一眼看懂
封面预览
针对 Vision-Language-Action (VLA) 模型在资源受限机器人平台上部署困难的问题,提出了首个以动作为中心的量化框架 Q…
- 针对 Vision-Language-Action (VLA) 模型在资源受限机器人平台上部署困难的问题,提出了首个以动作为中心的量化框架 Q…
- 指出现有的 LLM 量化方法忽略动作偏差累积导致的灾难性后果,无法直接应用于具身智能模型。
- 通过细粒度的 通道级位宽分配 策略,实现了模型压缩与剪枝的统一,大幅降低显存占用并保持控制精度。
Card 01
研究单位
研究单位
- 上海交通大学 (Shanghai Jiao Tong University)
- Anyverse Dynamics
- 中国科学院自动化研究所 (Institute of Automation, Chinese Academy of Sciences)
- 中国科学院大学 (University of Chinese Academy of Sciences)
- 蚂蚁集团 (Ant Group)
Card 02
论文概述
论文概述
- 针对 Vision-Language-Action (VLA) 模型在资源受限机器人平台上部署困难的问题,提出了首个以动作为中心的量化框架 QVLA。
- 指出现有的 LLM 量化方法忽略动作偏差累积导致的灾难性后果,无法直接应用于具身智能模型。
- 通过细粒度的 通道级位宽分配 策略,实现了模型压缩与剪枝的统一,大幅降低显存占用并保持控制精度。
Card 03
核心贡献
核心贡献
- 进行了首个针对 VLA 模型量化挑战的系统性分析,揭示了现有方法失效的原因及动作空间对齐的重要性。
- 提出了 QVLA 框架,利用动作空间敏感性指导位宽分配,统一了权重量化和剪枝(0-bit)过程。
- 在 OpenVLA 和 OpenVLA-OFT 基准模型上验证了方法的有效性,在同等平均位宽下显著优于 LLM 衍生的量化方法。
Card 04
方法描述
方法描述
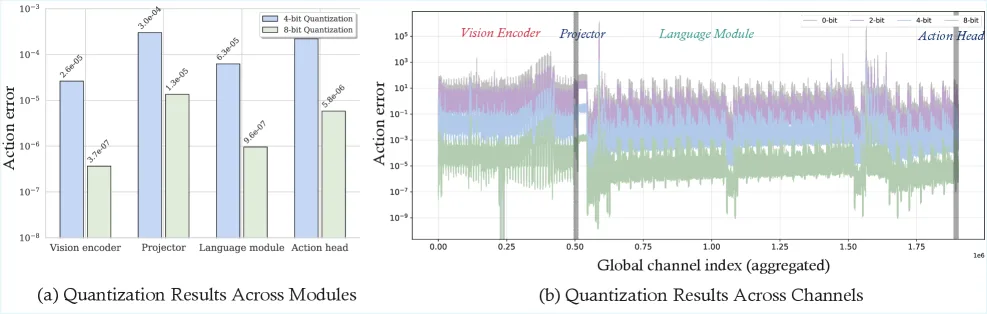
- 提出了一种基于 动作空间敏感性 的量化指标,直接衡量单个通道量化对最终动作输出的影响。
- 引入基于 泰勒级数展开 的一阶近似作为敏感性代理,高效识别关键通道,避免昂贵的穷举计算。
- 设计了 全局贪婪降级算法,从全精度开始逐步降低非敏感通道的位宽,实现受限预算下的最优位宽分配。
- 支持 混合精度 量化(支持 {0, 2, 4, 8, 16} 位),将 0-bit 视为通道剪枝,统一了压缩流程。
Card 05
数据集与资源
数据集与资源
- 使用 LIBERO 基准测试集,包含四个不同的机器人操作任务套件。
- 使用 OpenVLA 和 OpenVLA-OFT 作为基础模型(7B 参数量级)。
- 实验在 NVIDIA RTX 4090 GPUs 上进行。
- 真实世界任务使用 IMETA-Y1 双臂机器人系统进行验证。
Card 06
评估与结果
评估与结果
- 在 LIBERO 环境和真实世界任务中与 SmoothQuant、OmniQuant 和 AWQ 等方法进行对比。
- 主要评估指标包括任务成功率、显存占用和推理速度。
- 在 OpenVLA-OFT 模型上,量化版本仅需原始模型 29.2% 的显存,保持了 98.9% 的原始性能,并实现了 1.49× 的加速。
- 在 W4A4(4-bit权重,4-bit激活)设置下,QVLA 在 OpenVLA 上的性能下降仅为 0.5%,远优于 SmoothQuant 的 13.3% 下降。