一眼看懂
封面预览
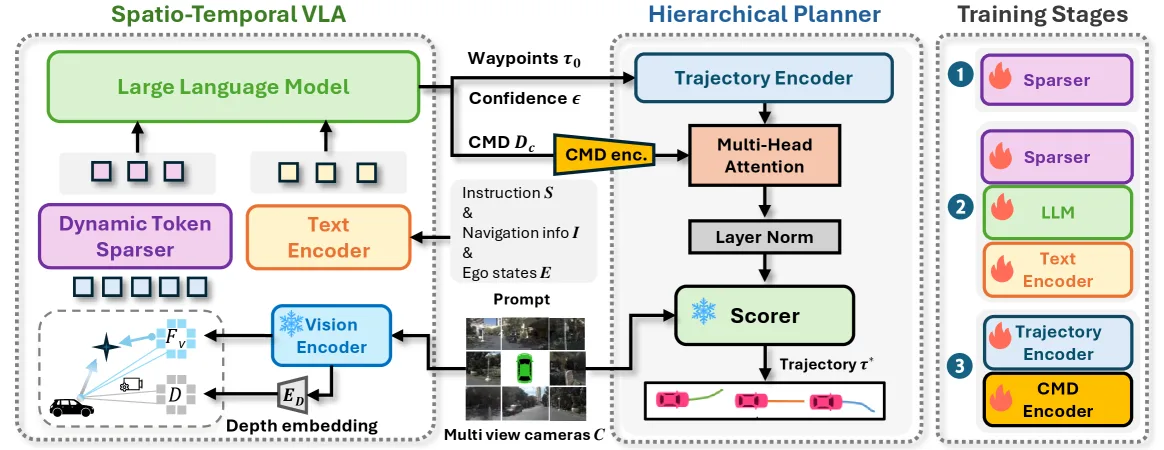
论文提出了 HiST-VLA,一种用于端到端自动驾驶的层次化时空视觉-语言-动作模型。
- 论文提出了 HiST-VLA,一种用于端到端自动驾驶的层次化时空视觉-语言-动作模型。
- 旨在解决现有 VLA 模型在精确数值推理、3D 空间感知能力弱以及对上下文高度敏感等方面的局限性。
- 通过集成几何感知、细粒度驾驶命令和历史状态提示,生成安全可靠的轨迹。
Card 01
研究单位
研究单位
- Bosch Corporate Research, Bosch (China) Investment Ltd.
- School of Communication and Information Engineering, Shanghai University
Card 02
论文概述
论文概述
- 论文提出了 HiST-VLA,一种用于端到端自动驾驶的层次化时空视觉-语言-动作模型。
- 旨在解决现有 VLA 模型在精确数值推理、3D 空间感知能力弱以及对上下文高度敏感等方面的局限性。
- 通过集成几何感知、细粒度驾驶命令和历史状态提示,生成安全可靠的轨迹。
Card 03
核心贡献
核心贡献
- 提出了 HiST-VLA 架构,集成了空间定位和时间一致性,通过多阶段轨迹细化提升驾驶舒适性和安全性。
- 设计了带有动态 Token 稀疏化机制的高效时空表征方法,利用自相似性引导的 Token 融合有效减少冗余。
- 提出了语义对齐的层次化规划器,通过置信度感知正则化和多标准评分,将粗略轨迹细化为精细运动。
Card 04
方法描述
方法描述
- 视觉编码采用 ViT-L/14 提取特征,结合单目深度估计实现 3D 空间感知视觉编码。
- 引入 Dynamic Token Sparser 模块,基于自注意力分数进行自适应 Token 稀疏化,合并冗余 Token 以提高计算效率。
- 通过时间状态建模,将历史导航信息和自车状态作为提示输入,增强时序连贯性。
- 利用 Chain-of-Thought (CoT) 推理生成细粒度元动作命令和带有置信度分数的粗略轨迹。
- 采用基于 Transformer 的层次化规划器,利用 VAE 和评分模块对粗略轨迹进行细化和优化。
Card 05
数据集与资源
数据集与资源
- 使用 NAVSIM v2 数据集进行训练和评估(包含 Navtest 和 Navhard 基准)。
- 基础模型为 LLaVA-v1.5-7B,包含 70 亿参数,视觉编码器为 ViT-L/14。
- 训练过程包含三个阶段:预训练稀疏模块、联合优化 VLA 模块、训练层次化规划器。
Card 06
评估与结果
评估与结果
- 在 NAVSIM v2 基准上进行评估,使用 EPDMS 作为主要评估指标。
- 在 Navtest 基准上取得了 88.6 的 EPDMS 分数,达到了最先进水平。
- 在伪闭环 Navhard 基准上取得了 50.9 的 EPDMS 分数,展示了在复杂场景下的鲁棒性。