一眼看懂
封面预览
提出了 CARE 框架,一个用于机器人控制的潜在连续动作表示多任务预训练方法,旨在解决 VLA 模型依赖动作标注导致的可扩展性和泛化受限问题
- 提出了 CARE 框架,一个用于机器人控制的潜在连续动作表示多任务预训练方法,旨在解决 VLA 模型依赖动作标注导致的可扩展性和泛化受限问题
- 不同于现有方法需要大量动作标签进行预训练,CARE 仅使用视频-文本对学习潜在动作表示,通过新设计的多任务预训练目标实现
- 实验结果表明 CARE 在模拟任务中具有更高的成功率、语义可解释性,并能够避免捷径学习
Card 01
研究单位
研究单位
- 论文基于 Prismatic-7B VLM 架构构建,该架构整合了 SigLIP 和 DinoV2 视觉编码器
- 使用 Llama 7B 作为大语言模型骨干网络
- 预训练数据集包含:约 140k 机器人轨迹(Open X-Embodiment)和约 100k 人类活动视频片段(Something-Something v2)- 微调阶段使用 RT-1 数据集的 3% 均匀采样
Card 02
论文概述
论文概述
- 提出了 CARE 框架,一个用于机器人控制的潜在连续动作表示多任务预训练方法,旨在解决 VLA 模型依赖动作标注导致的可扩展性和泛化受限问题
- 不同于现有方法需要大量动作标签进行预训练,CARE 仅使用视频-文本对学习潜在动作表示,通过新设计的多任务预训练目标实现
- 实验结果表明 CARE 在模拟任务中具有更高的成功率、语义可解释性,并能够避免捷径学习
Card 03
核心贡献
核心贡献
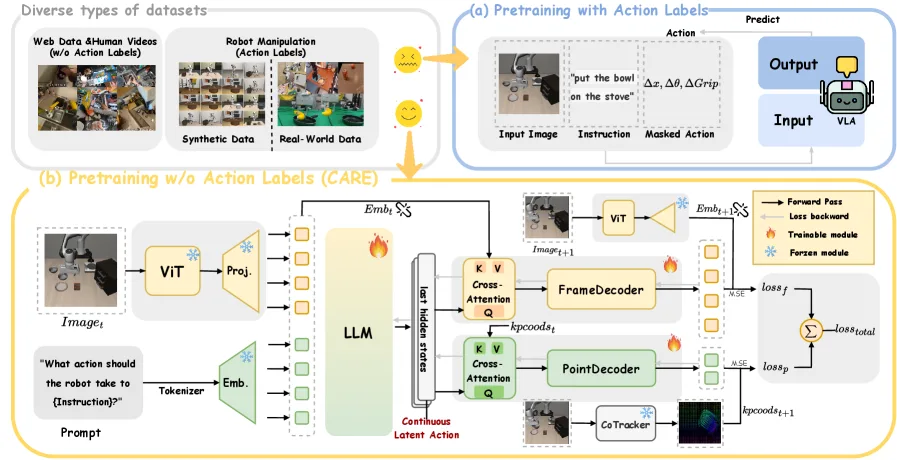
- 提出 CARE,一种无监督预训练策略,将潜在动作模型训练无缝集成到 VLM 预训练流程中,将 VLA 训练从四阶段减少到三阶段
- 引入基于关键点轨迹预测的多任务学习方法,丰富潜在动作表示,改善显式动作编码并减轻捷径学习问题
- 展示了在不使用动作标签的情况下进行预训练的优势,同时在模拟环境中取得优异性能
Card 04
方法描述
方法描述
- 架构:基于 Prismatic-7B VLM,包含双视觉编码器(SigLIP + DinoV2)、投影层和 7B 参数 Llama LLM
- 多任务学习:使用两个训练目标——帧预测(预测下一帧视觉特征)和关键点轨迹预测(使用 Co-Tracker 预测 256 个均匀分布点的运动)
- 潜在动作表示:将 VLM 输出中对应动作维度的隐藏状态作为连续潜在动作表示 z
- 损失函数:采用不确定性加权损失(UWL)自适应组合多个任务目标
- 微调阶段:使用 LoRA 微调并添加轻量级残差 MLP 作为动作头,回归真实动作值
Card 05
数据集与资源
数据集与资源
- 预训练数据:约 240k 轨迹/视频片段(机器人 + 人类视频)
- 微调数据:RT-1 数据集 3% 采样(约包含动作标签)
- 评估基准:LIBERO 基准,包含四个任务套件(Goal、Spatial、Object、Long)
- 模型规模:Prismatic-7B(7B 参数 LLM)
Card 06
评估与结果
评估与结果
- 评估环境:LIBERO 模拟器
- 主要指标:任务成功率(Success Rate, SR),越高越好
- 关键结果:
- CARE(human+Bridge+RT-1)达到 77.7% 平均成功率,超越使用动作标签的 OpenVLA(75.0%)
- 在 Goal 任务上领先 1.4%,在 Long 任务上领先 12.5%
- 显著超越无标签预训练方法 LAPA(64.3%)和 CoMo(69.2%)
- 可解释性:LP-MSE 最低(0.647),语义标签预测准确率最高(84.2%)
- 捷径学习:S-PCFC 分数最低(0.833),有效避免捷径学习