一眼看懂
封面预览
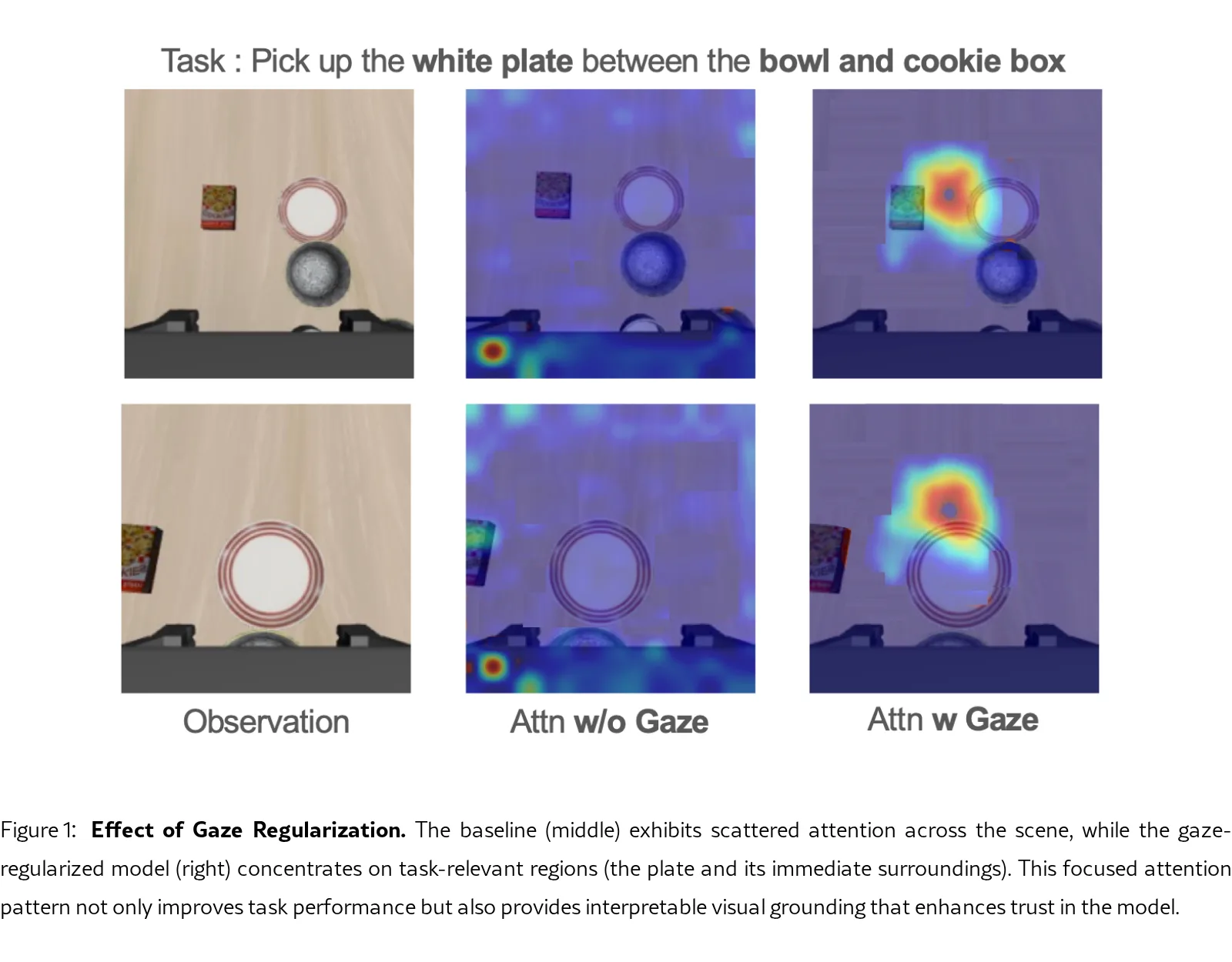
论文针对当前视觉-语言-动作(VLA)模型在机器人精细操作任务中因缺乏主动视觉注意力分配机制而表现不佳的问题,提出了一种注视正则化训练框架。
- 论文针对当前视觉-语言-动作(VLA)模型在机器人精细操作任务中因缺乏主动视觉注意力分配机制而表现不佳的问题,提出了一种注视正则化训练框架。
- 该框架利用人类注视模式作为监督信号,在训练时引导模型的内部注意力关注任务相关区域,而无需修改模型架构或增加推理时开销。
- 核心目标是将VLA模型从被动观察者转变为主动感知者,提升其操作性能、学习效率和可解释性。
Card 01
研究单位
研究单位
- 香港大学数据科学学院
Card 02
论文概述
论文概述
- 论文针对当前视觉-语言-动作(VLA)模型在机器人精细操作任务中因缺乏主动视觉注意力分配机制而表现不佳的问题,提出了一种注视正则化训练框架。
- 该框架利用人类注视模式作为监督信号,在训练时引导模型的内部注意力关注任务相关区域,而无需修改模型架构或增加推理时开销。
- 核心目标是将VLA模型从被动观察者转变为主动感知者,提升其操作性能、学习效率和可解释性。
Card 03
核心贡献
核心贡献
- 提出了一个注视正则化训练框架,首次将时间聚合的人类注视先验作为训练时的正则化信号,引导VLA模型的视觉注意力。
- 该方法作为即插即用的模块,可直接应用于现有VLA架构(如Pi-0和OpenVLA),无需架构修改或推理时依赖眼动追踪设备。
- 通过在多个仿真基准和真实机器人上的广泛实验证明,该方法能显著提升任务成功率(4-12%)、加速训练收敛并增强对视觉扰动的鲁棒性。
Card 04
方法描述
方法描述
- 使用预训练的GLC网络为机器人数据生成合成注视热图,并通过时间聚合捕获“扫描-计划-行动”序列。
- 将连续的注视热图转换为与Transformer视觉标记空间对齐的离散概率分布。
- 设计基于KL散度的正则化损失,在训练时对齐模型内部的空间注意力分布与人类注视分布,从而注入关注任务相关区域的归纳偏置。
Card 05
数据集与资源
数据集与资源
- 主要评估数据集:LIBERO 套件(包括Spatial, Object, Goal, LIBERO-10)、ALOHA-Sim。
- 核心实验基于 Pi-0 和 OpenVLA 两种VLA模型架构。
- 真实世界实验在物理机器人上完成,包含短期和长期操作任务。
Card 06
评估与结果
评估与结果
- 评估基准包括仿真环境(LIBERO、ALOHA-Sim)和真实世界机器人平台。
- 主要评估指标为任务成功率。
- 在LIBERO-Spatial基准上,注视正则化模型最终成功率达到95.5%,相较基线模型的85.9%提升了9.6%。
- 在跨架构测试中,该方法为OpenVLA模型带来了平均5.7%的性能提升。
- 真实机器人实验表明,该方法在短期任务上成功率提升8%,在长期任务上提升10%。