一眼看懂
封面预览
论文提出了 Uni-World VLA,一个统一的视觉-语言-动作(VLA)模型,旨在解决自动驾驶中世界建模与轨迹规划分离导致的开环想象偏差问…
- 论文提出了 Uni-World VLA,一个统一的视觉-语言-动作(VLA)模型,旨在解决自动驾驶中世界建模与轨迹规划分离导致的开环想象偏差问…
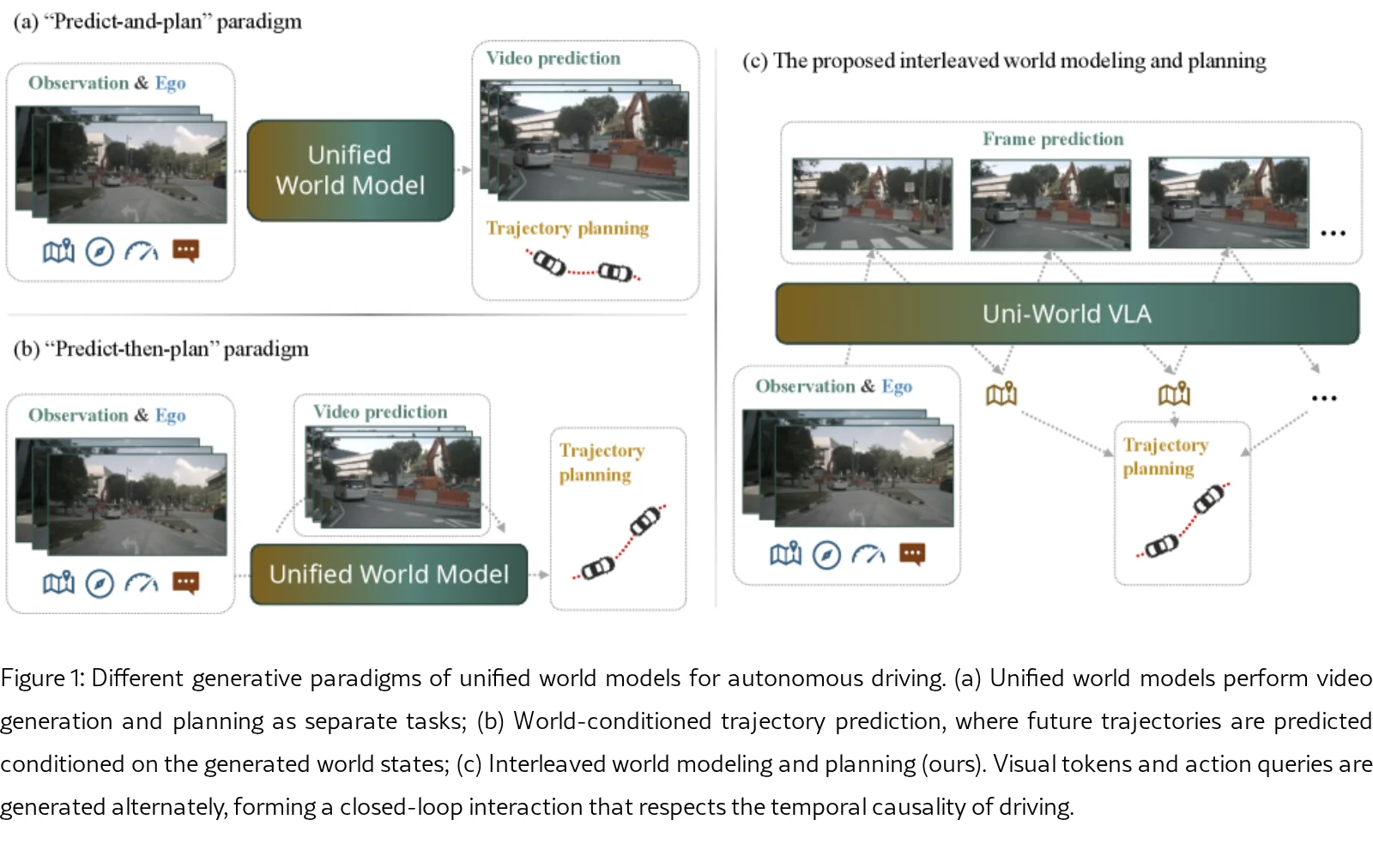
- 核心思想是采用交织生成范式(Interleaved World Modeling and Planning),交替执行未来帧预测和自车动作规划…
- 引入单目深度信息作为几何线索,通过交叉注意力机制融合历史帧特征,提升长视野场景预测的质量。
Card 01
研究单位
研究单位
- Fudan University
- Shanghai Innovation Institute
- Li Auto Inc.
- University of Surrey
Card 02
论文概述
论文概述
- 论文提出了 Uni-World VLA,一个统一的视觉-语言-动作(VLA)模型,旨在解决自动驾驶中世界建模与轨迹规划分离导致的开环想象偏差问题。
- 核心思想是采用交织生成范式(Interleaved World Modeling and Planning),交替执行未来帧预测和自车动作规划,形成闭环交互以适应动态交通场景。
- 引入单目深度信息作为几何线索,通过交叉注意力机制融合历史帧特征,提升长视野场景预测的质量。
Card 03
核心贡献
核心贡献
- 提出了交织建模与规划范式,构建统一的自回归架构,交替生成视觉令牌和动作令牌,使规划决策能持续基于预测的未来观测进行修正。
- 设计了深度整合策略,利用 Depth Anything 3 提取深度图并通过交叉注意力融合几何特征,增强了未来帧预测的空间感知能力。
- 在 NAVSIM 基准上进行了广泛实验,证明了该方法在闭环规划性能(PDMS)和视频生成质量(FVD)上均达到了竞争性或最优水平。
Card 04
方法描述
方法描述
- 模型基于 Show-o(多模态大语言模型)和 MagVIT-v2(视频令牌器)构建,将历史观测编码为离散令牌(Contextual Tokens 和 Dynamic Tokens)。
- 采用自回归方式交替生成未来帧的动态令牌($\hat{d}_{t+k}$)和对应时刻的动作令牌($\hat{a}_{t+k}$),利用因果注意力掩码处理时序依赖,利用双向帧内注意力处理空间依赖。
- 训练目标结合了视觉预测的动态焦点损失(Dynamic Focal Loss,强调变化区域)和轨迹预测的 L1 损失。
- 深度信息通过专门的编码器(CDE 和 DDE)提取特征,并与视觉令牌通过交叉注意力机制进行深度融合。
Card 05
数据集与资源
数据集与资源
- 使用 NAVSIM 数据集进行训练和评估,并在消融研究中使用了 nuPlan 补充高频轨迹数据。
- 模型初始化自 Policy World Model (PWM) 和 Show-o,视觉令牌器采用预训练的 MagVIT-v2。
- 训练使用 32 NVIDIA H20 GPUs,输入为单目前视图相机,批大小为 3,训练分为两个阶段(特征提取预训练和多模态联合训练)。
Card 06
评估与结果
评估与结果
- 在 NAVSIM 测试集上进行评估,规划性能指标为 PDMS(包含 NC, DAC, EP, TTC, Comfort),视频生成质量指标为 FVD。
- Uni-World VLA 取得了最高的 PDMS (89.4),在 EP (83.2) 和 TTC (96.1) 子指标上均达到最佳,优于其他 World Model 方法(如 ResWorld, PWM)。
- 视频生成质量方面,该方法取得了最低的 FVD (141.8),优于 DrivingGPT (142.6) 和 GenAD (184.0),证明了其在生成高保真未来帧的同时能实现更优的规划安全性。