一眼看懂
封面预览
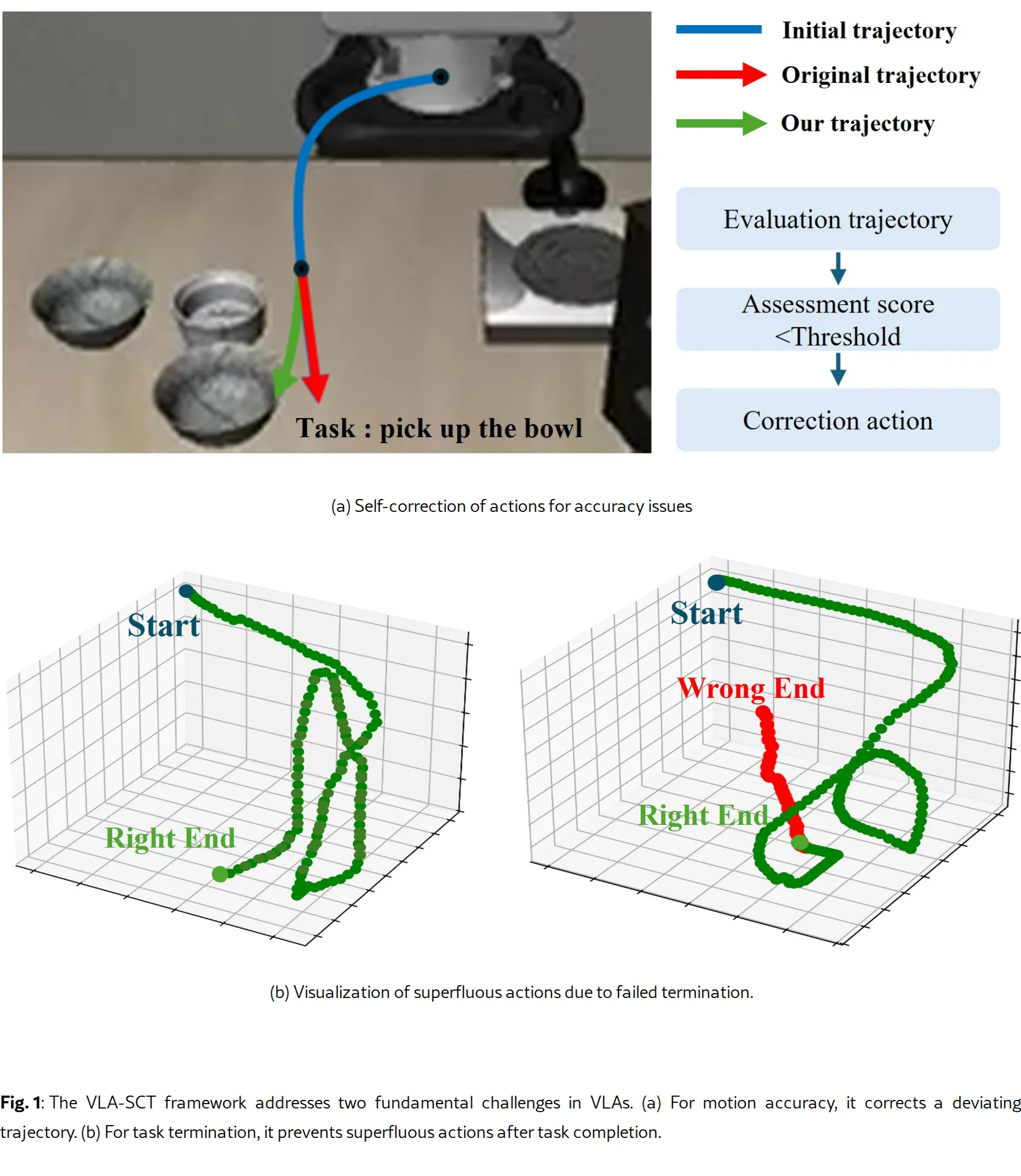
针对视觉-语言-动作(VLA)模型在精细操作任务中存在的“知识-行动”差距问题,即动作生成的空间偏差导致的抓取失败
- 针对视觉-语言-动作(VLA)模型在精细操作任务中存在的“知识-行动”差距问题,即动作生成的空间偏差导致的抓取失败
- 解决现有模型无法可靠识别任务完成状态,导致执行冗余动作和超时错误的问题
- 提出了一个轻量级、免训练的通用框架 VLA-SCT,通过自校正和终止检测机制增强 VLA 模型的鲁棒性和可靠性
Card 01
研究单位
研究单位
- 未在提供的文本片段中明确列出(文本中包含作者信息的部分可能已被截断)
Card 02
论文概述
论文概述
- 针对视觉-语言-动作(VLA)模型在精细操作任务中存在的“知识-行动”差距问题,即动作生成的空间偏差导致的抓取失败
- 解决现有模型无法可靠识别任务完成状态,导致执行冗余动作和超时错误的问题
- 提出了一个轻量级、免训练的通用框架 VLA-SCT,通过自校正和终止检测机制增强 VLA 模型的鲁棒性和可靠性
Card 03
核心贡献
核心贡献
- 提出了一个通用的、轻量级的 VLA-SCT 框架,作为模块化智能控制层增强现有的 VLA 模型,无需额外训练
- 设计了两种数据驱动机制:基于 局部加权矩估计 (LWME) 的在线自校准模块和基于视觉特征匹配的非参数终止决策模块
- 在 LIBERO 基准测试中取得了最高平均成功率,显著提升了精细操作任务的性能,并在提升准确率的同时保持了推理效率
Card 04
方法描述
方法描述
- 框架包含三个核心模块:轨迹评估、抓取扰动 和终止检测
- 轨迹评估:通过计算轨迹效率(基于曲率和挠率)、姿态稳定性(基于 SO(3) 流形测地距离)和运动平滑度(基于加加速度 Jerk)来预测任务失败风险
- 抓取扰动:使用 RBF 核 计算当前视觉特征与历史成功经验库的相似度权重,通过加权统计生成包含重力项和各向异性/各向同性噪声的结构化扰动,修正潜在失败的动作
- 终止检测:将当前相机图像与成功状态图像库进行对比,计算 Pearson 相关系数 作为相似度指标,当相似度超过阈值时发出停止信号
Card 05
数据集与资源
数据集与资源
- 使用 LIBERO 基准数据集进行实验评估
- 基线模型为 OpenVLA-7B,推理过程中模型权重冻结
- 实验硬件使用单张 NVIDIA RTX 4090 GPU,模型以 bfloat16 精度加载,占用约 15GB CUDA 显存
Card 06
评估与结果
评估与结果
- 在 LIBERO 基准的四个任务套件上进行评估,主要指标为任务成功率和推理加速比
- VLA-SCT 实现了 81.55% 的平均成功率,相较于 OpenVLA 基线(75.45%)绝对提升了 6.1%,并在所有任务类别中均表现最佳
- 框架在提升精度的同时实现了 1.12 倍 的推理加速,优于仅追求速度而牺牲精度的基线方法
- 消融实验验证了自校正模块和终止检测模块的有效性,两者结合能带来最大的性能提升;敏感度分析确定了最佳轨迹质量阈值为 0.75