一眼看懂
封面预览
论文旨在解决视觉-语言-动作模型 在资源受限平台上推理成本高的问题,提出了一种无需训练的视觉标记剪枝方法。
- 论文旨在解决视觉-语言-动作模型 在资源受限平台上推理成本高的问题,提出了一种无需训练的视觉标记剪枝方法。
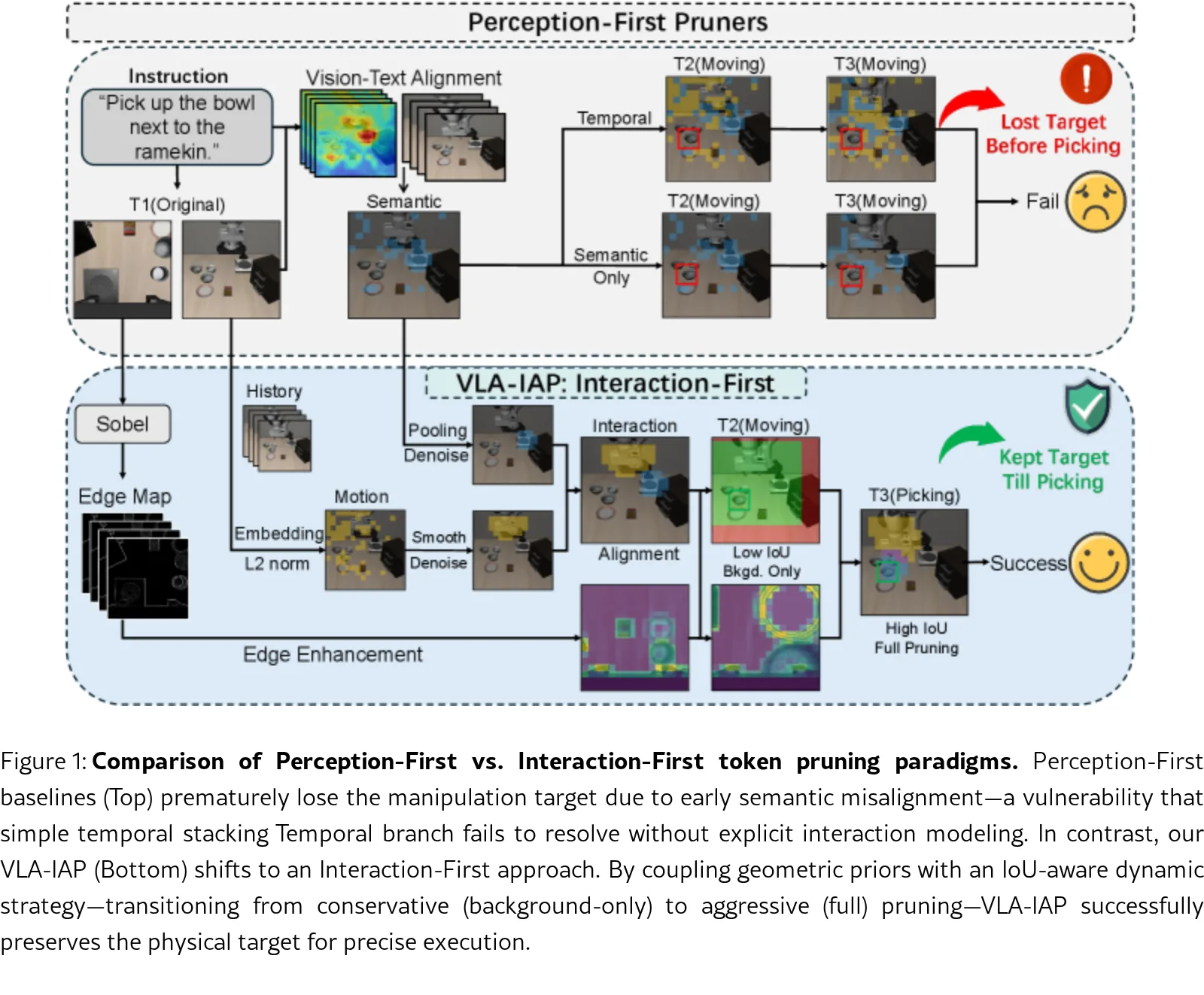
- 指出现有剪枝方法主要依赖语义显著性或简单时序线索,忽略了VLA任务中关键的连续物理交互,导致关键操作区域被错误剪枝。
- 提出向“交互优先”范式转变,通过几何先验和语义-运动对齐的动态策略,确保任务早期的鲁棒性和锁定交互后的效率。
Card 01
研究单位
研究单位
- 香港科技大学 (The Hong Kong University of Science and Technology)
- 香港中文大学 (The Chinese University of Hong Kong)
- 华南师范大学 (South China Normal University)
- 国防科技大学 (National University of Defense Technology)
- 北京科技大学 (University of Science and Technology Beijing)
Card 02
论文概述
论文概述
- 论文旨在解决视觉-语言-动作模型 在资源受限平台上推理成本高的问题,提出了一种无需训练的视觉标记剪枝方法。
- 指出现有剪枝方法主要依赖语义显著性或简单时序线索,忽略了VLA任务中关键的连续物理交互,导致关键操作区域被错误剪枝。
- 提出向“交互优先”范式转变,通过几何先验和语义-运动对齐的动态策略,确保任务早期的鲁棒性和锁定交互后的效率。
Card 03
核心贡献
核心贡献
- 提出了 几何先验机制,通过轻量级边缘增强显式提取物理轮廓,纠正模型偏向语义外观而忽略可操作几何特征的倾向。
- 提出了 交互对齐动态策略,利用语义与运动掩码的IoU度量评估交互锁定状态,动态切换保守与激进剪枝模式。
- 在三个仿真基准(LIBERO, VLABench, CALVIN)和真实机器人平台上进行了广泛验证,证明了方法的优越性、泛化能力和实用性。
Card 04
方法描述
方法描述
- 方法整体为训练自由 的框架,在视觉编码器提取标记后,并行评估语义、运动和几何三个维度的物理重要性。
- 几何先验通过Sobel算子提取图像边缘强度,聚合到标记级别,形成独立于VLM语义空间的物理可供性图。
- 语义-运动对齐模块构建语义先验(文本-图像注意力)和运动先验(二阶时序差分),并计算其IoU作为动态策略的门控信号。
- 根据IoU阈值动态切换剪枝模式:低IoU时采用保守模式(双弱排斥策略保留非背景信息),高IoU时采用激进模式(收缩语义掩码并联合运动掩码移除冗余背景)。
- 最终标记选择通过融合几何先验得分与动态策略产生的保留集,生成精简的视觉序列输入LLM进行动作推理。
Card 05
数据集与资源
数据集与资源
- 仿真基准:LIBERO, VLABench, CALVIN (ABC-D)。
- 真实机器人任务:单臂(简单、长视野)和双臂(协同分类)操作任务。
- 基础VLA模型:OpenVLA-OFT, DreamVLA, π₀ 和 π₀.₅。
- 实验硬件:NVIDIA A100 GPU。
Card 06
评估与结果
评估与结果
- 在 LIBERO 基准上,方法实现了 97.8%的成功率,同时带来了 1.25倍的加速。
- 在 OpenVLA-OFT 上,实现了高达 1.54倍的加速,且性能与未剪枝的骨干模型相当。
- 在真实机器人实验中,实现了高达 1.48倍的推理加速,同时提高了平均操作成功率。
- 方法在多个模型架构和不同仿真环境中表现出优越且一致的性能,验证了其强大的泛化能力。