一眼看懂
封面预览
论文旨在解决 视觉-语言-动作(VLA) 模型在真实世界中通过强化学习进行微调时,面临的交互成本高、安全风险大的问题。
- 论文旨在解决 视觉-语言-动作(VLA) 模型在真实世界中通过强化学习进行微调时,面临的交互成本高、安全风险大的问题。
- 提出在交互式世界模型中训练 VLA 模型以规避上述问题,但该方法面临像素级世界建模、多视图一致性、以及稀疏奖励下误差累积等核心挑战。
- 论文的目标是提出一个实用的、基于世界模型的强化学习框架,以解决这些挑战,提升策略性能与样本效率。
Card 01
研究单位
研究单位
- 作者所属机构未在原文中明确列出,根据文中的实验硬件平台(如 Galaxy-R1 和 Arx-X5 机器人系统)推断,研究来自具备机器人实验平台的研究机构。
Card 02
论文概述
论文概述
- 论文旨在解决 视觉-语言-动作(VLA) 模型在真实世界中通过强化学习进行微调时,面临的交互成本高、安全风险大的问题。
- 提出在交互式世界模型中训练 VLA 模型以规避上述问题,但该方法面临像素级世界建模、多视图一致性、以及稀疏奖励下误差累积等核心挑战。
- 论文的目标是提出一个实用的、基于世界模型的强化学习框架,以解决这些挑战,提升策略性能与样本效率。
Card 03
核心贡献
核心贡献
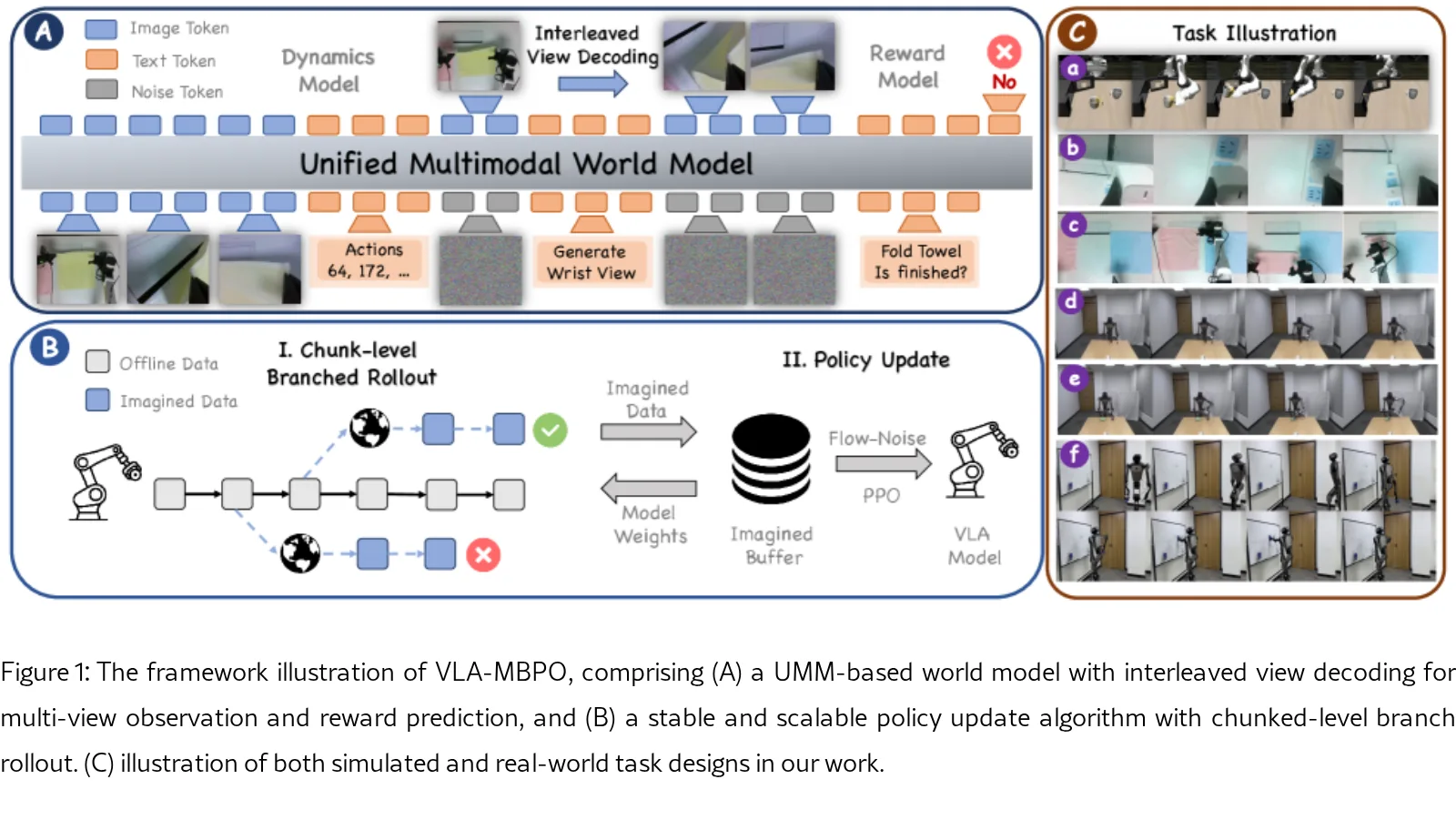
- 提出了 VLA-MBPO 框架,这是一个面向 VLA 模型的实用世界模型强化学习方法。
- 创新性地将 统一多模态模型 适配为世界模型骨干,实现了数据高效的视觉动态与奖励联合预测。
- 提出了 交叉视图解码 机制,以强制生成多视图预测的一致性。
- 引入了 块级分支展开 策略,有效缓解了在稀疏奖励场景下世界模型误差累积的问题。
- 提供了关于减小价值差距的理论分析,并在仿真和真实世界任务中验证了框架的有效性。
Card 04
方法描述
方法描述
- 世界模型基于预训练的 统一多模态模型(UMM),具体使用了 Bagel 模型。该方法将连续动作离散化为词元序列,使 UMM 能够直接处理动作输入并联合预测未来观测与奖励。
- 通过 交叉视图解码 策略实现多视图一致性。该方法按顺序生成头部视角观测,然后以已生成的头部视角为条件生成手腕视角,从而显式约束跨视图的一致性。
- 采用 块级分支展开 进行策略优化。该方法不从初始状态进行长时序展开,而是从离线数据集中的任意观测开始,进行短时序的分支展开。结合块级动作预测,显著缩短了有效展开长度,减少了误差累积。
- 策略优化基于 PPO 框架,并采用 Flow-Noise 变体来优化基于流匹配的策略,同时为 VLA 模型附加一个 MLP 价值头。
Card 05
数据集与资源
数据集与资源
- 仿真任务:使用 LIBERO 机器人操作基准,包含 Spatial、Object、Goal、Long 四个任务套件。每个任务使用 50 条轨迹进行训练。
- 真实世界任务:在 Arx-X5 双臂机器人和 Galaxy-R1 全身机器人上设计了五个任务(如插线缆、叠毛巾、拿杯子等),每个任务通过遥操作收集约 50-100 条轨迹用于监督微调。
- 模型规模:世界模型基于统一多模态模型 Bagel;VLA 策略模型使用 π₀.₅ 并进行微调。
- 训练资源:训练使用了 A100 GPU,具体计算资源细节见附录 F。
Card 06
评估与结果
评估与结果
- 评估环境:仿真环境为 LIBERO 基准;真实世界环境为上述两个机器人平台。
- 主要评估指标:任务成功率。
- 关键实验结果:
- 在 LIBERO 基准上,VLA-MBPO 在所有四个套件上均取得最佳平均成功率,相比初始 SFT 策略平均提升 +9.1%,尤其在长时序任务上提升显著(+12.2%)。
- 在真实世界任务中,VLA-MBPO 在两种机器人平台的所有五个任务上均表现出一致的性能提升,验证了其鲁棒性和泛化能力。
- 消融研究证实了 交叉视图解码 和 块级分支展开 各自的重要性,并验证了方法对关键超参数(如展开长度、样本量)的稳健性。
- 理论分析表明,VLA-MBPO 通过块级展开显著降低了策略与模型误差导致的价值差距。