一眼看懂
封面预览
研究如何将 VGGT 提供的3D几何信息有效集成到视觉-语言-动作模型中,以解决现有模型因主要在2D数据上预训练而导致的3D空间感知不足问题。
- 研究如何将 VGGT 提供的3D几何信息有效集成到视觉-语言-动作模型中,以解决现有模型因主要在2D数据上预训练而导致的3D空间感知不足问题。
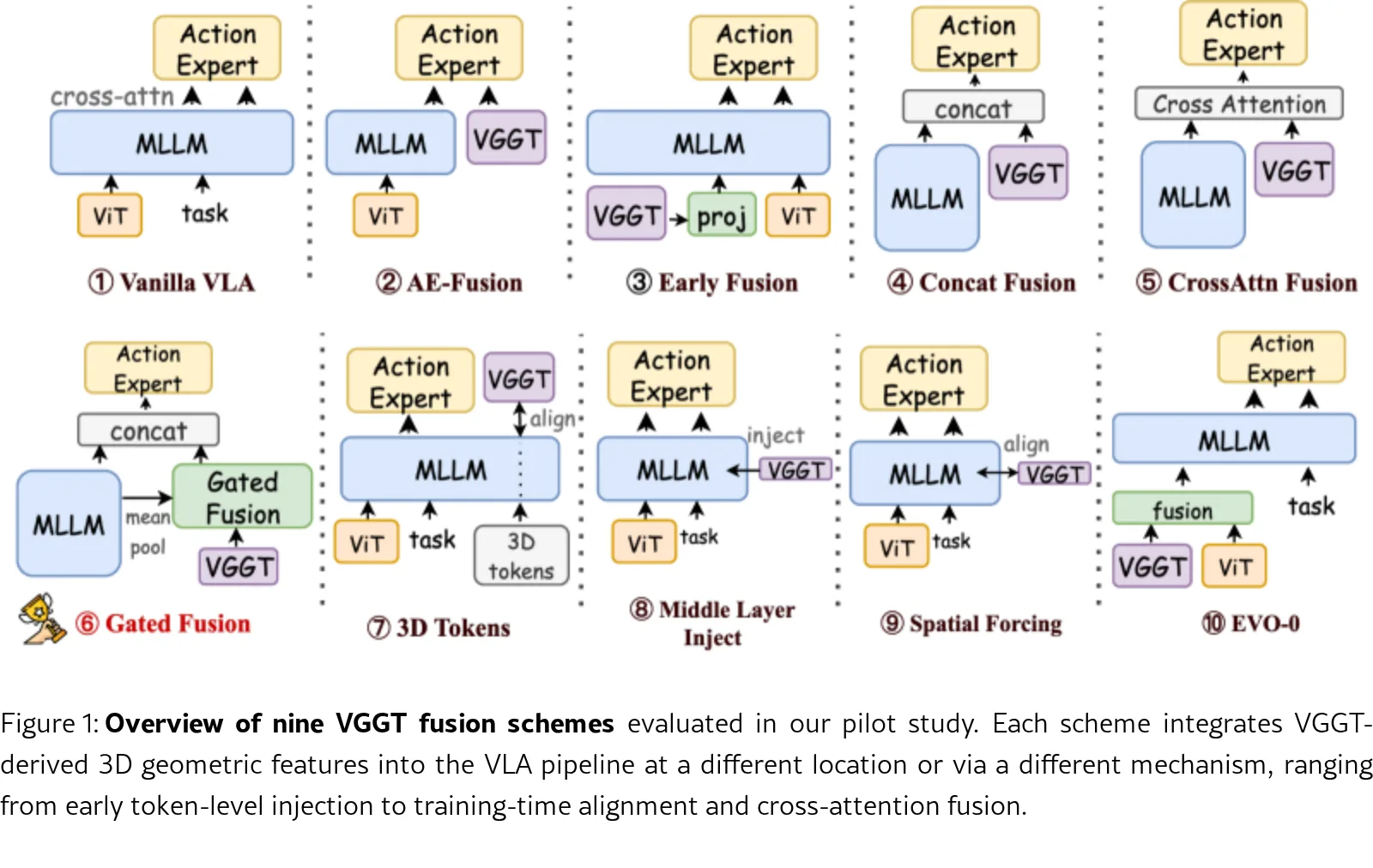
- 通过系统比较九种 VGGT 融合策略,发现 语义条件门控融合 效果最佳,并据此提出即插即用模块 3D-Mix。
- 旨在为增强VLA模型的空间智能提供一种原则性强、即插即用且广泛适用的解决方案。
Card 01
研究单位
研究单位
- 哈尔滨工业大学 (HIT)
- 中关村创新中心 (ZGCA)
- 中关村创新研究院 (ZGCI)
- 华中科技大学 (HUST)
- 香港科技大学 (广州) (HKUST(GZ))
- 北京航空航天大学 (BUAA)
- 华东师范大学 (ECNU)
- DeepCybo
Card 02
论文概述
论文概述
- 研究如何将 VGGT 提供的3D几何信息有效集成到视觉-语言-动作模型中,以解决现有模型因主要在2D数据上预训练而导致的3D空间感知不足问题。
- 通过系统比较九种 VGGT 融合策略,发现 语义条件门控融合 效果最佳,并据此提出即插即用模块 3D-Mix。
- 旨在为增强VLA模型的空间智能提供一种原则性强、即插即用且广泛适用的解决方案。
Card 03
核心贡献
核心贡献
- 首次对VLA模型中的 VGGT 集成方案进行了系统性研究,评估了九种融合策略。
- 提出了轻量级即插即用模块 3D-Mix,通过自适应门控机制实现2D语义与3D几何特征的原则性融合。
- 在多种VLA架构和MLLM骨干网络上验证了 3D-Mix 的通用性和有效性,提供了实用的实施指南。
Card 04
方法描述
方法描述
- 3D-Mix 模块基于语义条件自适应门控原理工作,动态融合来自MLLM的2D语义特征和来自 VGGT 的3D几何特征。
- 核心创新在于使用一个可学习的门控网络,该网络基于全局语义上下文和局部几何特征,为每个空间位置计算位置特定的融合权重。
- 该模块作为MLLM与动作专家之间的桥梁,无需修改现有模型内部组件即可集成到 GR00T-style 和 π-style 等不同VLA架构中。
Card 05
数据集与资源
数据集与资源
- 训练数据集:Open X-Embodiment 数据集中的 BridgeV2 子集。
- 评估基准:SIMPLER(域外、real-to-sim基准)和 LIBERO(域内多任务基准)。
- 模型规模:评估了六种MLLM系列的九个模型变体,参数量在 2B–8B 之间。
- 训练资源:使用 8× NVIDIA H100 GPU 进行训练,采用 DeepSpeed ZeRO-2 优化。
Card 06
评估与结果
评估与结果
- 评估环境:在 GR00T-style 和 π-style 两种VLA架构上进行评估。
- 主要指标:任务平均成功率。
- 关键结果:3D-Mix 在所有评估的MLLM骨干网络上均带来一致的性能提升。在 GR00T-style 架构上,于域外 SIMPLER 基准上九个变体平均提升 +7.0%,其中 RynnBrain-8B 提升高达 +12.51%。在 π-style 架构上也取得了显著的性能提升。