一眼看懂
封面预览
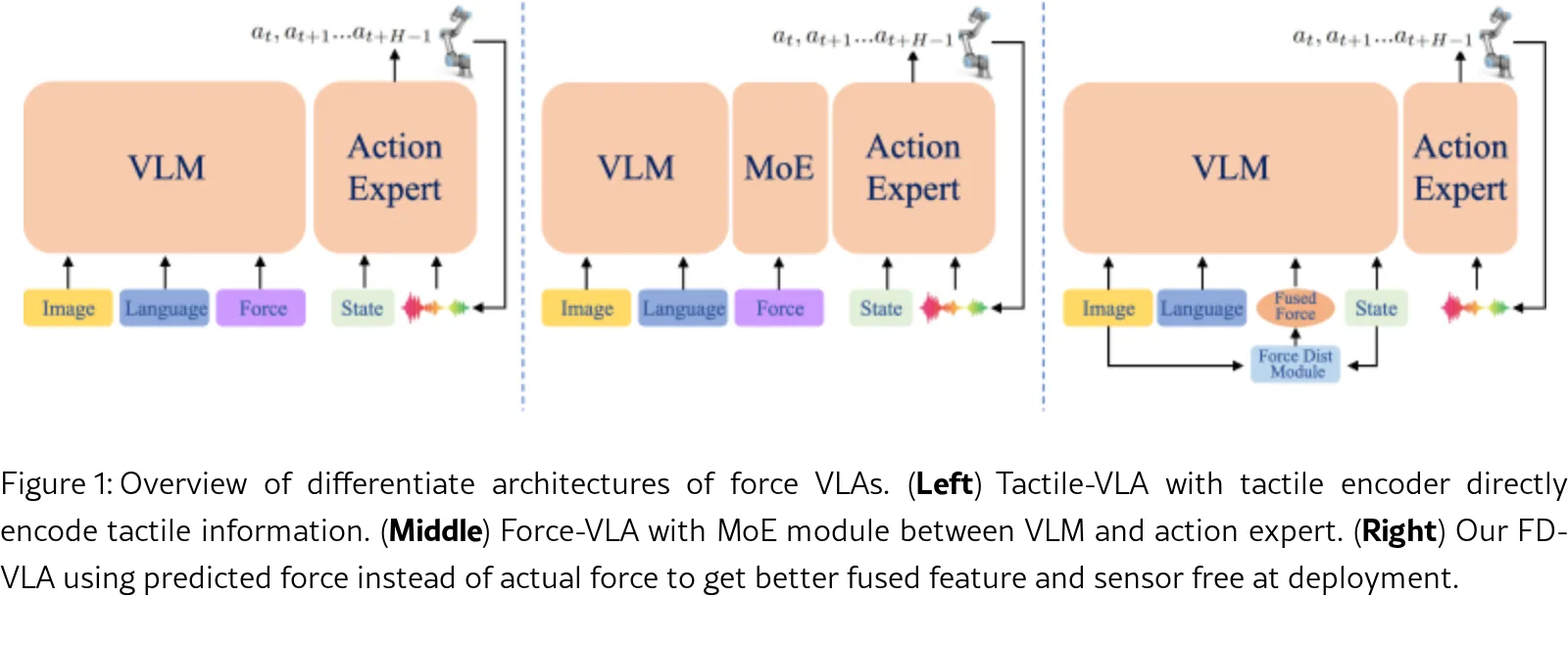
提出了 FD-VLA (Force-Distilled Vision-Language-Action) 框架,旨在解决接触丰富型机器人操作任务…
- 提出了 FD-VLA (Force-Distilled Vision-Language-Action) 框架,旨在解决接触丰富型机器人操作任务…
- 核心创新是通过一个 力量蒸馏模块 从视觉和机器人状态输入中预测潜在的力量表示,实现无需物理力量传感器的力量感知推理。
- 该框架允许在广泛缺乏昂贵或脆弱力传感器的机器人平台上部署,降低了硬件成本和复杂性。
Card 01
研究单位
研究单位
- 新加坡国立大学 (National University of Singapore)
- 新加坡科技研究局 (Agency for Science, Technology and Research, A*STAR)
- 南洋理工大学 (Nanyang Technological University)
- 东方理工学院 (Eastern Institute of Technology, Ningbo)
- 哈佛大学 (Harvard University)
Card 02
论文概述
论文概述
- 提出了 FD-VLA (Force-Distilled Vision-Language-Action) 框架,旨在解决接触丰富型机器人操作任务中对力量感知的需求。
- 核心创新是通过一个 力量蒸馏模块 从视觉和机器人状态输入中预测潜在的力量表示,实现无需物理力量传感器的力量感知推理。
- 该框架允许在广泛缺乏昂贵或脆弱力传感器的机器人平台上部署,降低了硬件成本和复杂性。
Card 03
核心贡献
核心贡献
- 提出了 FD-VLA 框架,将蒸馏后的力量标记注入到VLA模型中,以增强接触丰富型操作能力。
- 设计了 力量蒸馏模块,通过将可学习查询标记与视觉和状态输入结合,来预测潜在的力量标记。
- 该方法在无需物理传感器的情况下实现了力量感知推理,同时提供了额外的力-视觉-状态跨模态对齐。
Card 04
方法描述
方法描述
- 整体框架基于预训练的 SmolVLM-2 视觉语言模型,采用 SignLIP 损失作为感知主干。
- 核心模块 FDM 包含两个分支:预测分支和真实力量分支。训练时,预测分支通过注意力机制从视觉和状态嵌入中预测力量标记,并与由真实力量信号编码得到的标记进行对齐。
- 引入了 方向性注意力掩码机制,将视觉和语言标记作为冻结的感知流,将状态和力量标记作为控制流,在VLM内部实现单向信息流动,以保留预训练语义。
- 动作专家采用基于Transformer的策略头和 条件流匹配解码器 来生成动作序列。
Card 05
数据集与资源
数据集与资源
- 使用真实机器人平台 UR5e 收集数据。
- 数据采集设备包括 Azure Kinect 主摄像头和 RealSense D405 夹爪摄像头。
- 为每个接触丰富型任务(擦白板、按紧急按钮、插头插入)收集了 50个专家演示。
- 模型主干基于 SmolVLA。
Card 06
评估与结果
评估与结果
- 在三个真实世界接触丰富型任务上进行了评估:擦白板、按紧急按钮、插头插入。每个任务进行 30次独立试验。
- 与基线模型 DP3、π₀ 和 SmolVLA 进行对比,在有无力量输入的情况下均进行了评估。
- FD-VLA 取得了最高的平均成功率(61.1%),显著优于其他基线。其中,在擦白板任务上成功率达 73.3%。
- 消融实验表明,使用可学习令牌的FDM优于直接使用真实力量编码或无FDM的设置。
- 视觉泛化实验显示,模型在新背景和视觉扰动下保持了良好性能。