一眼看懂
封面预览
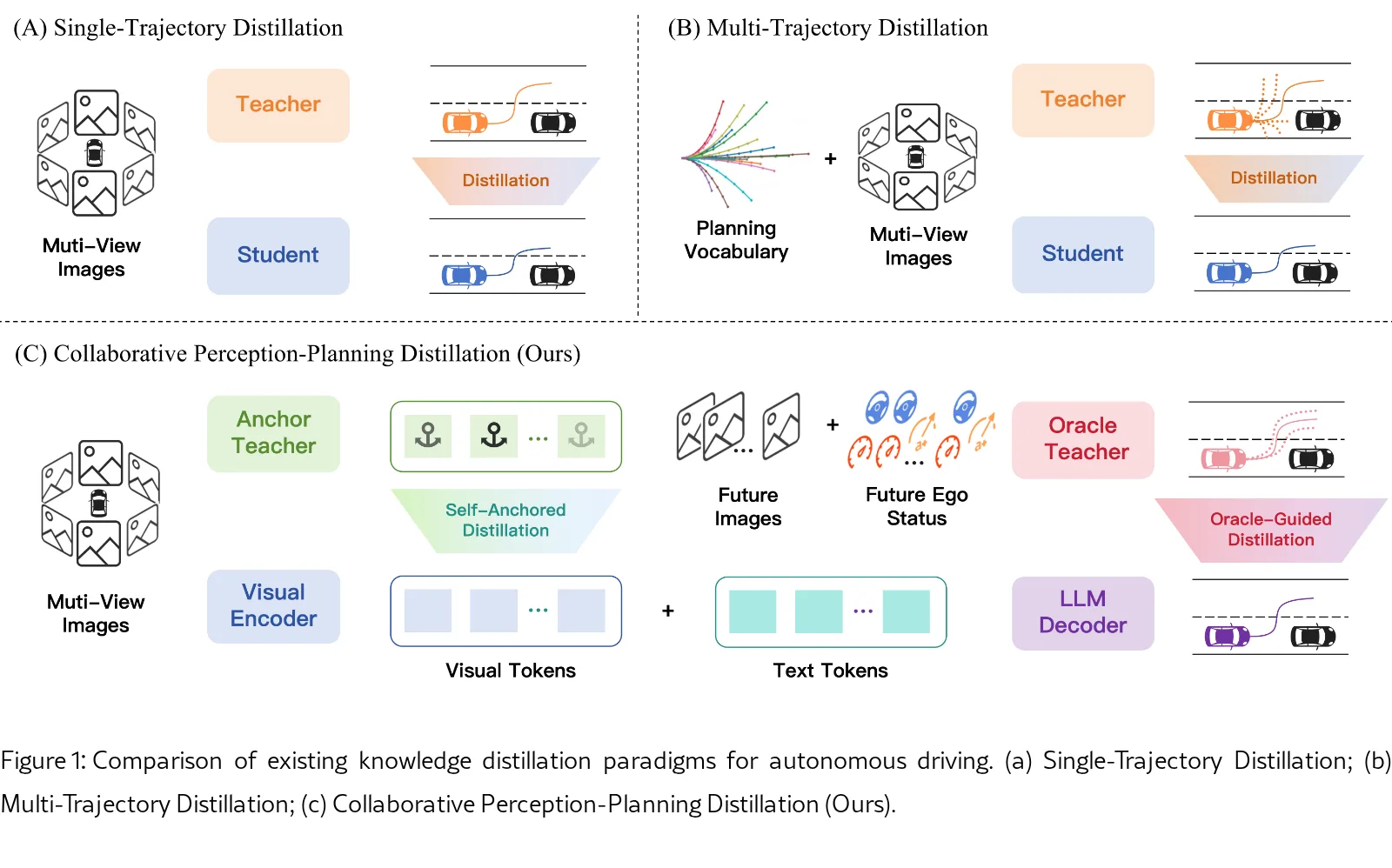
论文提出了 EvoDriveVLA,一个用于自动驾驶的协同感知-规划蒸馏框架。
- 论文提出了 EvoDriveVLA,一个用于自动驾驶的协同感知-规划蒸馏框架。
- 旨在解决视觉-语言-动作(VLA)模型在解冻视觉编码器后感知能力退化,以及长期规划中轨迹不稳定的问题。
- 通过结合自锚定视觉约束和先知引导的轨迹优化,协同增强模型的视觉表征和轨迹预测能力。
Card 01
研究单位
研究单位
- Jiajun Cao, Xiaoan Zhang, Xiaobao Wei, Liyuqiu Huang, Wang Zijian, Hanzhen Zhang, Zhengyu Jia, Wei Mao, Hao Wang, Xianming Liu, Shuchang Zhou, Yang Wang, Shanghang Zhang
- (注:原文 HTML 片段未明确列出具体所属机构名称,仅列出作者姓名)
Card 02
论文概述
论文概述
- 论文提出了 EvoDriveVLA,一个用于自动驾驶的协同感知-规划蒸馏框架。
- 旨在解决视觉-语言-动作(VLA)模型在解冻视觉编码器后感知能力退化,以及长期规划中轨迹不稳定的问题。
- 通过结合自锚定视觉约束和先知引导的轨迹优化,协同增强模型的视觉表征和轨迹预测能力。
Card 03
核心贡献
核心贡献
- 提出了 EvoDriveVLA 框架,这是一种新颖的协同感知-规划蒸馏方法。
- 设计了 自锚定视觉蒸馏,利用自锚定教师和轨迹引导的关键区域感知来保持视觉编码器的表征能力。
- 提出了 先知引导的轨迹蒸馏,利用包含未来信息的先知教师生成高质量轨迹候选。
- 引入了 从粗到细的轨迹细化 策略和 MC-Dropout 采样机制,以提升轨迹的准确性和多样性。
- 在开环和闭环评估中均取得了领先性能,特别是在 nuScenes 和 NAVSIM 基准上表现优异。
Card 04
方法描述
方法描述
- 自锚定视觉蒸馏:复制学生模型的视觉编码器作为固定的“自锚定教师”,利用其视觉特征作为约束;设计了 AnchorFormer 模块,根据轨迹引导计算 Token 级别的锚定权重,对关键区域施加更强的约束。
- 先知引导的轨迹蒸馏:构建“未来感知先知教师”,利用未来时刻的图像和自车状态等特权信息进行轨迹预测。
- 采用 从粗到细 的迭代方式,将粗轨迹作为输入生成更精细的轨迹。
- 使用 MC-Dropout 对隐藏状态进行采样以生成多样化的轨迹候选,通过计算与真值的交叉熵损失选择最优轨迹作为软目标指导学生模型。
Card 05
数据集与资源
数据集与资源
- nuScenes 数据集:用于开环轨迹规划评估。
- NAVSIM 基准:用于闭环驾驶性能评估。
- 超参数设置:Dropout 概率 $p=0.1$,采样数 $N=10$,视觉蒸馏温度 $\tau_v=2.0$,轨迹蒸馏温度 $\tau_t=5$。
- 开源代码地址:https://github.com/hey-cjj/EvoDriveVLA
Card 06
评估与结果
评估与结果
- 开环评估:在 nuScenes 数据集上,平均 L2 误差为 0.26m,平均碰撞率为 0.06%,优于 DiMA 和 DistillDrive 等现有蒸馏方法。
- 闭环评估:在 NAVSIM 测试集上,PDMS 得分达到 85.3,显著优于 UniAD (83.4) 和其他基于 VLA 的基线模型(如 QwenVL2.5-8B)。
- 实验结果表明该方法在提升规划精度的同时,有效降低了碰撞风险并提高了驾驶舒适度。