一眼看懂
封面预览
提出了 FUTURE-VLA,一个将长视野控制和未来预测统一为序列生成任务的架构。
- 提出了 FUTURE-VLA,一个将长视野控制和未来预测统一为序列生成任务的架构。
- 旨在解决现有机器人策略中处理长视野历史时的高延迟、预测与决策模块化分离导致的“感知近视”与计算开销过大问题。
- 实现了在扩展16倍时空窗口的同时,保持与单帧基线相同的推理延迟。
Card 01
研究单位
研究单位
- 作者所属机构未在提供的HTML原文中明确标注。
Card 02
论文概述
论文概述
- 提出了 FUTURE-VLA,一个将长视野控制和未来预测统一为序列生成任务的架构。
- 旨在解决现有机器人策略中处理长视野历史时的高延迟、预测与决策模块化分离导致的“感知近视”与计算开销过大问题。
- 实现了在扩展16倍时空窗口的同时,保持与单帧基线相同的推理延迟。
Card 03
核心贡献
核心贡献
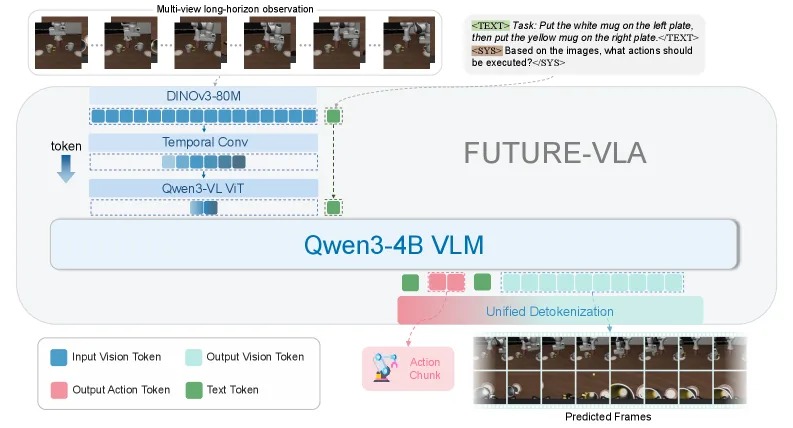
- 提出约束预算的时空压缩范式,在固定Token预算内最大化信息密度,实现高效的长视野感知。
- 提出 FUTURE-VLA 统一框架,通过潜在空间自回归在单次前向传播中同步生成动作块与未来视觉预测。
- 开发预测引导的“人在环”(HIL)机制,利用实时未来预览实现动态执行门控,增强机器人部署的安全性。
Card 04
方法描述
方法描述
- 采用“双边效率”策略:输入端使用 时间自适应级联压缩 平衡长时记忆与短时精度;输出端在紧凑潜在空间进行自回归预测。
- 视觉编码采用冻结的 DINOv3 编码器以保留空间细节,并通过分层压缩策略处理长视野输入。
- 使用 FAST框架 进行频谱动作标记化,并采用 紧凑1D视觉标记化(每帧32个Token)实现高效未来预测。
- 在推理阶段,模型同步生成动作块与未来视觉轨迹,支持动态门控与重采样恢复策略。
Card 05
数据集与资源
数据集与资源
- 使用 LIBERO 基准、RoboTwin2.0 套件和真实世界 Piper 双臂平台进行评估。
- 模型基于 Qwen3-VL 构建,视觉编码器基于 DINOv3-ViT-Base。
- 训练使用NVIDIA RTX 4090 GPU。
Card 06
评估与结果
评估与结果
- 在 LIBERO 基准上达到 99.2% 的成功率(使用HIL),创下新SOTA。
- 在 RoboTwin 套件上达到 75.4% 的平均成功率,显著优于现有基线。
- 在真实世界 Piper 平台上达到 78.0% 的平均成功率,验证了实际部署能力。
- 消融实验验证了时空压缩策略的有效性,能在使用75%更少Token的情况下达到与密集基线相当的性能。