一眼看懂
封面预览
研究目标: 解决视觉语言动作(VLA)模型中本体感知(proprioception)仅作为后期 conditioning 信号的问题,使机器人…
- 研究目标: 解决视觉语言动作(VLA)模型中本体感知(proprioception)仅作为后期 conditioning 信号的问题,使机器人…
- 核心方法: 提出 ThinkProprio,将本体感知转换为 VLM 嵌入空间中的文本 token,与任务指令在输入端融合,实现早期融合,让具…
- 关键成果: 在 CALVIN 和 LIBERO 基准上匹配或超越最强基线,同时将端到端推理延迟降低超过 58%
Card 01
研究单位
研究单位
- 论文作者: Fangyuan Wang, Peng Zhou, Jiaming Qi, Shipeng Lyu, David Navarro-Alarcon, Guodong Guo
- 机构: 根据论文页眉信息,arXiv ID 为 2602.06575,具体机构信息在原文 HTML 中未完整显示
Card 02
论文概述
论文概述
- 研究目标: 解决视觉语言动作(VLA)模型中本体感知(proprioception)仅作为后期 conditioning 信号的问题,使机器人状态能够塑造指令理解并影响整个策略中的视觉 token 注意力
- 核心方法: 提出 ThinkProprio,将本体感知转换为 VLM 嵌入空间中的文本 token,与任务指令在输入端融合,实现早期融合,让具身状态参与后续的视觉推理和 token 选择
- 关键成果: 在 CALVIN 和 LIBERO 基准上匹配或超越最强基线,同时将端到端推理延迟降低超过 58%
Card 03
核心贡献
核心贡献
- 贡献点 1: 提出将本体感知离散化为文本 token 并置入 VLM 嵌入空间的编码方法,利用预训练 token 嵌入表
- 贡献点 2: 提出物理接地 token 选择(Physically Grounded Token Selection),使用指令和本体感知联合指导视觉 token 保留
- 贡献点 3: 发现保留约 15% 的视觉 token 即可匹配使用完整 token 集的性能
- 贡献点 4: 在 CALVIN ABC→D 上将平均完成链长从 4.44 提升到 4.55,在 LH-5 达到 82.1% 成功率
- 贡献点 5: 显著降低推理延迟(从 52ms 降至 22ms)和计算成本
Card 04
方法描述
方法描述
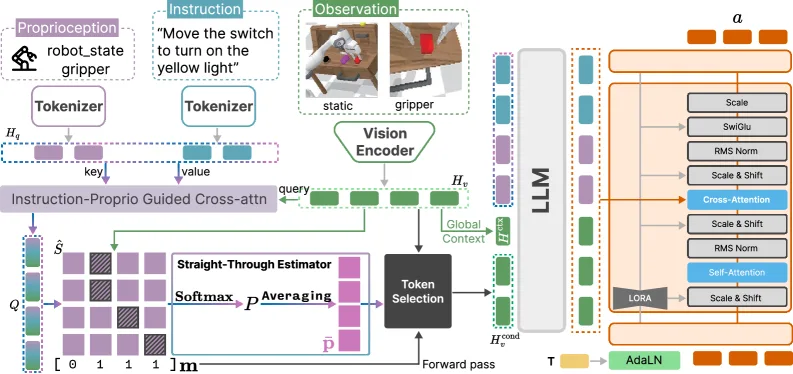
- 本体感知编码: 对连续状态值进行均匀分箱(256 个 bins),映射到 VLM 词汇表的最后 B 个 token ID,从 token 嵌入表中获取嵌入
- 物理接地 token 选择: 使用指令 token 和本体感知 token 作为引导,通过跨模态注意力生成查询,计算视觉 token 的相关性分数,采用基于 Gumbel 噪声的投票选择机制和直通估计器(STE)进行可微训练
- 全局上下文 token: 保留一个全局上下文 token 以保持粗粒度场景信息
- 动作生成: 使用 Flow Matching 训练动作头,通过交叉注意力 Conditioning 在 VLM 特征上,并使用全局 AdaLN 风格调制注入扩散时间信号
Card 05
数据集与资源
数据集与资源
- 数据集: CALVIN(ABC→D 分割)、LIBERO( Spatial/Object/Goal/Long 四个套件)
- 模型规模: 基于 Florence-2-Large 作为 VLM 主干,动作头为 DiT(hidden dimension 1024,18 层,16 头注意力)
- 训练资源: 50k 训练步,AdamW 优化器,学习率 2×10⁻⁵,权重衰减 0.05(transformer 部分),余弦学习率调度
- 推理配置: bfloat16,每时间步处理 2 个相机视图,diffusion 动作头采样 4 步
- GPU: RTX 4090
Card 06
评估与结果
评估与结果
- CALVIN ABC→D: ThinkProprio 达到 Avg. Len. 4.55(最优),LH-5 成功率 82.1%,比 FLOWER(4.44)提升 2.5%
- LIBERO: 平均成功率 97.3%(仅次于 LightVLA 的 97.4%),LIBERO-Long 达到 95.2%(最优)
- 推理效率: 平均保留 15/100(CALVIN)和 6/34(LIBERO)个视觉 token,延迟 22ms(CALVIN)/ 23.8ms(LIBERO),比 FLOWER 降低 58%
- VRAM: 1899 MB(CALVIN),比 OpenVLA(14574 MB)显著降低