一眼看懂
封面预览
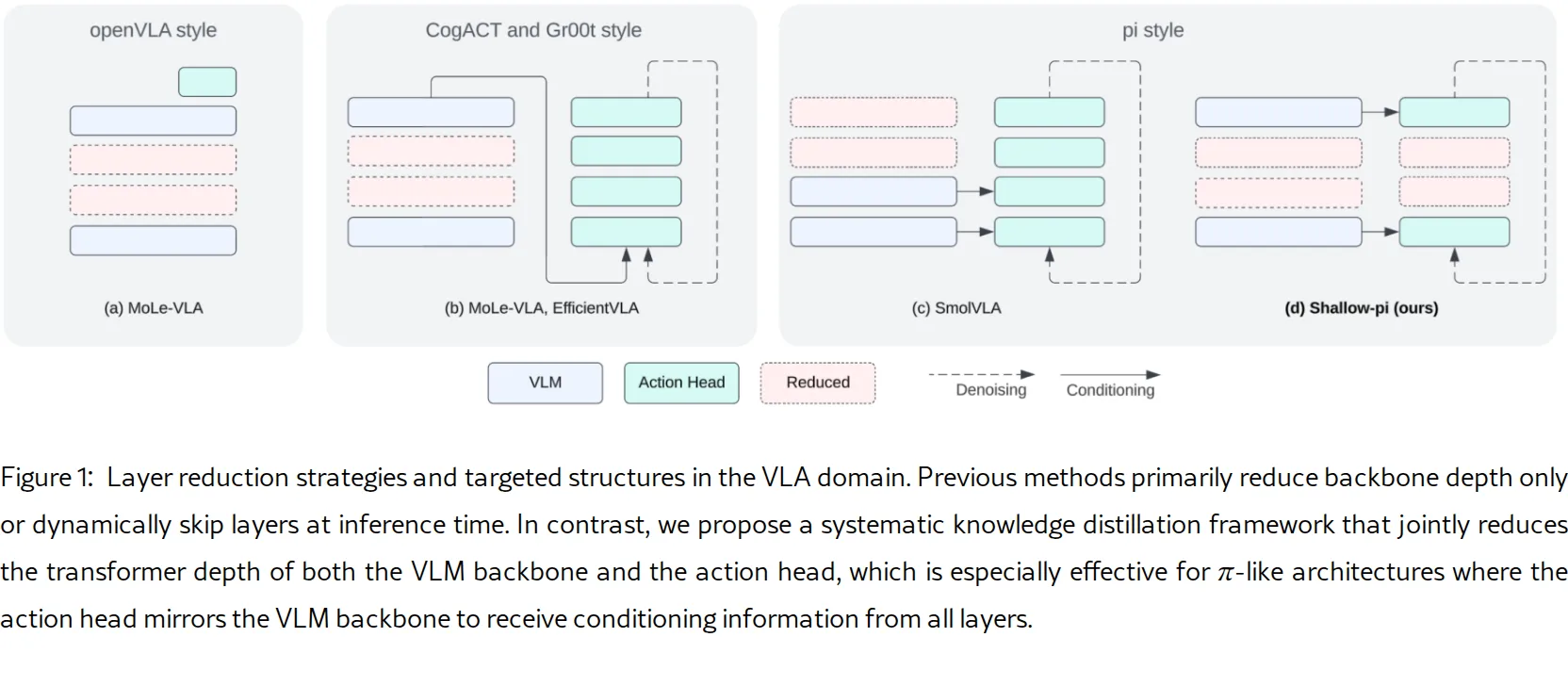
提出了 Shallow-π 知识蒸馏框架,用于压缩基于流(flow-based)的视觉-语言-动作(VLA)模型的 Transformer 深度
- 提出了 Shallow-π 知识蒸馏框架,用于压缩基于流(flow-based)的视觉-语言-动作(VLA)模型的 Transformer 深度
- 核心目标是解决 VLA 模型在边缘设备上的实时推理延迟问题,同时保持高成功率
- 通过知识蒸馏将模型从 18 层压缩至 6 层,实现超过 2 倍 的推理加速,成功率仅下降不足 1%
Card 01
研究单位
研究单位
- Samsung Research(三星研究院),韩国
- 作者:Boseong Jeon、Yunho Choi、Taehan Kim
Card 02
论文概述
论文概述
- 提出了 Shallow-π 知识蒸馏框架,用于压缩基于流(flow-based)的视觉-语言-动作(VLA)模型的 Transformer 深度
- 核心目标是解决 VLA 模型在边缘设备上的实时推理延迟问题,同时保持高成功率
- 通过知识蒸馏将模型从 18 层压缩至 6 层,实现超过 2 倍 的推理加速,成功率仅下降不足 1%
Card 03
核心贡献
核心贡献
- 开发了首个针对 π 类流式 VLA 模型的知识蒸馏框架,同时压缩 VLM 主干网络和动作头的 Transformer 深度
- 设计了三种互补的蒸馏目标:任务损失(L_task)、知识蒸馏损失(L_kd)和注意力蒸馏损失(L_attn)
- 创新性地在中间 Transformer 层应用注意力蒸馏,对齐动作查询与视觉-语言键值对之间的跨注意力分布
- 在 Jetson Orin 和 Jetson Thor 边缘设备上验证了方法在复杂动态操作任务中的有效性
Card 04
方法描述
方法描述
- 学生模型初始化:采用 TinyBERT 风格的均匀采样策略,从教师模型中均匀选取层来初始化浅层学生模型
- 任务损失:标准流匹配损失,监督学生预测真实目标速度
- 知识蒸馏损失:让学生预测的流场匹配教师的输出
- 注意力蒸馏损失:仅对动作 token 进行注意力对齐(而非所有 token),在中间层应用 KL 散度对齐跨注意力分布
- 实验表明,仅对动作 token 进行注意力蒸馏效果最佳,对所有 token 进行蒸馏会导致训练不稳定
Card 05
数据集与资源
数据集与资源
- 模拟基准:LIBERO(包含 Spatial、Object、Goal、Long 10 四个子集)
- 真实机器人平台:ALOHA(双臂移动机器人)、RB-Y1(人形机器人)
- 边缘计算设备:Jetson Orin、Jetson Thor
- 教师模型:π₀ 和 π₀.5(基于 Flow Matching 的 VLA 模型)
- 训练配置:批大小 64-128,训练步数 30K-100K
Card 06
评估与结果
评估与结果
- 模拟环境:Shallow-π₀.₅-L6 在 LIBERO 上平均成功率达 95%,FLOPs 降至 1.30T,CUDA 推理时间降至 11.3ms
- 真实机器人实验:在 ALOHA 平台上,推理延迟从 364ms 降至 110ms(约 6 帧),动态任务成功率显著优于教师模型和 SmolVLA
- 消融实验:组合损失(任务+蒸馏+注意力)在 6 层配置下达到 94.6% 成功率;中间层注意力蒸馏效果优于初始层和最终层
- 泛化能力:在未见的空间扰动场景下(目标位置偏移 3-10cm),浅层模型因更快的观察更新频率而表现更好