返回列表
VLA / Vision-Language-Action 每日论文卡
待生成
论文详情
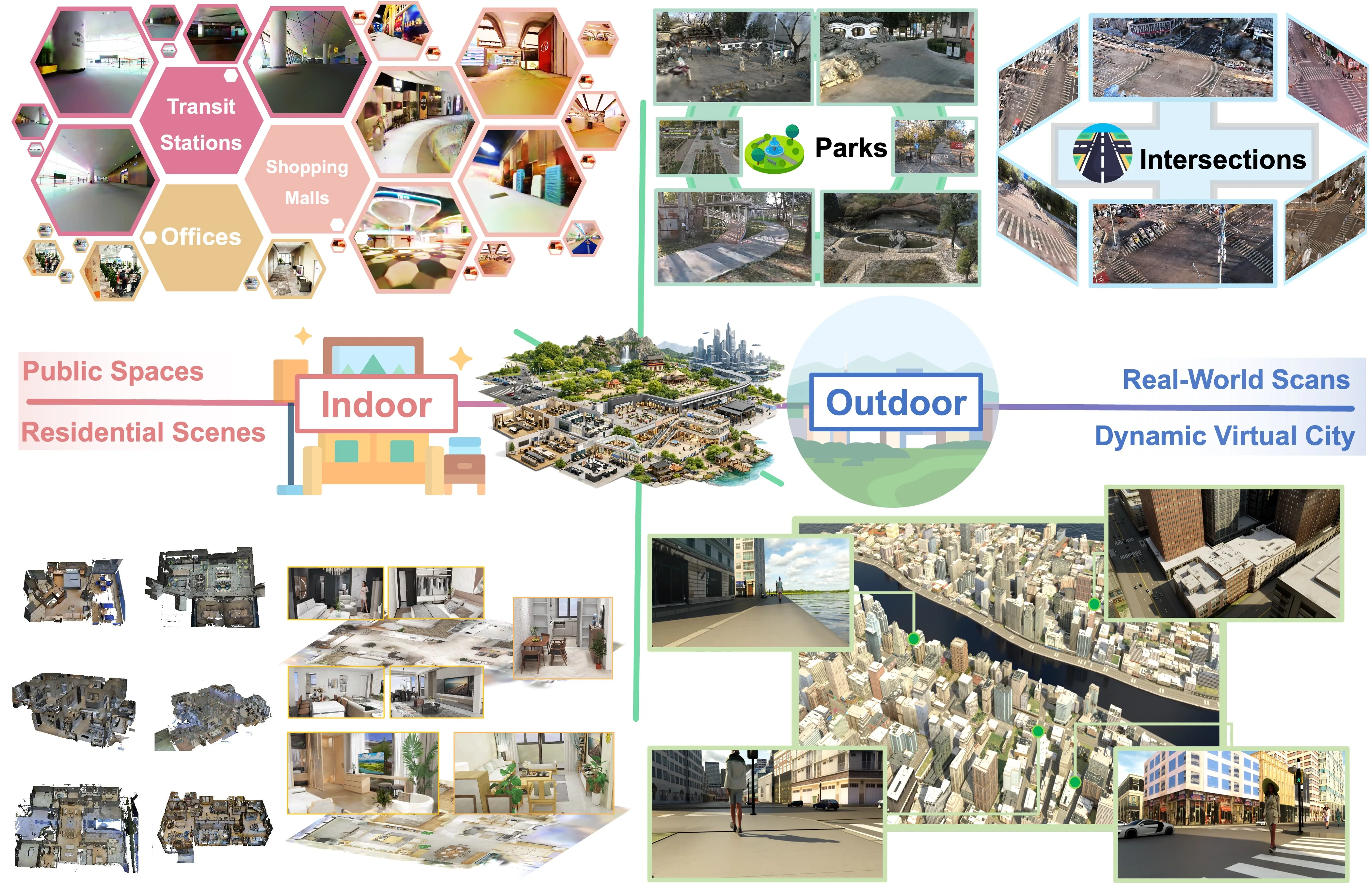
ABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
2026-02-12 ·
原文
·
翻译
·
2602.11598
待生成
1 分钟读完
1 张阅读卡
一眼看懂
封面预览
待生成
待生成
Card 01
论文概述
论文概述
待生成
← 上一篇
When would Vision-Proprioception Policies Fail in Robotic Manipulation?
下一篇 →
HiST-VLA: A Hierarchical Spatio-Temporal Vision-Language-Action Model for End-to-End Autonomous Driving