一眼看懂
封面预览
研究针对 视觉-语言-动作 (VLA) 模型在机器人操作微调中存在的泛化能力差和样本效率低的问题
- 研究针对 视觉-语言-动作 (VLA) 模型在机器人操作微调中存在的泛化能力差和样本效率低的问题
- 指出现有方法直接沿用语言模型训练范式,忽略了物理动作的内在容差特性,即存在一个可行动作邻域 (FAN)
- 提出一种 FAN-guided 正则化方法,通过引入高斯先验塑造策略输出分布,使其符合 FAN 的几何特性,以提升样本效率和泛化能力
Card 01
研究单位
研究单位
- 上海交通大学 (Shanghai Jiao Tong University, China)
- 华为技术有限公司 (Huawei Technologies, China)
Card 02
论文概述
论文概述
- 研究针对 视觉-语言-动作 (VLA) 模型在机器人操作微调中存在的泛化能力差和样本效率低的问题
- 指出现有方法直接沿用语言模型训练范式,忽略了物理动作的内在容差特性,即存在一个可行动作邻域 (FAN)
- 提出一种 FAN-guided 正则化方法,通过引入高斯先验塑造策略输出分布,使其符合 FAN 的几何特性,以提升样本效率和泛化能力
Card 03
核心贡献
核心贡献
- 形式化了 可行动作邻域 (FAN) 的概念,刻画了物理动作的局部容差结构,揭示了标准语言式 VLA 训练与物理动作几何特性之间的内在不匹配
- 提出了一种适用于 监督微调 (SFT) 和 强化微调 (RFT) 的 FAN-guided 正则化方法,在保持 VLA 模型离散性和自回归特性的同时,显式地将训练目标与物理操作的容差特性对齐
- 在 SFT 和 RFT 两种范式下进行了广泛评估,覆盖多种 VLA 主干网络和操作任务,验证了该方法在样本效率、任务成功率和 OOD 泛化方面的显著提升
Card 04
方法描述
方法描述
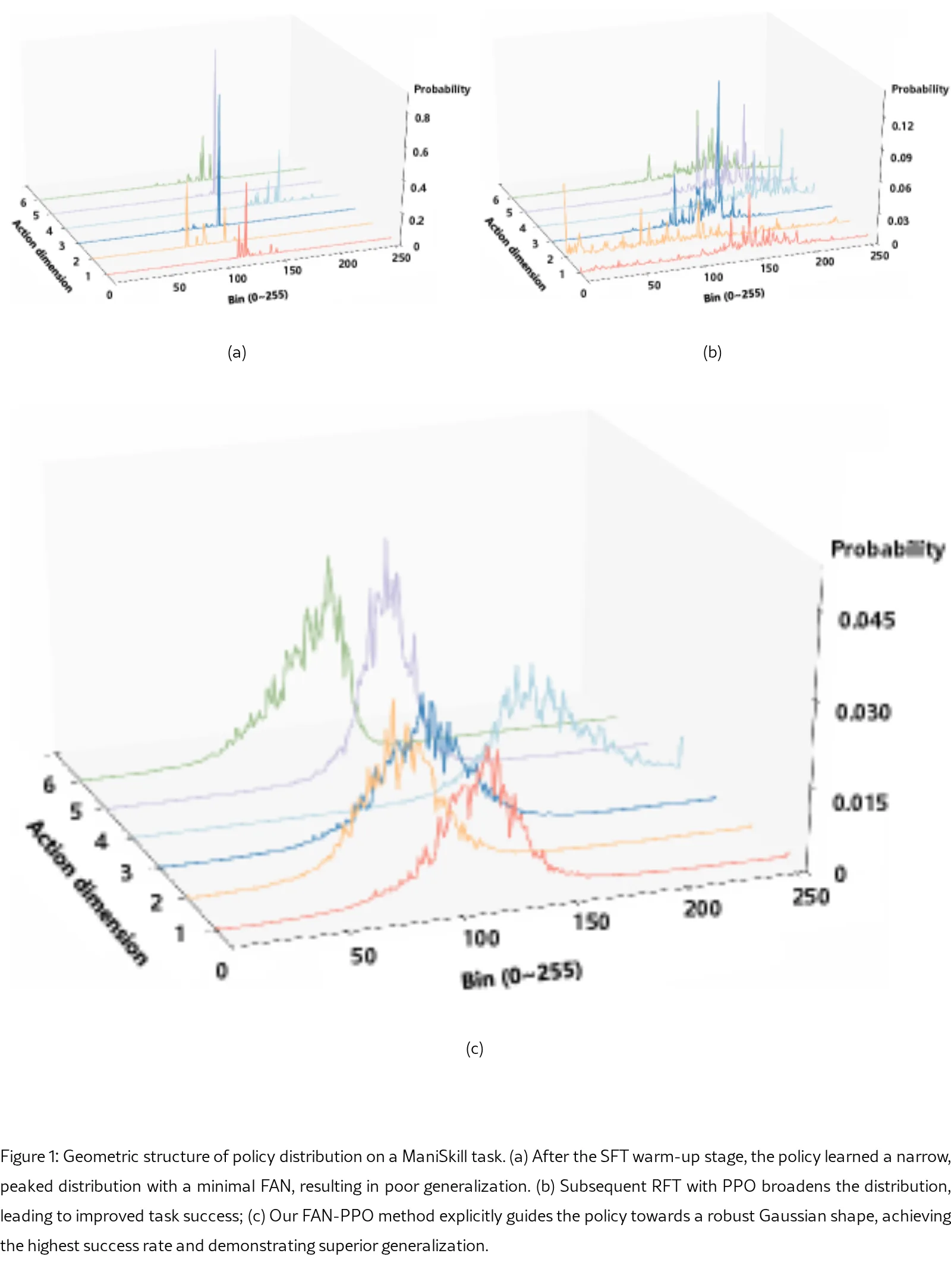
- 核心思想是将策略分布塑造为一个平滑、单峰的高斯形状,以反映 FAN 的局部连续性和平滑性
- 设计了一个正则化项,定义为策略分布 π 与目标高斯分布 N(μ(s), Σ(s)) 之间的 KL 散度
- 在 SFT 中,使用动态协方差矩阵 Σ(s),由策略自身方差定义,以适应当前几何特性
- 在 RFT 中,使用固定协方差矩阵 Σ=σ²I 以确保训练稳定性,并将该正则化项集成到信任域策略优化目标中,推导出最优策略的闭式解
Card 05
数据集与资源
数据集与资源
- 使用了两个机器人操作基准:ManiSkill 和 LIBERO
- 评估了两种代表性 VLA 模型:OpenVLA (输出单个动作) 和 OpenVLA-OFT (输出动作块)
- 实验在 NVIDIA A100 GPU (80GB 内存) 上进行
Card 06
评估与结果
评估与结果
- 在 SFT 设置下,FAN-SFT 在 ManiSkill 基准上相比标准 SFT,ID 任务成功率提升 +11.7%,OOD 任务平均成功率提升 +5.2%
- 在 LIBERO-Spatial 任务中,FAN-SFT 显著提升了模型对位置偏移的鲁棒性,成功率在扰动下从 0.24 提升至 0.36
- 在 RFT 设置下,FAN-PPO 相比标准 PPO,在 OpenVLA 上 OOD 平均成功率提升 +6.2%,在 OpenVLA-OFT 上提升 +7.9%
- 实验证明该方法在不同数据规模下均有效,并在空间扰动等 OOD 场景下展现出更强的泛化能力