一眼看懂
封面预览
提出了一种监督式专家混合(MoE)架构,用于相位结构的手术操作任务,可集成到任何动作分块Transformer策略中
- 提出了一种监督式专家混合(MoE)架构,用于相位结构的手术操作任务,可集成到任何动作分块Transformer策略中
- 在仅使用立体内窥镜图像(无需腕部摄像头或多视角设置)的情况下,从少于150个演示样本学习复杂的长程操作任务
- 任务聚焦于腹腔镜肠道抓取和回缩的协作手术场景,机器人作为智能助手执行辅助任务
Card 01
研究单位
研究单位
- NCT - National Center for Tumor Diseases, Dresden, Germany
- Medical Faculty of TU Dresden, Germany
- Karlsruhe Institute of Technology (KIT), Germany
- Authors include researchers from Surgical Robotics, Intuitive Clinical Engineering, and Computer-Assisted Medicine departments
Card 02
论文概述
论文概述
- 提出了一种监督式专家混合(MoE)架构,用于相位结构的手术操作任务,可集成到任何动作分块Transformer策略中
- 在仅使用立体内窥镜图像(无需腕部摄像头或多视角设置)的情况下,从少于150个演示样本学习复杂的长程操作任务
- 任务聚焦于腹腔镜肠道抓取和回缩的协作手术场景,机器人作为智能助手执行辅助任务
Card 03
核心贡献
核心贡献
- 监督式MoE架构:提出新颖的监督式专家混合架构,利用手术任务的相位结构,通过阶段标签监督门控网络,确保专家稳定收敛和功能专业化
- 新型手术协作任务:引入外科医生-机器人协作任务,在肠道回缩中实现人机协作,机器人解读外科医生视觉线索并执行精确抓取和持续回缩
- VLA模型局限性验证:实验证明通用VLA模型(π0.5、SmolVLA)在数据稀缺条件下完全无法完成手术任务
- 零样本迁移能力:在仅使用幻象数据训练的情况下,策略在离体猪组织上达到80%成功率,验证了向真实组织迁移的可行性
- 视角泛化能力:通过随机视角训练,策略可泛化到未见过的相机角度,展示了隐式3D场景理解能力
Card 04
方法描述
方法描述
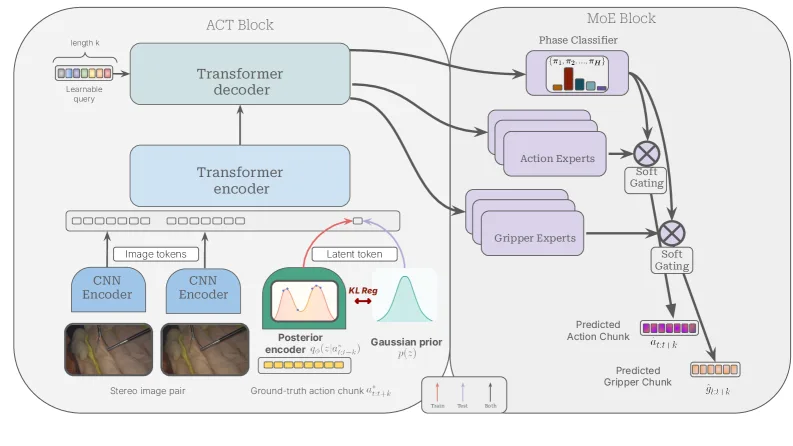
- 基础策略:采用Action Chunking Transformer (ACT)作为轻量级动作解码策略,基于变分框架进行训练
- MoE模块:包含H个并行专家(每个相位一个),由动作专家、夹爪专家和门控网络组成
- 监督机制:通过相位交叉熵损失直接监督门控网络,将相位预测作为辅助任务引导专家专业化
- 观察空间:仅使用立体内窥镜图像对,不包含本体感知数据,实现纯视觉策略
- 动作空间:包含k个连续动作块(delta movement)和二进制夹爪动作
- 训练目标:结合动作重建损失(L1)、相位交叉熵损失、夹爪二元交叉熵损失和KL散度正则化
Card 05
数据集与资源
数据集与资源
- 数据集:固定视角数据集120个回合 + 随机视角数据集50个回合,手术任务分为5个阶段(Idle、Approach & Grasp、Hold、Retract、Maintain Tension)
- 模型规模:ACT + MoE: 5330万参数;标准ACT: 5200万参数;π0.5: 40亿参数;SmolVLA: 2.4亿参数
- 训练资源:单个RTX A5000 GPU(ACT和MoE-ACT训练3小时);π0.5需A100 GPU训练8小时
- 硬件平台:使用OpenHELP开放体腔幻象,两台UR5e机械臂,立体TIPCAM1 S 3D内镜
Card 06
评估与结果
评估与结果
- 评估环境:OpenHELP幻象环境 + 离体猪肠道组织 + 初步活体猪手术实验
- 主要指标:分阶段成功率(Reaching、Grasping、Retracting)和端到端成功率
- 关键结果:
- 分布内测试:ACT + MoE达到85%端到端成功率,显著优于标准ACT的50%和VLA模型的0%
- 分布外测试:MoE-ACT在Novel grasp、Low illumination、Partial occlusion条件下保持13/20成功率
- 离体零样本:12/15成功率(80%),无需额外训练
- 随机视角测试:18/22成功率(82%),验证视角泛化能力
- 推理速度:ACT + MoE维持27 Hz实时推理,显著优于VLA模型(π0.5: 10 Hz, SmolVLA: 3.3 Hz)