一眼看懂
封面预览
针对 Vision-Language-Action (VLA) 模型在长序列上下文处理受限和推理效率低的问题,提出了 SD-VLA 框架。
- 针对 Vision-Language-Action (VLA) 模型在长序列上下文处理受限和推理效率低的问题,提出了 SD-VLA 框架。
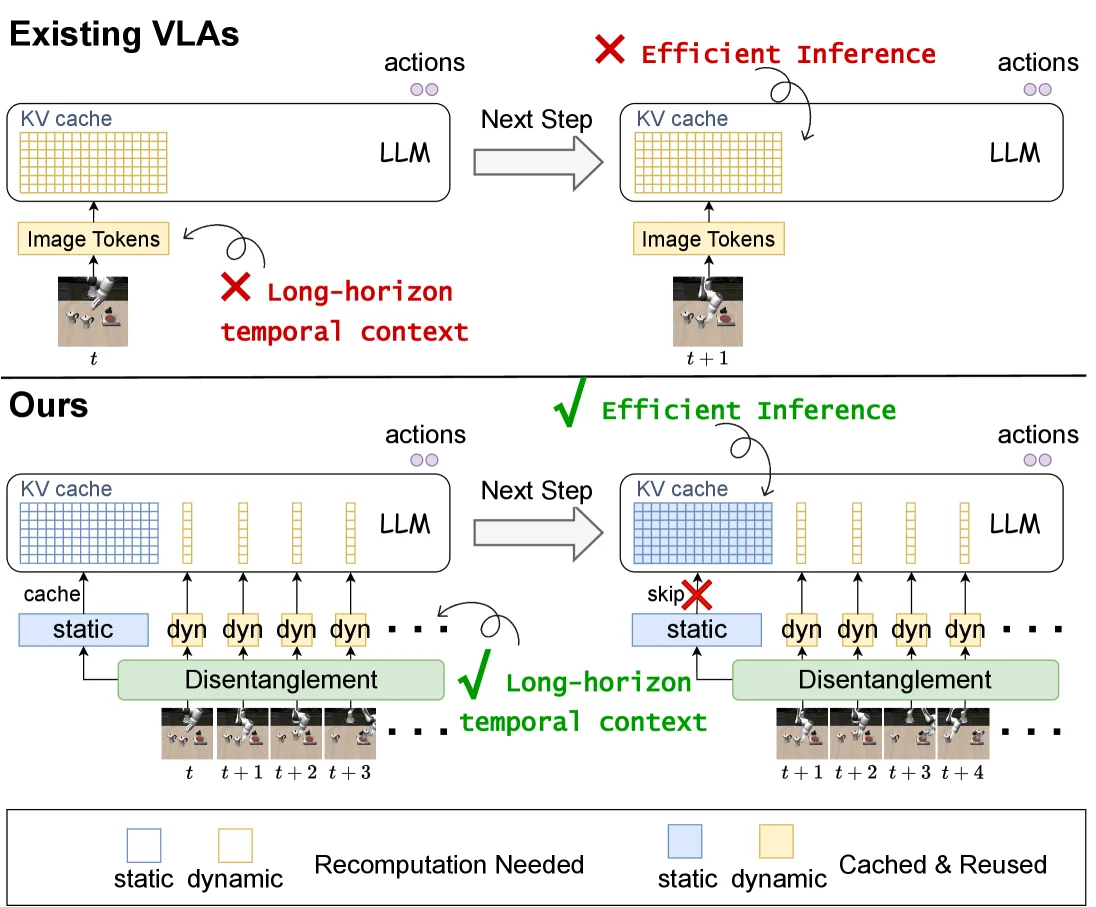
- 该框架基于视觉信息在时间步中大部分保持静态(如背景)的观察,将视觉输入解耦为静态和动态令牌。
- 通过仅保留一份静态令牌并复用其键值缓存,显著减少了上下文长度并提升了推理速度。
Card 01
研究单位
研究单位
- 论文作者为 Weikang Qiu、Tinglin Huang 和 Rex Ying(原文 HTML 中未明确列出具体所属机构名称)。
Card 02
论文概述
论文概述
- 针对 Vision-Language-Action (VLA) 模型在长序列上下文处理受限和推理效率低的问题,提出了 SD-VLA 框架。
- 该框架基于视觉信息在时间步中大部分保持静态(如背景)的观察,将视觉输入解耦为静态和动态令牌。
- 通过仅保留一份静态令牌并复用其键值缓存,显著减少了上下文长度并提升了推理速度。
Card 03
核心贡献
核心贡献
- 提出了 SD-VLA 框架,通过将图像令牌解耦为动态令牌和多级静态令牌,实现了长序列记忆整合和高效推理。
- 引入了一个可训练的 recache gate,自适应地决定何时刷新缓存或复用之前的缓存表示,在最小化延迟的同时优化性能。
- 发布了新基准 LIBERO-Memory,用于更有效地评估 VLA 模型对长序列时间依赖关系的建模能力。
Card 04
方法描述
方法描述
- 将视觉令牌显式解耦为 静态令牌(Static tokens)和 动态令牌(Dynamic tokens),并引入多级静态令牌以捕捉不同时间尺度的持久信息。
- 在处理多帧观测时,只保留一份静态令牌,并将动态令牌与语言指令拼接,从而在不扩展上下文窗口的情况下引入历史信息。
- 使用 Gumbel-softmax 技巧训练 recache gate,实现端到端的二元决策,判断是否需要重新计算静态令牌。
- 训练目标包含标准任务损失、用于静态令牌时序一致性的 InfoNCE 对比损失 以及用于门控机制的 正则化损失。
Card 05
数据集与资源
数据集与资源
- 训练数据集:Open X-Embodiment (OXE)(用于 SimplerEnv 实验)、LIBERO 数据集。
- 评估基准:新提出的 LIBERO-Memory、SimplerEnv、LIBERO。
- 基础模型:基于 CogAct(用于 SimplerEnv 和 LIBERO-Memory)和 OpenVLA-OFT(用于 LIBERO)进行微调和评估。
- 仿真环境:使用 Robosuite 生成 LIBERO-Memory 数据。
Card 06
评估与结果
评估与结果
- 在 LIBERO-Memory 基准上,模型成功率比基线绝对提升了 39.8%,证明了其在时间依赖建模上的优越性。
- 在 SimplerEnv 基准上,成功率提升了 3.9%,推理延迟降低,实现了 2.26x 的加速。
- 在 LIBERO 基准上,成功率提升了 0.7%,并实现了 1.70x 的推理加速。
- 消融实验验证了对比学习目标、多级缓存设计和可学习门控机制的有效性。