一眼看懂
封面预览
本文揭示了视觉-语言-动作(VLA)模型对物理上可实现的对抗性3D纹理攻击存在关键安全漏洞。
- 本文揭示了视觉-语言-动作(VLA)模型对物理上可实现的对抗性3D纹理攻击存在关键安全漏洞。
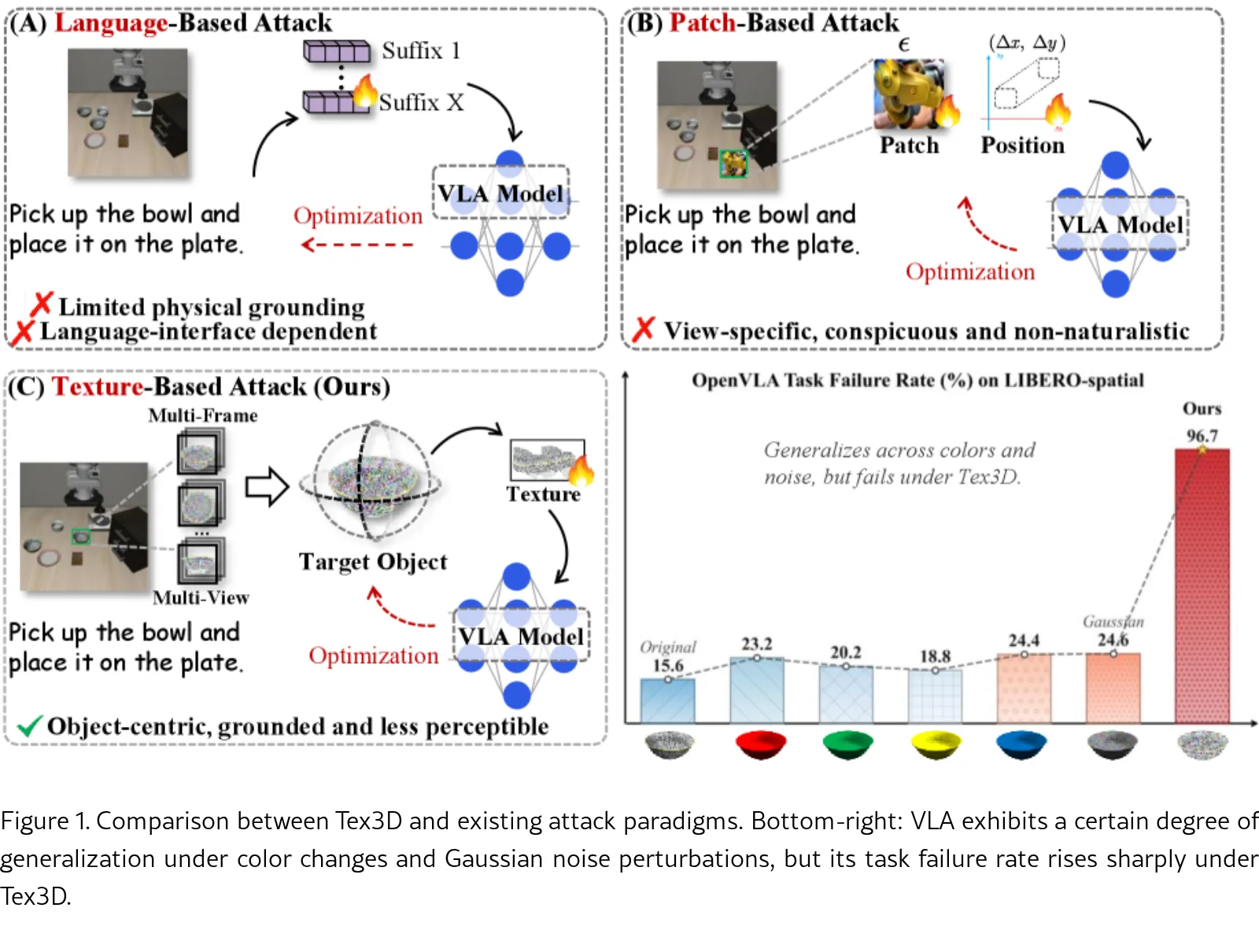
- 论文旨在开发一种更物理可信、更不易察觉的攻击面,即直接绑定在物体表面的对抗性3D纹理,以替代现有的2D补丁攻击。
- 研究目标是实现首个能在VLA模拟环境中端到端优化3D纹理的攻击框架,并验证其在仿真和真实机器人环境中的有效性。
Card 01
研究单位
研究单位
- 华东师范大学
- 中关村学院
- **CFAR, A*STAR, Singapore**
- 清华大学
- 哈尔滨工业大学
Card 02
论文概述
论文概述
- 本文揭示了视觉-语言-动作(VLA)模型对物理上可实现的对抗性3D纹理攻击存在关键安全漏洞。
- 论文旨在开发一种更物理可信、更不易察觉的攻击面,即直接绑定在物体表面的对抗性3D纹理,以替代现有的2D补丁攻击。
- 研究目标是实现首个能在VLA模拟环境中端到端优化3D纹理的攻击框架,并验证其在仿真和真实机器人环境中的有效性。
Card 03
核心贡献
核心贡献
- 提出了Tex3D框架,这是首个在VLA仿真环境中实现对抗性3D纹理端到端优化的工作。
- 引入了前景-背景解耦(FBD) 技术,通过跨渲染器对齐解决了仿真环境不可微分的问题,建立了梯度优化路径。
- 提出了轨迹感知对抗优化(TAAO) 算法,通过识别行为关键帧和顶点参数化,确保了长时序攻击的有效性。
- 在仿真和真实机器人场景中进行了全面评估,揭示了VLA模型高达96.7% 的任务失败率,突显了其脆弱性。
Card 04
方法描述
方法描述
- 采用前景-背景解耦(FBD) 策略,使用MuJoCo渲染环境背景,同时使用Nvdiffrast可微分渲染器渲染目标物体。
- 通过精确同步几何参数(MVP变换)和光照参数,实现跨渲染器的空间与光度一致性对齐。
- 提出轨迹感知对抗优化(TAAO),利用视觉编码器输出的潜在动态速度和加速度识别关键帧,并使用温度缩放的softmax加权优化。
- 采用顶点参数化将纹理映射为顶点颜色属性,约束优化在平滑低秩流形上,减少过拟合,提升跨视角攻击效果。
Card 05
数据集与资源
数据集与资源
- 使用LIBERO机器人操作基准作为仿真环境,包含四种任务变体。
- 评估模型包括OpenVLA、OpenVLA-OFT和π₀三种代表性的开源VLA模型。
- 实验涵盖了仿真评估和真实机器人部署,验证了攻击的物理可实现性。
Card 06
评估与结果
评估与结果
- 评估基准为LIBERO基准中的四种任务变体,在无目标和有目标攻击设置下进行测试。
- 主要评估指标为任务失败率,衡量攻击导致任务失败的比例。
- 在OpenVLA模型上,Tex3D在目标攻击中平均失败率达到90.5%,最高达96.7%。
- 在π₀模型上,平均失败率达到75.9%,验证了攻击对不同架构VLA模型的有效性。
- 结果表明Tex3D攻击显著优于Gaussian噪声和单帧攻击等基线方法,揭示了当前VLA模型对物理3D攻击的严重脆弱性。