一眼看懂
封面预览
研究目标:解决 Vision Language Action(VLA)模型在面对干扰物(distractors)和物理障碍(obstructi…
- 研究目标:解决 Vision Language Action(VLA)模型在面对干扰物(distractors)和物理障碍(obstructi…
- 核心方法:提出 StageCraft,一种无需训练的(training-free)方法,通过视觉语言模型(VLM)的上下文推理能力来操纵环境的…
- 主要成果:在三个真实世界任务领域中对 Pi0.5 和 SmolVLA 模型实现了 绝对 40% 的性能提升
Card 01
研究单位
研究单位
- Arizona State University - Kartikay Milind Pangaonkar、Prabin Rath、Omkar Patil、Nakul Gopalan(等贡献)
Card 02
论文概述
论文概述
- 研究目标:解决 Vision Language Action(VLA)模型在面对干扰物(distractors)和物理障碍(obstructions)时容易失败的问题
- 核心方法:提出 StageCraft,一种无需训练的(training-free)方法,通过视觉语言模型(VLM)的上下文推理能力来操纵环境的初始状态,移除可能导致策略执行失败的对象
- 主要成果:在三个真实世界任务领域中对 Pi0.5 和 SmolVLA 模型实现了 绝对 40% 的性能提升
Card 03
核心贡献
核心贡献
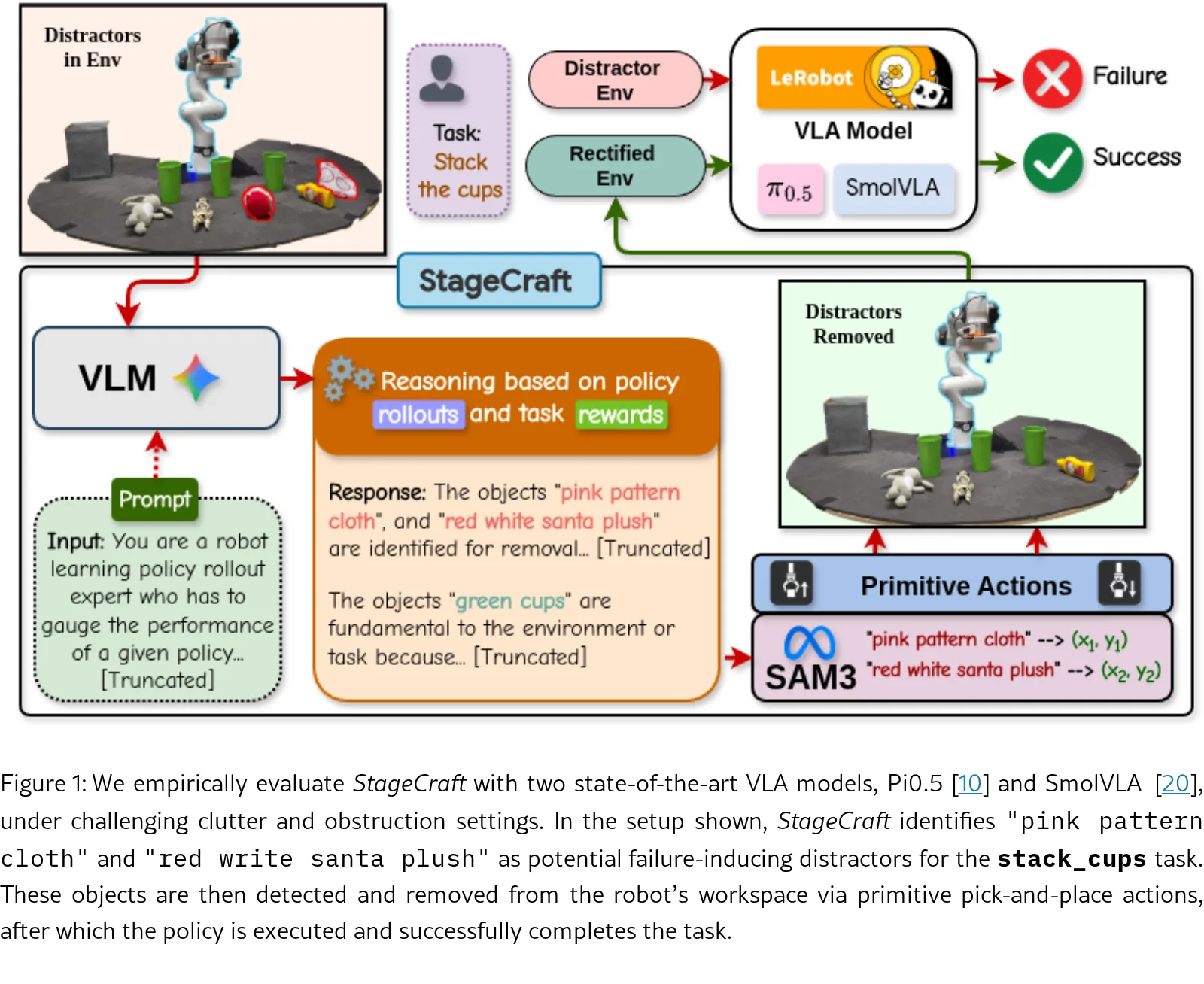
- 提出 StageCraft 方法——基于策略历史执行记录进行初始环境状态推理,仅移除必要的干扰物对象,是一个可扩展的即插即用模块
- 在真实机器人(Franka FR3)上进行多任务评估,涵盖 stack_cups、setup_plate、block_in_bowl 三个任务域,证明了对先进 VLA 模型的性能提升效果
- RLBench 仿真实验验证了方法的自适应性:随基础策略强度调整干预程度,且随着上下文样本数量增加性能持续提升
- 验证了对象集创建与转换形式化的有效性,证明单纯依赖 VLM 开放式推理无法获得一致准确的结果
Card 04
方法描述
方法描述
- 问题形式化:将初始状态分解为任务相关对象(X_rev)和干扰物对象(X_dist),目标是从 X_dist 中识别需要操纵的子集
- 对象集创建:收集不同干扰物配置下的策略执行回滚,计算每个配置的经验成功率
- 对象集转换:筛选出成功率最高的对象集子集,根据新场景选择最大子集确定需要移除的对象
- VLM 推理:利用 VLM 的上下文学习能力,按照指定策略识别对象并推断最小操作步骤
- 环境修改:使用 SAM3 模型检测对象边界框,通过逆 kinematics 规划的原始动作(如抓取-放置)移除干扰物
Card 05
数据集与资源
数据集与资源
- 机器人平台:Franka FR3 机械臂
- 真实任务:stack_cups、setup_plate、block_in_bowl 三个领域
- VLA 模型:SmolVLA、Pi0.5(基于 LeRobot 预训练权重微调)
- VLM 模型:gemini-3.1-pro(主实验)、gemini-2.5-pro、gpt-5.2-pro(消融实验)
- 干扰物数量:8 个干扰物对象
- 训练数据:每个任务 60 条演示轨迹
- 仿真环境:RLBench 中的 pick the red cup 任务
Card 06
评估与结果
评估与结果
- 真实机器人实验:在 Distractor 设置下,StageCraft 使成功率提升绝对值 40%,接近 Base 设置的基线水平
- 仿真实验结果:
- π_strong(强策略):干预 1.14 步,性能从 85% 提升至 98%(+13%)
- π_weak(弱策略):干预 3.09 步,性能从 0% 提升至 66%(+66%)
- 上下文样本影响:20 个样本时成功率为 54%,1 个样本时为 49%,验证更多样本可提升性能估计
- Prompt following 准确率:gemini-3.1-pro 达到 95%
- 消融研究:无对象集策略的 baseline 移除了更多对象(包括任务关键物体),且一致性较差(变异系数 57.8% vs 13.62%)