一眼看懂
封面预览
提出 DynamicVLA,一个用于动态物体操作(dynamic object manipulation)的视觉-语言-动作(Vision-L…
- 提出 DynamicVLA,一个用于动态物体操作(dynamic object manipulation)的视觉-语言-动作(Vision-L…
- 针对现有 VLA 模型在静态操作方面表现优秀,但在动态场景中因推理延迟导致感知与执行不同步的难题,提出三项关键技术设计
- 构建了 Dynamic Object Manipulation(DOM)基准,包含 200K 模拟场景 episodes 和 2K 真实世界…
Card 01
研究单位
研究单位
- S-Lab, Nanyang Technological University(南洋理工大学 S-Lab 实验室)
- 作者包括:Haozhe Xie(共同一作)、Beichen Wen(共同一作)、Jiarui Zheng、Zhaoxi Chen、Fangzhong Hong、Haiwen Diao、Ziwei Liu(通讯作者)
Card 02
论文概述
论文概述
- 提出 DynamicVLA,一个用于动态物体操作(dynamic object manipulation)的视觉-语言-动作(Vision-Language-Action, VLA)模型框架,旨在解决机器人在处理运动物体时面临的感知-执行延迟问题
- 针对现有 VLA 模型在静态操作方面表现优秀,但在动态场景中因推理延迟导致感知与执行不同步的难题,提出三项关键技术设计
- 构建了 Dynamic Object Manipulation(DOM)基准,包含 200K 模拟场景 episodes 和 2K 真实世界 episodes,填补了动态操作领域大规模数据集的空白
Card 03
核心贡献
核心贡献
- 紧凑的 0.4B 参数 VLA 模型:采用卷积视觉编码器(FastViT)进行高效空间压缩,使用 SmolLM2-360M 作为语言骨干,实现快速多模态推理
- 连续推理(Continuous Inference):通过流水线化执行方案重叠推理与动作执行,消除推理块之间的等待时间
- 潜在感知动作流(Latent-aware Action Streaming):通过丢弃过时动作并优先执行最新预测,解决推理延迟导致的时序对齐问题
- DOM 基准:首个专注于动态物体操作的大规模基准,包含自动数据收集管道,支持模拟和真实世界的多机器人平台
Card 04
方法描述
方法描述
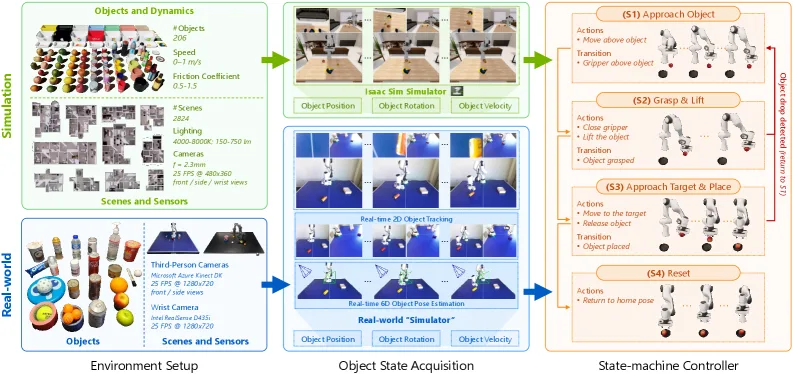
- 模型架构:0.4B 参数 VLA,包含 FastViT 视觉编码器 + SmolLM2-360M 语言骨干 + 基于扩散的动作专家(Flow Matching Transformer)
- 视觉编码器:采用 FastViT 进行高效空间压缩,输出 36 个视觉 tokens,比 Transformer 编码器延迟更低
- 连续推理机制:推理周期在前一个推理完成时立即触发,而非等待动作序列执行完毕(假设动作预测范围 n > 推理延迟 m)
- 潜在感知动作流:丢弃与当前时间步不对齐的旧动作,在动作块重叠时优先使用较新的动作预测
Card 05
数据集与资源
数据集与资源
- 模拟数据:Isaac Sim 环境中生成 200K episodes,涵盖 2.8K 场景、206 个物体(来自 Objaverse)
- 真实世界数据:2K episodes,使用双 RGB 视图进行 6D 物体姿态估计和速度推断,无需遥操作
- 测试基准:DOM 基准评估维度包括交互(Closed-loop Reactivity、Dynamic Adaptation、Long-horizon Sequencing)、感知(Visual Understanding、Spatial Reasoning、Motion Perception)和泛化(Visual Generalization、Motion Generalization、Disturbance Robustness)
- 评估环境:Franka Emika Panda(模拟+真实)、AgileX PiPER(真实)
Card 06
评估与结果
评估与结果
- 模拟环境:DynamicVLA 在平均成功率(47.06%)上显著优于所有基线方法,比最强基线(VLA-Adapter-Pro 的 13.61%)提升超过 188%
- 交互能力:Closed-loop Reactivity 60.5%、Dynamic Adaptation 38.5%、Long-horizon Sequencing 40.5%
- 消融实验:验证了 360M 语言模型容量最优、FastViT 编码器优势、连续推理和潜在感知动作流的互补作用
- 推理效率:路径长度 2.50m、任务完成时间 8.53s(均优于基线)
- 实际部署:在真实世界实验中,DynamicVLA 达到 51.9% 成功率,显著超过基线的 11.7%