一眼看懂
封面预览
论文提出 HMVLA(Hyperbolic Multimodal Fusion for Vision-Language-Action),一个利…
- 论文提出 HMVLA(Hyperbolic Multimodal Fusion for Vision-Language-Action),一个利…
- 旨在解决现有 VLA 模型直接微调预训练 VLM 时未能充分处理 VLA 领域语义对齐挑战的问题,特别是保留图像-文本数据中的层次结构
- 通过将多模态特征嵌入双曲空间,更有效地建模图像-文本数据中的层次关系,同时引入 MoE 机制增强多模态融合效果
Card 01
研究单位
研究单位
- 根据论文致谢部分,该研究由以下机构支持:中国国家自然科学基金委员会(Grant No. 62277011)、中国国家重点研发计划(Grant No. GG-2024-01-02)、重庆市MEITC项目(Grant No. YJX-2025001001009)以及广东省人工智能与数字经济(深圳)实验室开放研究基金(Grant No. GML-KF-24-18)
Card 02
论文概述
论文概述
- 论文提出 HMVLA(Hyperbolic Multimodal Fusion for Vision-Language-Action),一个利用双曲空间表示和稀疏门控专家混合机制增强视觉-语言语义对齐的 VLA 框架
- 旨在解决现有 VLA 模型直接微调预训练 VLM 时未能充分处理 VLA 领域语义对齐挑战的问题,特别是保留图像-文本数据中的层次结构
- 通过将多模态特征嵌入双曲空间,更有效地建模图像-文本数据中的层次关系,同时引入 MoE 机制增强多模态融合效果
Card 03
核心贡献
核心贡献
- 首次将双曲几何引入 VLA 领域,利用其结构特性在多模态融合过程中更好地保留层次关系
- 引入稀疏门控的 MoE 模块,通过路由机制自适应地将视觉和语言表示分配给不同专家,增强模态间对齐
- 在 LIBERO 基准数据集上进行了系统性验证,重构数据集以验证模型的跨域泛化能力
- 在任务准确率和泛化能力方面均优于现有最先进方法
Card 04
方法描述
方法描述
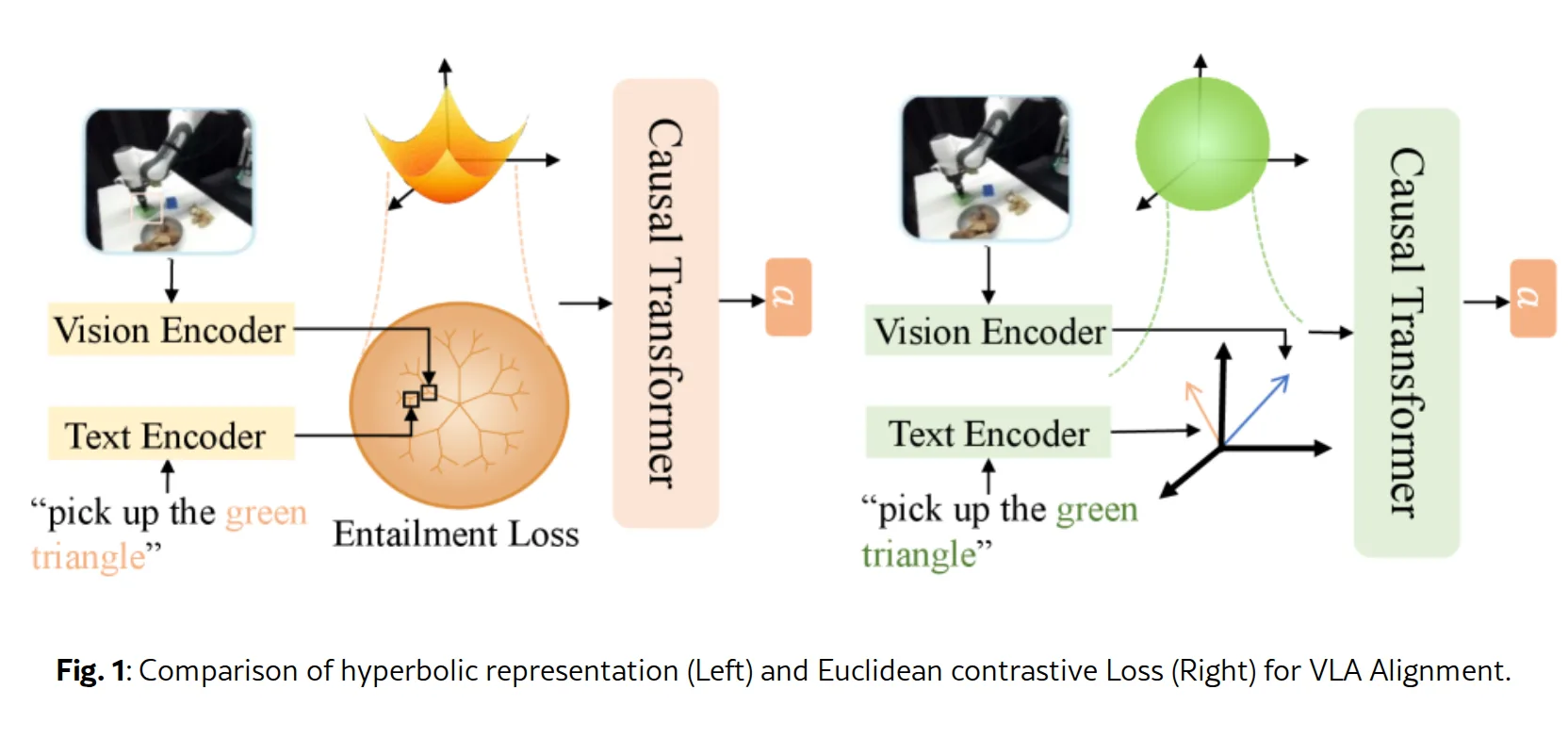
- 双曲语义对齐:基于 Lorentz 模型的双曲几何,将视觉和语言特征映射到双曲空间(超平面),利用指数和对数映射实现切空间与流形间的转换,并引入 entailment 损失约束层次依赖关系
- Soft MoE 多模态融合:用稀疏门控的专家混合模块替换 Q-Former 的前馈层,每个 token 通过门控网络计算权重后加权求和多个专家的输出,同时加入负载均衡损失确保专家平衡使用
- 使用 Dita 作为骨干网络,总损失函数结合对比损失、entailment 损失和任务损失
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO 基准数据集,包含 Spatial、Object、Goal、LONG 四个子集,以及重构的 Gen 数据集用于泛化验证
- 模型规模:使用 Dita 作为骨干网络,MoE 模块包含 6 个专家
- 训练配置:训练 80k 步,Adam 优化器,学习率 1×10^-4,双曲率 c=0.1,batch size 64,输入图像分辨率 256×256
- 轨迹参数:轨迹长度(traj_length)= 11,轨迹维度 = 7,每步预测 10 个未来动作
- 训练硬件:NVIDIA H200 GPU
Card 06
评估与结果
评估与结果
- 评估基准:LIBERO 基准数据集,与 DP、Octo、Tra-MoE、CoT-VLA、Dita 等先进方法对比
- 主要指标:任务级准确率
- 关键结果:
- HMVLA 在 Spatial、Object、Goal、LONG 四个子集上分别达到 90%、96%、89%、69%
- 平均准确率 86%,超越所有基线方法(最佳基线 Dita 为 82%)
- 消融实验验证了双曲空间、MoE 模块和 FiLM 条件机制各自对性能提升的贡献