一眼看懂
封面预览
论文旨在解决 视觉-语言-行动 (VLA) 模型 在强化学习训练中面临的效率瓶颈问题
- 论文旨在解决 视觉-语言-行动 (VLA) 模型 在强化学习训练中面临的效率瓶颈问题
- 现有框架(如RLinf)采用同步执行模式,导致环境交互、策略生成和模型更新阶段存在资源闲置和吞吐量限制
- 首次提出并实现了一个完全异步的策略训练管道 RL-VLA³,以提升训练吞吐量和资源利用率
Card 01
研究单位
研究单位
- 天津大学
- 北京大学
- 清华大学
- JDT AI Infra
- 斯winburne University of Technology
Card 02
论文概述
论文概述
- 论文旨在解决 视觉-语言-行动 (VLA) 模型 在强化学习训练中面临的效率瓶颈问题
- 现有框架(如RLinf)采用同步执行模式,导致环境交互、策略生成和模型更新阶段存在资源闲置和吞吐量限制
- 首次提出并实现了一个完全异步的策略训练管道 RL-VLA³,以提升训练吞吐量和资源利用率
Card 03
核心贡献
核心贡献
- 提出首个支持层次化异步执行的VLA强化学习训练框架,系统性缓解了同步训练中的资源闲置问题
- 通过流式生成与环境交互的解耦编排,实现了推理与仿真的高并发执行
- 在多个仿真任务和真实机器人部署中验证了框架的效率和泛化能力,为大规模具身智能研究提供了高效训练平台
Card 04
方法描述
方法描述
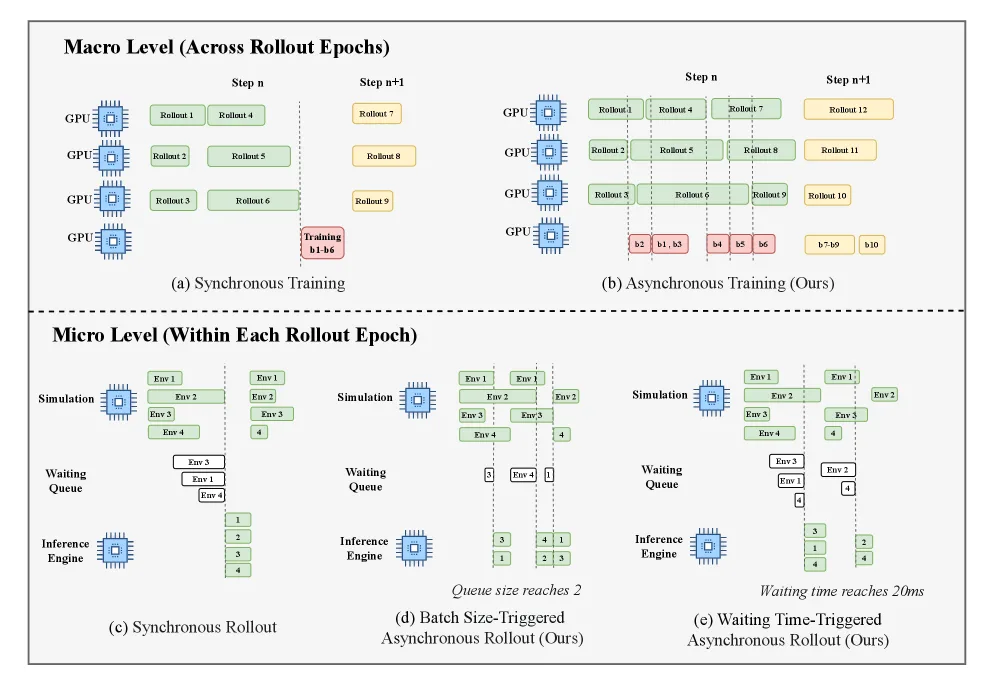
- 设计了三层异步执行架构:环境交互与轨迹收集异步化、策略生成流式执行、训练更新解耦调度
- 采用解耦式GPU分配策略,将 rollout workers 与 actor workers 部署在不同GPU上,通过高吞吐流水线通信
- 引入动态批调度器,利用最大推理批量和最大等待延迟作为约束,优化异步交互
- 实现流式生成机制,将全局训练批次划分为微批次,提前启动部分训练计算以掩盖数据准备时间
Card 05
数据集与资源
数据集与资源
- 使用 LIBERO 和 ManiSkill 机器人仿真环境作为基准测试
- 模型包括扩散模型 GR00T N1.5、π₀ 系列以及自回归模型 OpenVLA-OFT
- 实验在 8 到 256 GPU 的集群上进行,验证了方法的可扩展性
Card 06
评估与结果
评估与结果
- 在 LIBERO 基准上,吞吐量相比现有同步策略提升高达 59.25%
- 深度优化分离策略时,吞吐量提升可达 126.67%
- 消融实验验证了每个异步组件的有效性
- 扩展性验证表明,在大多数条件下该方法在多GPU规模下具有出色的扩展能力