一眼看懂
封面预览
论文旨在解决视觉-语言-动作模型在机器人操作任务中因高计算开销导致的部署延迟问题,核心目标是提升推理效率。
- 论文旨在解决视觉-语言-动作模型在机器人操作任务中因高计算开销导致的部署延迟问题,核心目标是提升推理效率。
- 提出LAC 框架,将推理加速问题重新表述为可学习的、任务感知的策略优化问题,通过动态决策过程直接集成到VLA模型中。
- 该方法解决了现有基于规则的静态加速策略无法适应动态场景变化且与任务目标解耦的关键问题。
Card 01
研究单位
研究单位
- 哈尔滨工业大学
- 哈尔滨工业大学(深圳)
- 美团机器人学院
- 中南大学
- 香港科技大学(广州)
Card 02
论文概述
论文概述
- 论文旨在解决视觉-语言-动作模型在机器人操作任务中因高计算开销导致的部署延迟问题,核心目标是提升推理效率。
- 提出LAC 框架,将推理加速问题重新表述为可学习的、任务感知的策略优化问题,通过动态决策过程直接集成到VLA模型中。
- 该方法解决了现有基于规则的静态加速策略无法适应动态场景变化且与任务目标解耦的关键问题。
Card 03
核心贡献
核心贡献
- 提出了首个用于VLA模型的可学习自适应缓存框架,将启发式加速转变为端到端的可训练策略。
- 设计了两个轻量级、协同工作的决策模块:缓存令牌选择器 和 缓存比例预测器,分别决定“哪些”和“多少”视觉令牌可以被复用。
- 在LIBERO、SIMPLER基准测试和真实机器人平台上进行了广泛实验,证明该方法在提升效率的同时还能改善任务性能。
Card 04
方法描述
方法描述
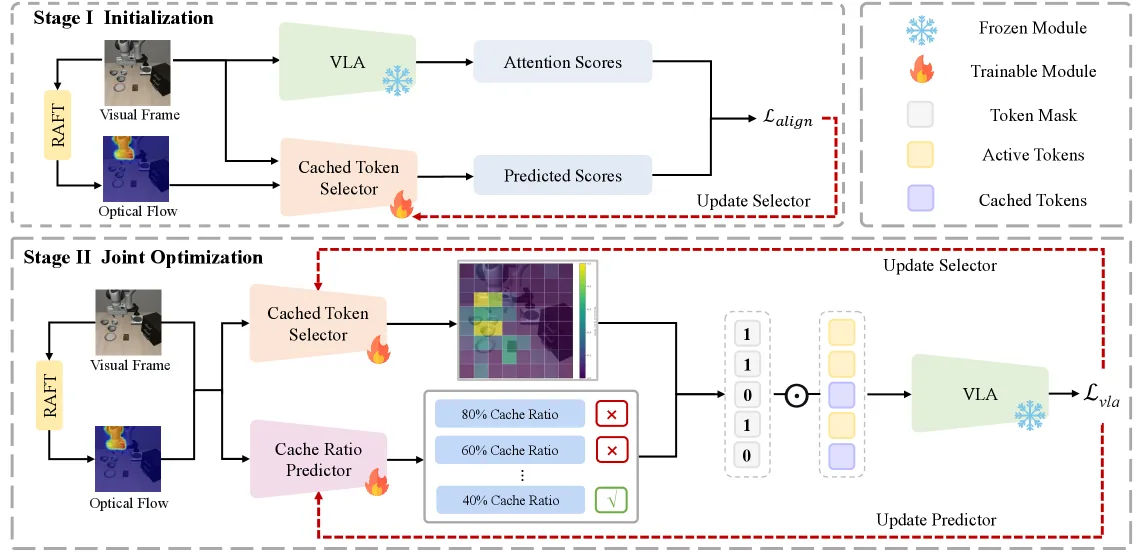
- 方法核心是将KV缓存技术扩展到视觉令牌的跨时间步复用,通过智能重用冗余的视觉信息来避免对每一帧进行密集计算。
- 创新点在于采用一个两阶段训练过程:第一阶段通过对齐VLA模型的注意力图来初始化选择器;第二阶段通过可微离散决策学习联合优化选择器和预测器。
- 利用轻量级的光流模型RAFT-small 提供运动信号,帮助模块识别动态场景变化,实现任务感知的自适应缓存。
Card 05
数据集与资源
数据集与资源
- 使用的数据集与基准包括:LIBERO 操纵基准测试、SIMPLER 模拟器、以及真实机器人操作任务。
- 基础模型为开源的OpenVLA 和 CogAct。
- 论文未明确报告模型参数量或训练所用的具体GPU/TPU资源。
Card 06
评估与结果
评估与结果
- 评估环境为模拟基准(LIBERO, SIMPLER)和Franka 物理机器人平台。
- 主要评估指标为:任务成功率、理论计算量FLOPs 和实际推理延迟 CUDA Time。
- 关键结果:在LIBERO上实现1.76× 实际推理加速,平均成功率从75.0%提升至76.9%;在真实世界任务上平均成功率比基线提高5.0个百分点,同时降低了计算开销。