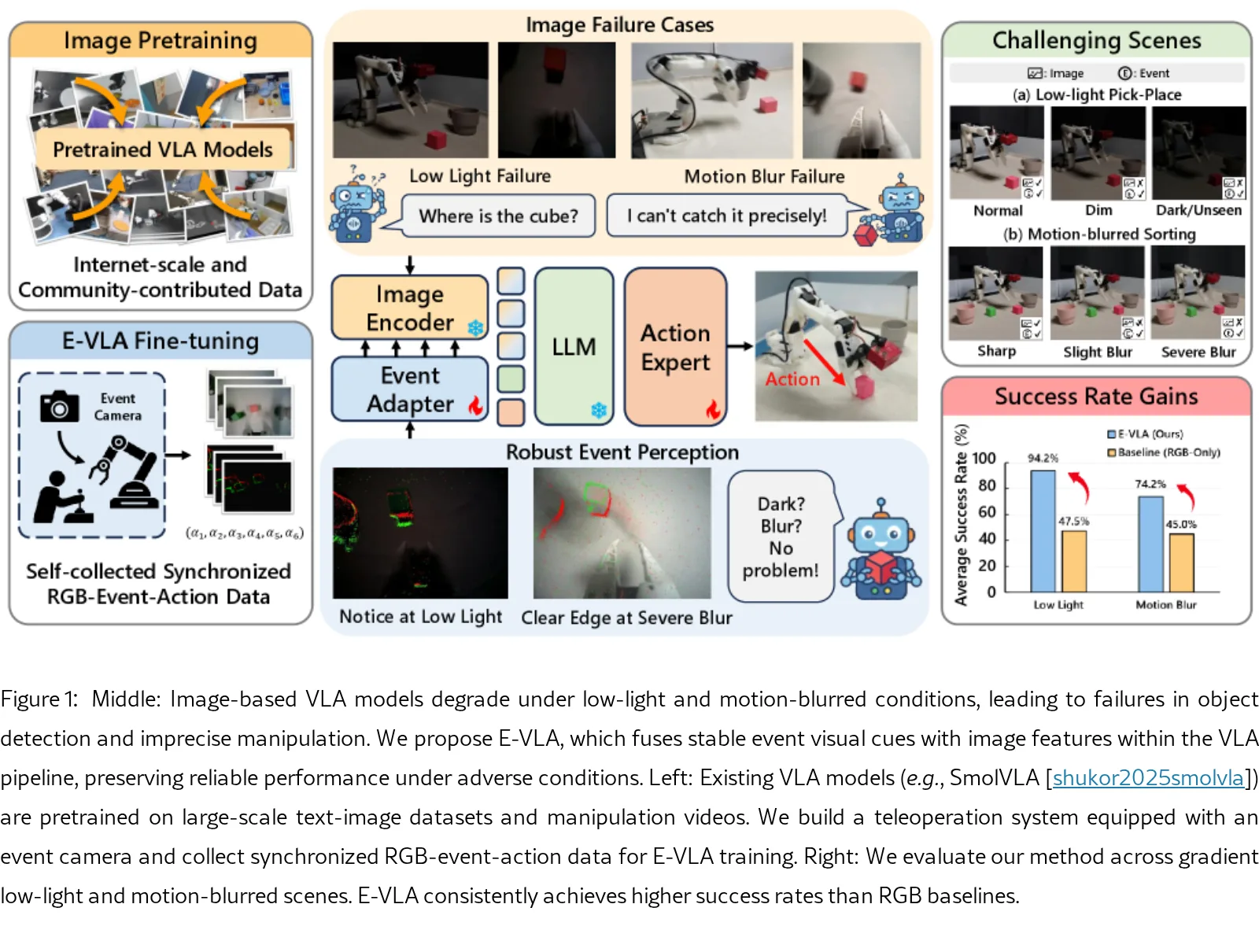
提出了 E-VLA,一种事件增强的视觉-语言-动作框架,旨在解决现有 VLA 模型在极端低光照和运动模糊场景下的感知脆弱性问题。
- 提出了 E-VLA,一种事件增强的视觉-语言-动作框架,旨在解决现有 VLA 模型在极端低光照和运动模糊场景下的感知脆弱性问题。
- 该方法直接利用事件流中的运动和结构线索,而不是从事件重建图像,从而在不利的视觉条件下保持语义感知和感知-动作的一致性。
- 构建了一个开源遥操作平台,收集了真实世界的同步 RGB-事件-动作数据集,验证了事件驱动感知在 VLA 模型中的有效性。
Card 01
研究单位
研究单位
- Zhejiang University
- Ant Group
- Hunan University
Card 02
论文概述
论文概述
- 提出了 E-VLA,一种事件增强的视觉-语言-动作框架,旨在解决现有 VLA 模型在极端低光照和运动模糊场景下的感知脆弱性问题。
- 该方法直接利用事件流中的运动和结构线索,而不是从事件重建图像,从而在不利的视觉条件下保持语义感知和感知-动作的一致性。
- 构建了一个开源遥操作平台,收集了真实世界的同步 RGB-事件-动作数据集,验证了事件驱动感知在 VLA 模型中的有效性。
Card 03
核心贡献
核心贡献
- 提出了首个整合事件视觉感知的 E-VLA 框架,用于增强机器人在低光照和运动模糊条件下的操作鲁棒性。
- 构建了开源事件增强遥操作平台,并收集了包含多任务和多种光照条件的真实世界同步 RGB-事件-动作数据集。
- 设计了轻量级且兼容预训练模型的事件融合策略,包括无参数的叠加融合和分层事件适配器。
- 提供了系统性的实证证据和设计见解,证明了事件驱动感知可有效集成到可扩展的 VLA 学习中。
Card 04
方法描述
方法描述
- 基于 SmolVLA 架构作为基线模型,利用事件相机捕获的异步数据增强视觉感知。
- 设计了基于事件计数而非固定时间间隔的窗口化策略,以适应机器人操作中运动速度变化导致的非平稳时间分布。
- 提出了两种融合策略:一是参数-free 的 Overlay-based fusion,直接将事件叠加到 RGB 图像上;二是轻量级的 Hierarchical Event Adapter,将事件特征注入到视觉编码器的中间层进行细粒度交互。
Card 05
数据集与资源
数据集与资源
- 使用了 SO100 6-DoF 机械臂和 DAVIS346 事件相机构建遥操作平台。
- 自建数据集包含 Pick-Place、Sorting 和 Stacking 三种任务,覆盖正常光照(200 lux)和低光照(100, 75, 40 lux)条件。
- 数据集包含 724 个演示片段,总计 339310 帧。
- 训练使用单卡 NVIDIA A800 GPU,推理部署在 NVIDIA AGX Orin 平台上。
Card 06
评估与结果
评估与结果
- 在真实机器人平台上进行评估,对比了 RetinexNet、Retinexformer、EvLight 和 E2VID 等图像增强或重建基线。
- 主要评估指标为任务成功率(Task Success Rate)。
- 在极低光照(20 lux)下,E-VLA (Event Adapter) 的 Pick-Place 任务成功率从基线的 0% 提升至 90%。
- 在严重运动模糊(1000 ms 曝光)下,Sorting 任务成功率从 5% 提升至 32.5%。
- 在未见过的低光照场景(OOD)测试中,仅在正常光照训练的模型在 20 lux 下仍保持 45% 的成功率,证明了良好的泛化能力。