一眼看懂
封面预览
论文提出了 RoboAlign,一个用于训练多模态大语言模型(MLLM)的系统化框架,旨在可靠地提升视觉-语言-动作模型(VLA)的性能。
- 论文提出了 RoboAlign,一个用于训练多模态大语言模型(MLLM)的系统化框架,旨在可靠地提升视觉-语言-动作模型(VLA)的性能。
- 核心目标是解决现有MLLM通过语言监督进行具身推理微调后,无法稳定转化为VLA性能提升,甚至导致性能下降的问题。
- 该方法通过将低级动作词元作为具身推理的直接结果进行采样,并利用强化学习(RL)优化推理过程以提升动作准确性,从而弥合语言与低级动作之间的模态鸿…
Card 01
研究单位
研究单位
- 作者所属单位未在提供的HTML文本中明确列出。
Card 02
论文概述
论文概述
- 论文提出了 RoboAlign,一个用于训练多模态大语言模型(MLLM)的系统化框架,旨在可靠地提升视觉-语言-动作模型(VLA)的性能。
- 核心目标是解决现有MLLM通过语言监督进行具身推理微调后,无法稳定转化为VLA性能提升,甚至导致性能下降的问题。
- 该方法通过将低级动作词元作为具身推理的直接结果进行采样,并利用强化学习(RL)优化推理过程以提升动作准确性,从而弥合语言与低级动作之间的模态鸿沟。
Card 03
核心贡献
核心贡献
- 提出了 RoboAlign 两阶段训练框架,首先通过有监督微调(SFT)使MLLM具备通过零样本推理生成FAST动作词元的能力,然后利用GRPO强化学习算法进一步优化推理与动作的对齐。
- 设计了新颖的奖励函数,结合格式奖励和动作词元预测的准确率奖励,直接以低级动作准确性为优化目标,引导模型生成更精准的执行动作。
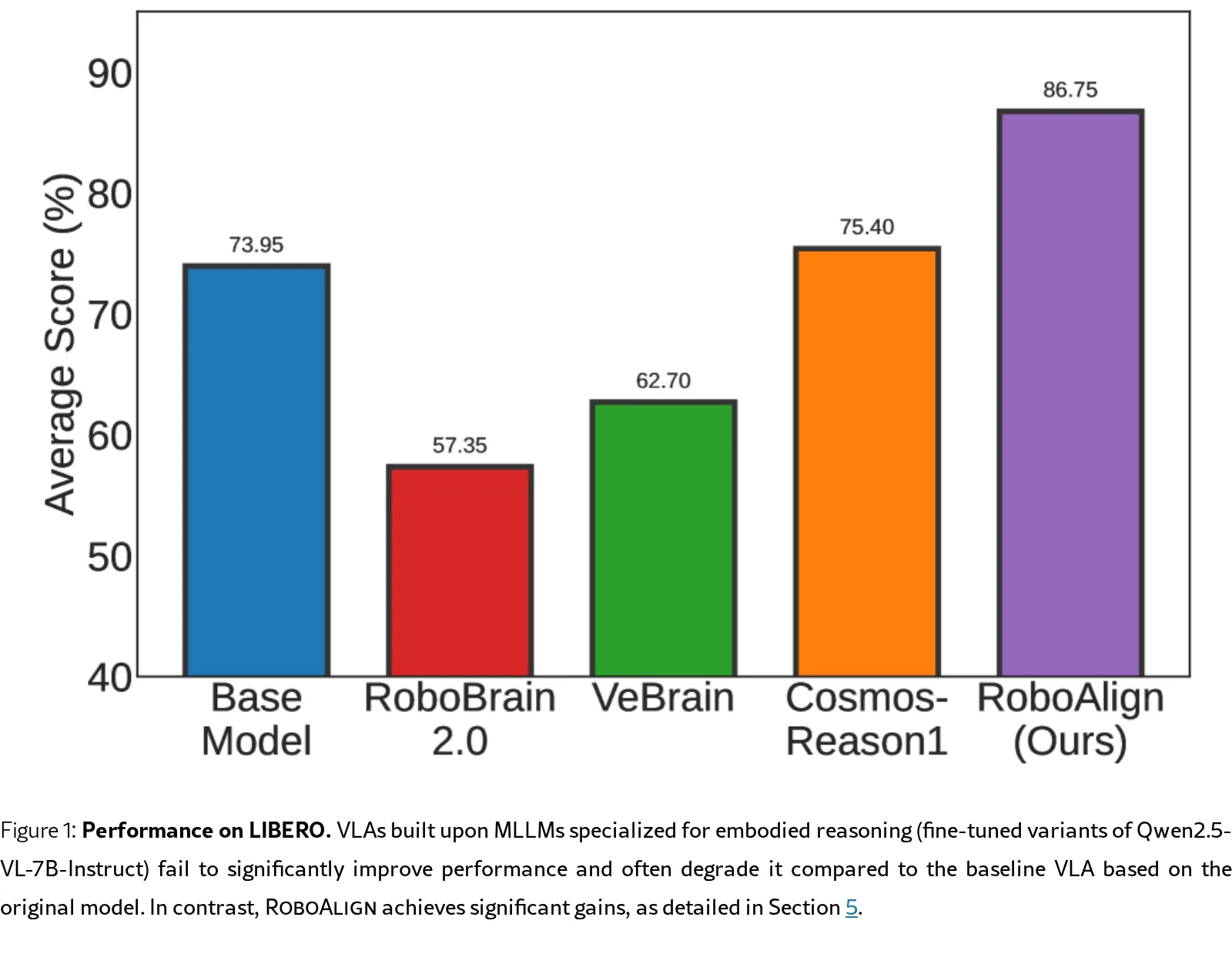
- 实验证明,RoboAlign 仅需在SFT之后使用不到1%的数据进行RL对齐,即在 LIBERO、CALVIN 和真实机器人环境中,相比SFT基线实现了17.5%、18.9%和106.6%的性能提升。
- 验证了该方法的有效性优于其他对齐策略(如高级语言动作预测、视觉轨迹预测和SFT联合训练),并能提升MLLM在通用视觉问答和具身推理基准上的性能。
Card 04
方法描述
方法描述
- 采用 FAST 分词技术将连续的低级动作(末端执行器状态序列)转换为离散词元,集成到MLLM词表中。
- 提出两阶段训练流程:阶段1 (SFT) 使用混合数据集(包括开源SFT数据、自定义 RoboAlign VQA、推理数据集和 BridgeV2 的FAST词元数据)训练模型,使其能通过零样本思维链生成动作词元。
- 阶段2 (RL) 使用GRPO算法,基于格式正确性和动作词元序列前缀相似度构成的奖励函数,对模型进行微调,直接优化动作生成的准确性。
Card 05
数据集与资源
数据集与资源
- SFT阶段 使用了约 2.28M 样本的混合数据集,包含 LLaVA-OneVision、RefSpatial、RoboPoint、ShareRobot、RoboVQA 以及自定义的 RoboAlign VQA 和 BridgeV2 FAST词元数据。
- RL阶段 使用了 BridgeV2 数据集中 12.8K 样本的子集进行强化学习训练。
- 基础模型为 Qwen2.5-VL-7B-Instruct,部分实验也使用了 Qwen3-VL-8B-Instruct。
- 模型训练使用了 8×H200 GPU,SFT耗时约30小时,RL耗时约1小时。VLA训练使用 2×A100 GPU。
Card 06
评估与结果
评估与结果
- 在模拟环境 LIBERO(4个类别,每类500次试验)和 CALVIN(连续任务链,1000次试验)以及真实机器人设置(4项任务,每项96次试验)中进行评估。
- 主要评估指标为任务成功率。在 LIBERO 上,RoboAlign 相比SFT基线平均成功率从73.9%提升至 86.8%,尤其在长期任务上从63.2%提升至 70.0%。
- 在 CALVIN 上,平均成功序列长度从2.32提升至 2.57,尤其在长度为5的任务上成功率从18.1%提升至 22.2%。
- 在真实机器人实验中,平均成功率从32.3%提升至 66.7%,证明了方法的实际有效性。
- 消融实验表明,该方法在兼容不同模型架构、对比其他对齐策略和SFT方法上均表现优越,并显著提升了模型表征区分状态信息的能力。