一眼看懂
封面预览
论文提出 ENAP(Emergent Neural Automaton Policy)框架,旨在从视觉运动演示中无监督地学习双层神经符号策略
- 论文提出 ENAP(Emergent Neural Automaton Policy)框架,旨在从视觉运动演示中无监督地学习双层神经符号策略
- 核心目标是解决机器人长期任务学习中的挑战:端到端策略缺乏结构先验,传统神经符号方法依赖手工设计的符号先知
- 通过从数据中自动涌现出可解释的状态机结构与低级反应式网络,实现高样本效率与可解释性
Card 01
研究单位
研究单位
- 论文作者隶属于 Carnegie Mellon University 的 Robotics Institute
Card 02
论文概述
论文概述
- 论文提出 ENAP(Emergent Neural Automaton Policy)框架,旨在从视觉运动演示中无监督地学习双层神经符号策略
- 核心目标是解决机器人长期任务学习中的挑战:端到端策略缺乏结构先验,传统神经符号方法依赖手工设计的符号先知
- 通过从数据中自动涌现出可解释的状态机结构与低级反应式网络,实现高样本效率与可解释性
Card 03
核心贡献
核心贡献
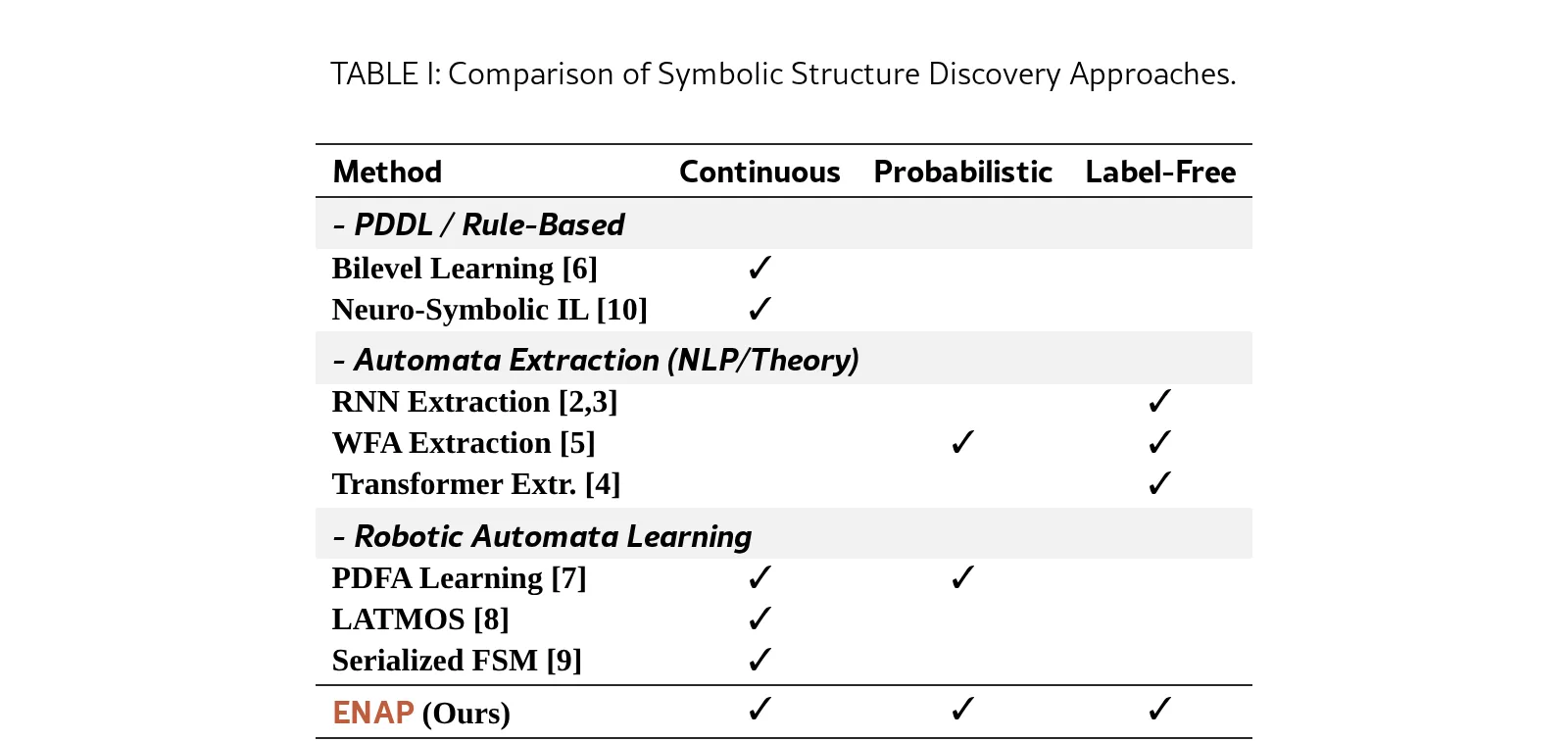
- 提出 ENAP 框架,以涌现的方式学习结构化任务抽象与低级反应网络,为从端到端推理向分层认知架构演进提供了可行路径
- 设计了一种无标签神经符号框架,消除了对专家先知的依赖,通过自适应符号抽象促进结构发现,提升了可解释性与组合性
- 实验证明 ENAP 在低数据设置下相比 VLA 模型性能提升至少 8%,且参数量减少 39%,并提供了基于 POMDP 的理论依据
Card 04
方法描述
方法描述
- 采用自适应聚类与 **扩展 L* 算法 从轨迹数据中推断 概率 Mealy 机**,作为可解释的高级规划器捕捉隐式任务模式
- 利用 RNN 编码器 将变长历史序列映射为固定大小嵌入,作为离散状态的连续代理,以处理机器人轨迹的时序特性
- 将学习到的离散状态机与下游残差补偿网络结合,通过行为克隆学习完整策略,形成双层控制架构
Card 05
数据集与资源
数据集与资源
- 使用了复杂操作任务(如 PegInsertionSide、DualStackCube)与长期 TAMP 任务(如 Sequential、Hierarchical)
- 包含真实世界操作实验(如 Hanger、MultiPickPlace、StackLego)
- 原文中未明确说明具体的模型参数规模、训练轮次或使用的计算资源(如 GPU/TPU)
Card 06
评估与结果
评估与结果
- 评估基准包括复杂操作任务、长期规划任务与真实世界实验,对比 VLA 模型 等先进方法
- 主要评估指标为任务成功率,并分析涌现结构的可解释性、恢复能力与泛化性
- 关键结果显示:ENAP 在低数据场景下性能超越 SoTA VLA 策略高达 27%,参数量减少 39%,同时提供结构化的机器人意图表示