一眼看懂
封面预览
提出 MVLAD-AD 框架,解决端到端自动驾驶中推理延迟、动作精度和可解释性三大挑战
- 提出 MVLAD-AD 框架,解决端到端自动驾驶中推理延迟、动作精度和可解释性三大挑战
- 针对现有自回归模型逐token生成速度慢、扩散模型使用冗余语言token导致表示效率低的问题
- 目标:在保持语义可解释性的同时实现高效、低延迟的规划推理
Card 01
研究单位
研究单位
- Purdue University (普渡大学)
- 物理人工智能研究所 (IPAI)
- 工程学院
- 计算机科学系
Card 02
论文概述
论文概述
- 提出 MVLAD-AD 框架,解决端到端自动驾驶中推理延迟、动作精度和可解释性三大挑战
- 针对现有自回归模型逐token生成速度慢、扩散模型使用冗余语言token导致表示效率低的问题
- 目标:在保持语义可解释性的同时实现高效、低延迟的规划推理
Card 03
核心贡献
核心贡献
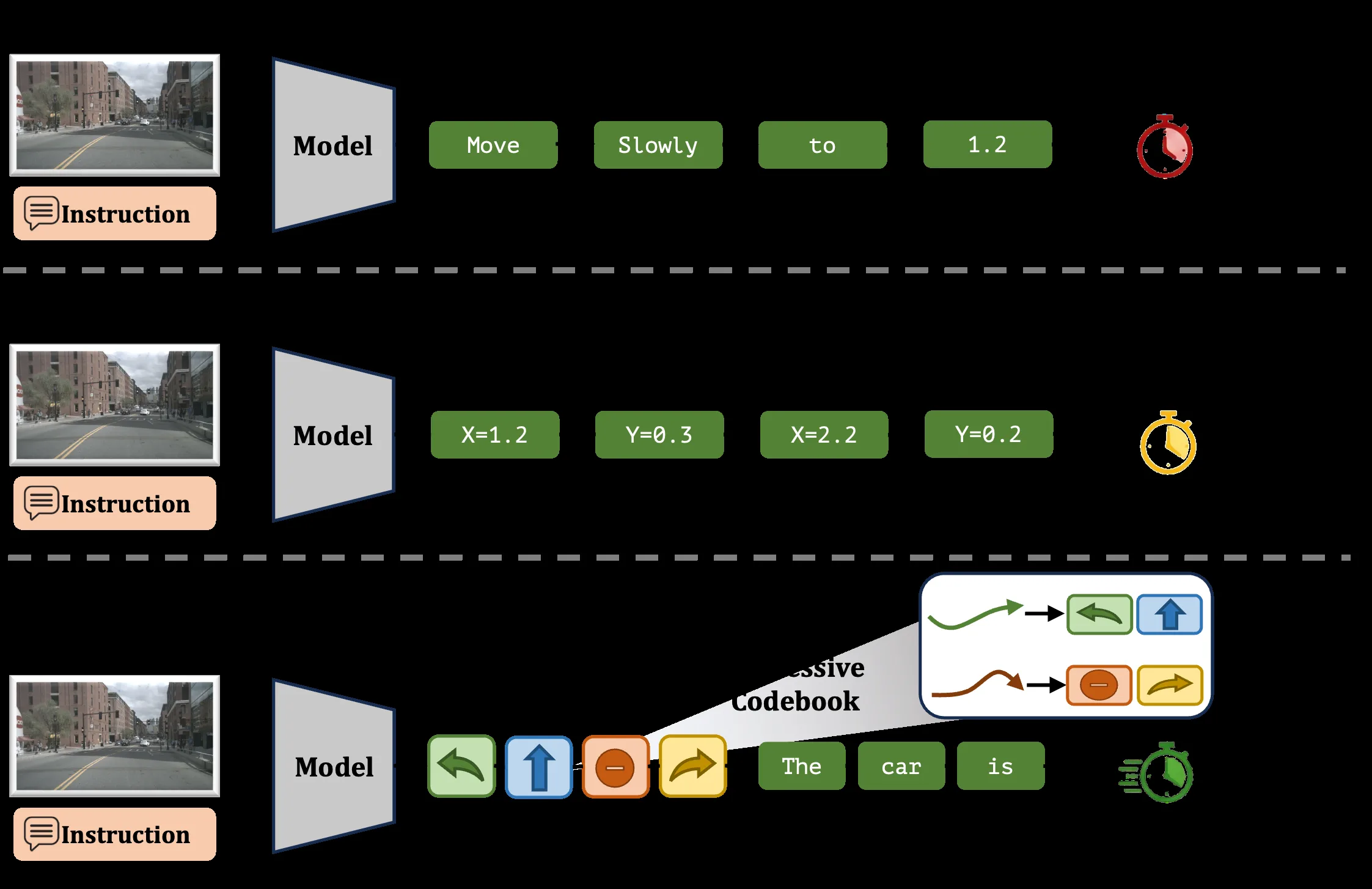
- 提出首个端到端掩码VLA扩散框架 MVLAD-AD,同时实现高效规划和语义推理
- 离散动作标记化:将连续轨迹映射到 N=256 个紧凑的动作token,构建kinematically feasible的codebook
- 几何感知嵌入学习:通过软分配、重建损失、几何一致性损失和对比聚类损失确保嵌入空间近似物理几何度量
- 动作优先解码策略:在推理时优先解码轨迹token,显著降低规划延迟
- 在 nuScenes 上实现最优规划精度(平均 L2 误差 1.28m),推理速度比 ViLaD 快 1.6 倍
Card 04
方法描述
方法描述
- 离散动作标记化:使用K-Means从真实驾驶数据中聚类出 N=256 个代表性路点,构建紧凑codebook
- 几何感知嵌入学习:通过温度缩放的软分配机制,结合几何一致性损失和对比聚类损失学习嵌入空间
- 统一掩码VLA扩散:将视觉、指令、动作和推理token统一为单一序列进行掩码生成建模
- 两阶段训练:第一阶段动作中心预热(仅训练动作token),第二阶段联合VLA微调(动作+推理)
- 动作优先解码:在每步扩散迭代中仅从动作token位置选择高置信度token先解码
Card 05
数据集与资源
数据集与资源
- 数据集:nuScenes(规划)、Nu-X(驾驶解释)、nuScenes-QA(视觉问答)
- 模型基座:LLaDA 预训练权重,采用 LoRA 微调(rank=256)
- 训练资源:4块 NVIDIA H100 GPU,bfloat16 精度,batch size 32,每阶段8个epoch,总计约9小时
- 评估环境:单块 NVIDIA A100 GPU
Card 06
评估与结果
评估与结果
- 规划性能:nuScenes 平均 L2 误差 1.28m(1s: 0.70m, 2s: 1.31m, 3s: 2.34m),失败率 0.00%
- 推理效率:1.72s,比 ViLaD 快 1.6×,比 LLaVA-1.6 快 1.84×
- 推理能力:Nu-X 上 BLEU-4: 13.0, METEOR: 36.8, ROUGE-L: 37.3;nuScenes-QA 准确率 55.7%
- 消融实验:N=256 为最优codebook大小;几何感知嵌入使 L2 误差从 2.39m 降至 1.28m;路点表示优于位移表示