一眼看懂
封面预览
提出 NavDreamer 框架,利用生成视频模型作为语言指令与导航轨迹之间的通用接口,实现零样本3D导航。
- 提出 NavDreamer 框架,利用生成视频模型作为语言指令与导航轨迹之间的通用接口,实现零样本3D导航。
- 核心假设是视频模型编码时空信息与物理动态的能力,结合互联网规模的数据,能实现强大的导航零样本泛化。
- 旨在解决现有视觉-语言-动作模型面临的数据稀缺、采集成本高以及静态表示无法捕捉时间动态与物理定律的局限性。
Card 01
研究单位
研究单位
- 浙江大学
- Differential Robotics
- 北京航空航天大学
Card 02
论文概述
论文概述
- 提出 NavDreamer 框架,利用生成视频模型作为语言指令与导航轨迹之间的通用接口,实现零样本3D导航。
- 核心假设是视频模型编码时空信息与物理动态的能力,结合互联网规模的数据,能实现强大的导航零样本泛化。
- 旨在解决现有视觉-语言-动作模型面临的数据稀缺、采集成本高以及静态表示无法捕捉时间动态与物理定律的局限性。
Card 03
核心贡献
核心贡献
- 提出了结合生成视频模型与逆动力学模型的零样本3D导航器,用于解决高级指令任务。
- 设计了一个涵盖五个关键维度(物体导航、精确导航、空间定位、语言控制、场景推理)的综合3D导航基准,用于系统评估视频模型。
- 通过广泛的消融研究,深入探索了不同设计选择对视频模型在3D导航中性能的影响。
Card 04
方法描述
方法描述
- 采用生成视频模型根据输入图像和语言指令合成预测性导航序列。
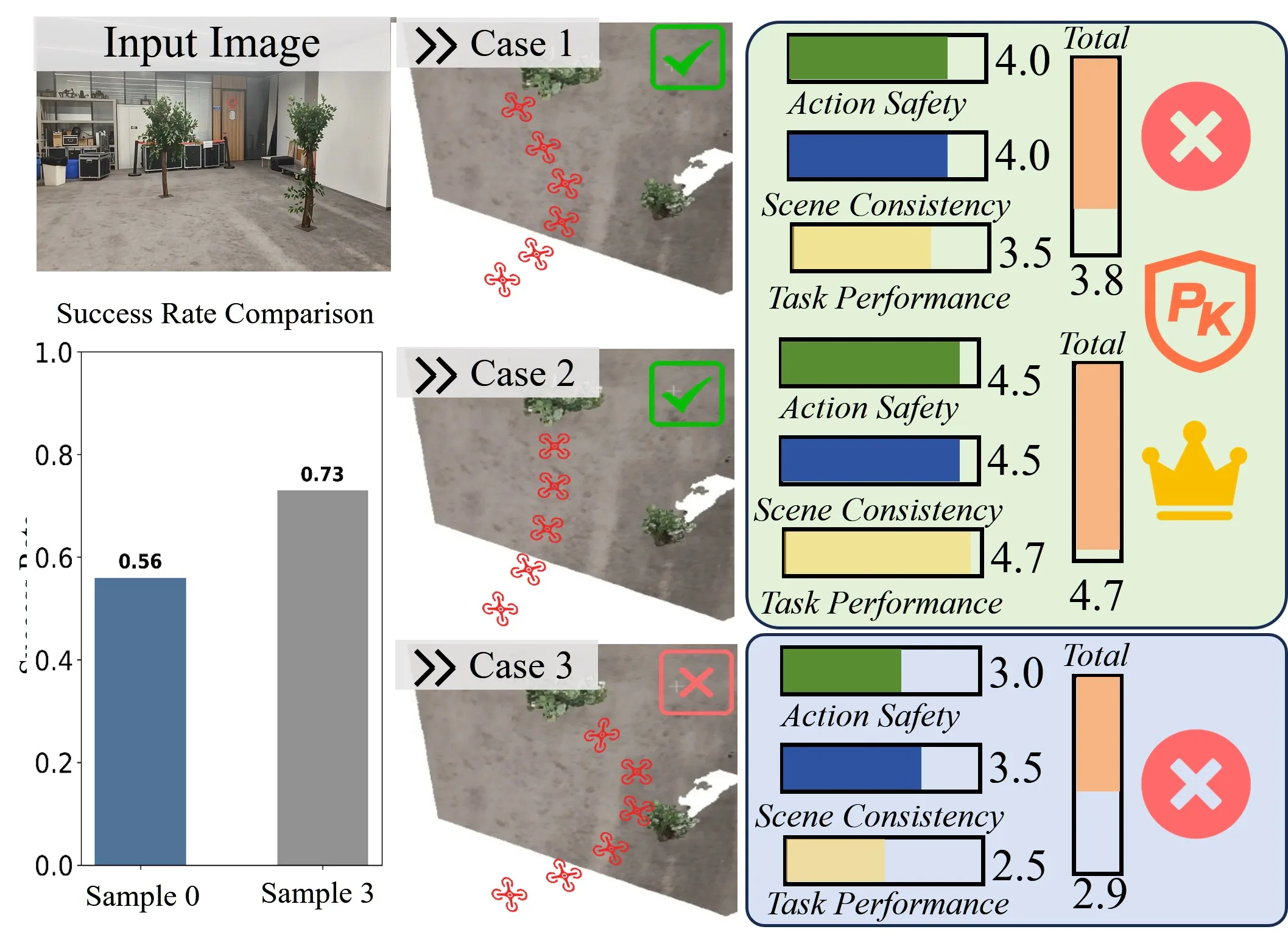
- 引入基于采样的优化方法,利用 Qwen3-VL 对生成的多条视频候选进行评分(依据动作安全性、场景一致性、任务表现)并选择最优轨迹。
- 使用逆动力学模型 π³ 从选定的视频序列中解码出可执行的航点,并结合 MoGe-2 的度量深度先验来校正绝对尺度歧义。
- 使用 Ego-Planner 作为底层规划模块,在实时避障的同时执行校正后的航点轨迹。
Card 05
数据集与资源
数据集与资源
- 提出了一个涵盖五个导航任务类别(物体导航、精确导航、空间定位、语言控制、场景推理)的综合基准。
- 在实验中评估了多种开源和闭源生成视频模型,包括 Wan 2.2、HunyuanVideo 1.5、Cosmos 2.5、LVP 和 Wan 2.6。
- 在真实世界部署中,使用了配备 Intel RealSense 相机和激光雷达的无人机平台,并利用 Fast-LIVO2 进行位姿估计。
Card 06
评估与结果
评估与结果
- 在自建的3D导航基准上,从视觉一致性、动态可行性和任务完成度三个维度对视频模型进行了评估。
- 实验表明,闭源模型 Wan 2.6 在几乎所有指标上取得了最佳的整体性能,特别是在任务完成率上平均达到 0.84。
- 系统在从室内到室外的多种未见过场景中展示了强大的零样本泛化能力,成功将视觉想象转化为物理行动。
- 消融研究证实,所提出的度量尺度校正方法能将相对尺度误差降至 10% 左右,而增加采样预算能显著提高任务成功率。