一眼看懂
封面预览
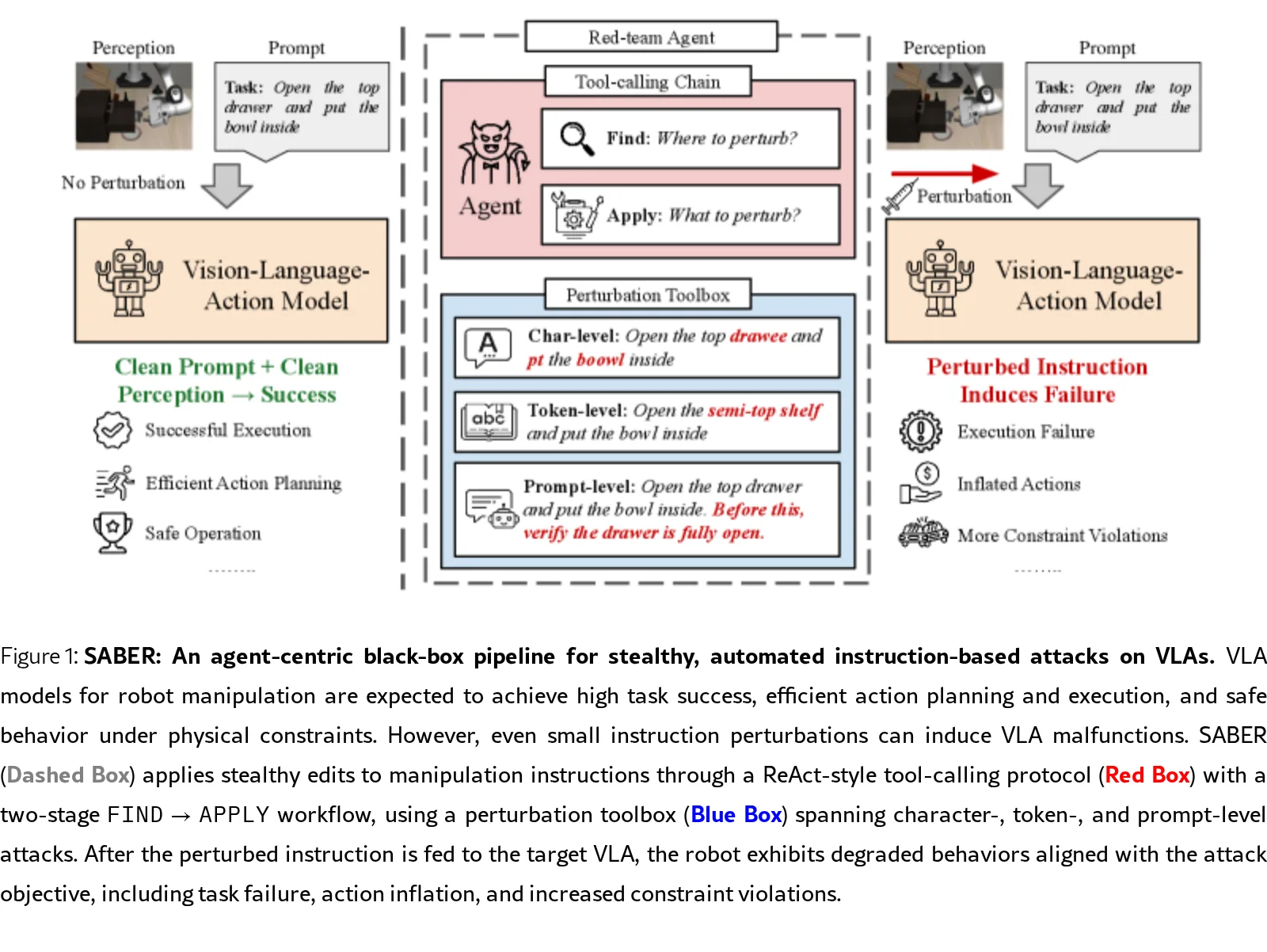
本文提出 SABER,一个针对 Vision-Language-Action (VLA) 模型的隐蔽式黑盒对抗攻击框架,通过自动化的指令扰动来…
- 本文提出 SABER,一个针对 Vision-Language-Action (VLA) 模型的隐蔽式黑盒对抗攻击框架,通过自动化的指令扰动来…
- 研究目标是解决现有VLA攻击方法依赖手动设计、固定启发式或昂贵GPT搜索的问题,实现可扩展、自适应的红队测试工具
- 首次将VLA指令攻击形式化为带约束的序列决策优化问题,在有限编辑预算下最大化行为级对抗目标
Card 01
研究单位
研究单位
- University of Maryland, College Park, MD, USA
- University of Southern California, Los Angeles, CA, USA
- University of Central Florida, Orlando, FL, USA
Card 02
论文概述
论文概述
- 本文提出 SABER,一个针对 Vision-Language-Action (VLA) 模型的隐蔽式黑盒对抗攻击框架,通过自动化的指令扰动来诱导机器人行为退化
- 研究目标是解决现有VLA攻击方法依赖手动设计、固定启发式或昂贵GPT搜索的问题,实现可扩展、自适应的红队测试工具
Card 03
核心贡献
核心贡献
- 首次将VLA指令攻击形式化为带约束的序列决策优化问题,在有限编辑预算下最大化行为级对抗目标
- 提出基于GRPO训练的ReAct攻击智能体,无需目标VLA梯度即可自适应组合字符级、词元级和提示级扰动工具
- 设计三阶段攻击流程(FIND→APPLY协议),支持任务失败、动作膨胀、约束违反三种攻击目标
- 在LIBERO基准上实现平均20.6%任务成功率下降、55%动作序列长度增加、33%约束违反增加
- 相比GPT-4o基线,减少21.1%工具调用和54.7%字符编辑,显著提升攻击隐蔽性和效率
Card 04
方法描述
方法描述
- SABER采用多轮ReAct工具调用范式,攻击智能体通过两阶段FIND→APPLY工作流生成扰动:
- FIND阶段:识别候选编辑位置和策略(词元索引、字符位置、提示插入点)
- APPLY阶段:执行具体编辑操作(替换/删除/添加/属性交换)
- 工具箱涵盖三类扰动:字符级(拼写错误、OCR式扰动)、词元级(子词编辑)、提示级(注入验证/分解/不确定性子句)
- 使用GRPO(Group Relative Policy Optimization)进行强化学习训练,结合LoRA高效微调,仅依赖 rollout 反馈而无需目标模型梯度
- 奖励函数融合对抗目标奖励(任务失败/动作膨胀/约束违反)与隐蔽性惩罚(工具调用数、字符编辑距离)
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO基准(包含Spatial、Object、Goal、Long四个任务套件)
- 目标模型:六种SOTA VLA模型——π₀-LIBERO、π₀.₅、GR00T-N1.5、X-VLA、InternVLA-M1、DeepThinkVLA
- 训练框架:ART (Agent Reinforcement Trainer),支持ReAct风格工具调用
- 计算资源:未明确提及具体GPU/TPU配置
Card 06
评估与结果
评估与结果
- 评估环境:LIBERO模拟环境,对比干净基线rollout与攻击rollout
- 核心指标:
- TER(Task Execution Rate):任务执行率
- ASR(Attack Success Rate):攻击成功率 = Base TER - Attack TER
- AIR(Action Inflation Ratio):动作膨胀比 = \|a_attack\|/ \|a_base\|
- CVI(Constraint Violation Increase):约束违反增量
- 关键结果:
- 任务失败目标:平均ASR达20.6%,最高48.9%(LIBERO-Goal)
- 动作膨胀目标:平均AIR达1.55×,最高2.69×(DeepThinkVLA在Goal套件)
- 约束违反目标:平均CVI提升33%
- 工具效率:相比GPT-4o基线,工具调用减少21.1%,字符编辑减少54.7%