一眼看懂
封面预览
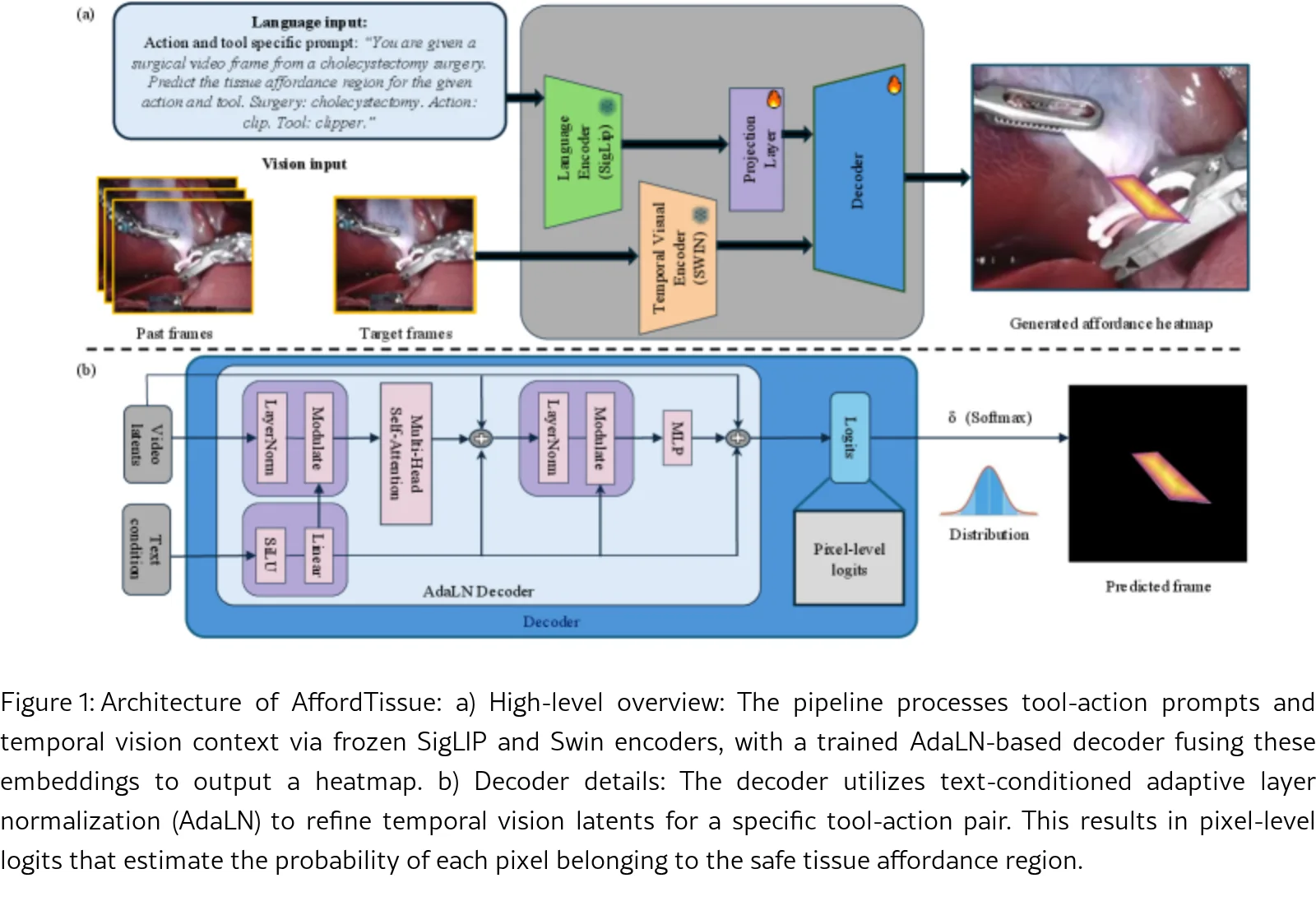
论文提出了 AffordTissue,一个多模态框架,用于在胆囊切除术中预测工具-动作特定的组织可供性区域,以密集热图形式呈现
- 论文提出了 AffordTissue,一个多模态框架,用于在胆囊切除术中预测工具-动作特定的组织可供性区域,以密集热图形式呈现
- 解决了当前手术自动化方法在器械与组织表面交互位置预测性不足、缺乏显式条件输入来强制安全交互区域的问题
- 目标是为安全手术自动化提供显式的空间推理,实现策略引导和安全停止机制
Card 01
研究单位
研究单位
- Johns Hopkins University, Baltimore MD, USA
Card 02
论文概述
论文概述
- 论文提出了 AffordTissue,一个多模态框架,用于在胆囊切除术中预测工具-动作特定的组织可供性区域,以密集热图形式呈现
- 解决了当前手术自动化方法在器械与组织表面交互位置预测性不足、缺乏显式条件输入来强制安全交互区域的问题
- 目标是为安全手术自动化提供显式的空间推理,实现策略引导和安全停止机制
Card 03
核心贡献
核心贡献
- 引入密集组织可供性预测作为新任务,提供关于工具-动作特定可供性区域的显式空间推理
- 提出多模态架构,生成工具-动作条件化的可供性热图,用于动作引导和安全验证
- 整理和标注103个胆囊切除术视频,建立了首个组织可供性基准数据集
- 结合时序视觉编码器、语言条件化和DiT风格解码器,实现密集热图预测
- 相比VLM基线模型有显著提升(ASSD为20.6像素 vs. Molmo-VLM的60.2像素)
Card 04
方法描述
方法描述
- 使用 SigLIP 2 作为语言编码器,嵌入包含手术三元组(手术类型、工具类型、动作类型)的文本提示
- 使用 Video Swin Transformer 作为时序视频编码器,捕获跨多视角的时空视觉信息
- 使用 AdaLN 解码器(源自DiT),针对密集热图预测任务进行适配,融合视觉和语言嵌入
- 输入N=256帧(步长为8),约10.6秒的历史上下文,捕获工具运动和组织动态
- 训练时冻结语言和视觉编码器,仅优化解码器参数
Card 05
数据集与资源
数据集与资源
- 自建数据集包含 15,638 个视频片段,来自 103 个胆囊切除术视频
- 数据来源:Youtube(21个)、Cholec-80(34个)、HeiChole(11个)、CHEC(8个)、SurgVU(29个)
- 涵盖6种工具-动作对:分离-钩、分离-抓钳、分离-剪刀、抓持-抓钳、夹闭-夹闭器、剪切-剪刀
- 每个案例手动标注4个关键点勾勒安全交互区域
- 在单张 NVIDIA A100 GPU 上训练100个epoch
Card 06
评估与结果
评估与结果
- 基线对比:Molmo-VLM、SAM3、Qwen-VLM(8B)
- 评估指标:DICE分数、PCK@0.05、PCK@0.1、豪斯多夫距离(HD)、平均对称表面距离(ASSD)
- 主要结果:ASSD为 20.557 px,PCK@0.05为 0.517,PCK@0.1为 0.667
- 相比最强基线Molmo-VLM(ASSD 60.184 px),ASSD性能提升 192.76%
- 消融实验验证了语言编码器、时序视觉编码器和AdaLN解码器的重要性