一眼看懂
封面预览
研究解决 Latent Action Models (LAMs) 在存在动作相关干扰物时失败的问题,LAMs 无法区分可控制的变化与噪声
- 研究解决 Latent Action Models (LAMs) 在存在动作相关干扰物时失败的问题,LAMs 无法区分可控制的变化与噪声
- 提出利用 Vision-Language Models (VLMs) 的常识推理能力生成可提示表示(promptable representa…
- 在 Distracting MetaWorld 基准上验证,使用 VLM 可提示表示作为目标可将下游任务成功率提升高达 6 倍
Card 01
研究单位
研究单位
- 作者 affiliations 在 HTML 中未明确列出具体机构名称,仅列出作者姓名
Card 02
论文概述
论文概述
- 研究解决 Latent Action Models (LAMs) 在存在动作相关干扰物时失败的问题,LAMs 无法区分可控制的变化与噪声
- 提出利用 Vision-Language Models (VLMs) 的常识推理能力生成可提示表示(promptable representations),作为 LAM 训练的目标,从而在无监督方式下分离可控制特征与噪声
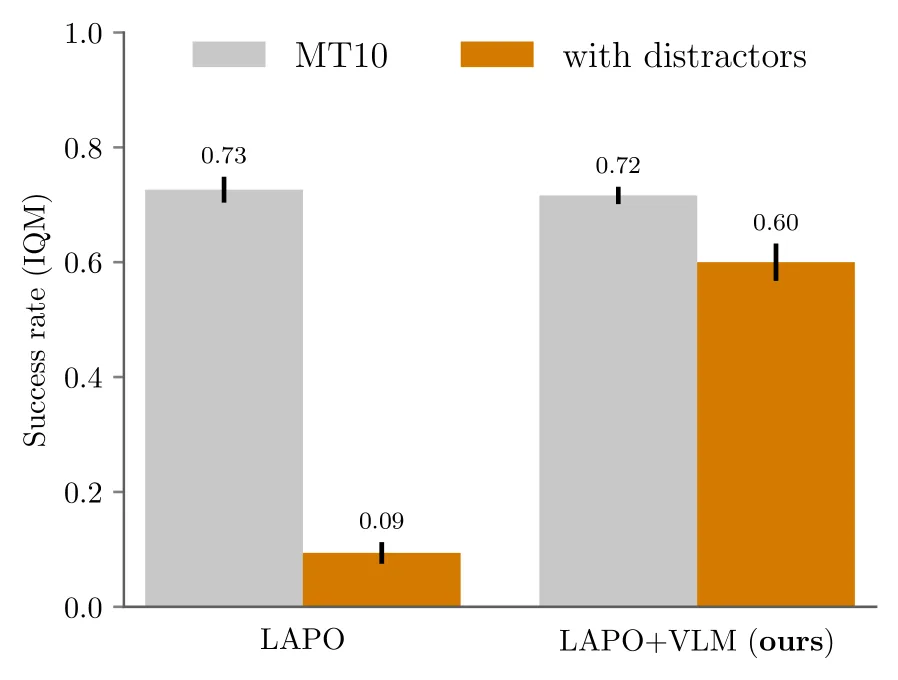
- 在 Distracting MetaWorld 基准上验证,使用 VLM 可提示表示作为目标可将下游任务成功率提升高达 6 倍
Card 03
核心贡献
核心贡献
- 发现并验证了 LAMs 在存在动作相关干扰物(如背景视频干扰)时完全失效的问题
- 提出利用 VLM 的可提示表示作为 FDM (Forward Dynamics Model) 的目标,实现无监督地过滤干扰物
- 进行了大规模基准测试(29,000+ 实验),评估了 25+ 种不同 VLM 的有效性,发现 Molmo 表现最佳
- 证明了语言条件化的重要性:VLM 方法显著优于 DINOv2 和 CLIP 等自监督方法
- 在无任何真实动作监督的情况下,使用 VLM 表示可将 latent action 质量提升到接近无干扰时的水平
Card 04
方法描述
方法描述
- 采用三阶段训练流程:(1) 预训练 LAM,(2) 在 latent actions 上训练行为克隆 (BC),(3) 使用少量真实动作标签训练解码器
- 使用 LAPO 架构(无量化),结合 IDM(逆动态模型)和 FDM(正向动态模型)
- 将 VLM 生成的语义表示作为 FDM 的预测目标,而非原始像素图像
- 使用多种提示策略,包括让 VLM 忽略背景、聚焦机械臂等任务相关特征
- 探索了不同 VLM 的 embedding 层选择、聚合策略(mean pooling 或 last token)等超参数
Card 05
数据集与资源
数据集与资源
- 数据集:MetaWorld Multi-Task 10 (MT10),修改版添加 DAVIS 视频作为背景干扰物
- 每个任务收集 5,000 条轨迹,仅使用 <1%(16 条)带真实动作标签的轨迹进行最终微调
- 评估了 25+ 种 VLM,包括:Molmo, InstructBLIP, Gemma-3, Llama-3.2, Qwen2.5-VL, InternVL3, Phi-4, LLaVA-OneVision, Pixtral, GraspMolmo 等
- 对比基线:LAPO(无干扰)、OTTER、UniVLA、DINOv2、CLIP
Card 06
评估与结果
评估与结果
- 评估指标:Action Probe(MSE,反映 latent actions 对真实动作的编码质量)和 Success Rate(任务成功率)
- 主要发现:
- 无干扰时 LAPO 表现良好,有干扰时成功率接近 0
- Molmo+VLM 在有干扰时成功率提升 6 倍
- Gemma-3 表现最差,InstructBLIP 优于较新的模型(如 Pixtral)
- 嵌入型 VLM(如 E5-V、VLM2Vec-V2)并未带来显著提升
- 语言条件化是关键:DINOv2 和 CLIP 表现最差,OTTER 使用 CLIP+text filtering 有所改善但仍不及 VLM
- 最佳配置:使用 "Do not describe background features. Focus on the robot arm" 类提示,聚合 next-to-last 层的 prompt embeddings